如何调用openai的TTS模型
这是24年1月份写的了,调用代码大概率有变动,仅供参考。
1 什么是OpenAI的TTS模型
OpenAI的TTS模型是一种文本到语音(Text-to-Speech)模型,它可以将给定的文本转换为自然语音音频。TTS代表Text-to-Speech,是一种人工智能技术,它使计算机能够模拟自然语言的声音,从而实现文本的朗读。
在OpenAI的TTS模型中,用户可以选择不同的声音(Voice)和模型类型(Model),以定制生成语音的效果。声音可以是男声或女声,而模型类型可以选择不同的版本,如"tts-1"或"tts-1-hd",以满足不同的需求。
"tts-1":
- "tts-1"是OpenAI TTS的基本版本。
- 相对较小的模型,适用于一般的文本到语音转换任务。
- 生成的语音质量较好,但可能在某些情况下缺少一些细节。
"tts-1-hd":
- "tts-1-hd"是"tts-1"的高清版本,具有更高的模型容量和更多的参数。
- 更大的模型容量通常意味着能够更好地捕捉文本中的复杂结构和音频细节。
- 适用于对语音质量有更高要求的场景,如音频合成、语音应用等。
选择使用哪个版本通常取决于任务的要求和对语音质量的期望。如果对生成语音的质量要求较高,可能会选择使用"tts-1-hd",而对于一般应用,"tts-1"也提供了良好的性能。在实际使用中,可以尝试两个版本并比较它们在特定任务上的效果。
2 api收费情况
- $0.015/0.03 per 1,000 input characters,即1000字符0.015美元。
3 如何使用OpenAI的TTS模型
使用OpenAI的TTS模型需要通过API进行调用。以下是使用OpenAI的TTS模型的基本步骤:
该库需要在全局魔法上网环境下使用,若出现connect error类报错,就是节点问题
3.1 步骤:
3.1.1 获取OpenAI API密钥
在使用TTS模型之前,需要获得OpenAI的API密钥。API密钥是用于身份验证的关键信息。具体获取方式请自行查阅。
3.1.2 安装OpenAI Python库
使用Python脚本调用OpenAI的API,需要安装OpenAI的Python库。可以使用以下命令进行安装:
pip install openai
pip install openai -i https://pypi.tuna.tsinghua.edu.cn/simple # 清华镜像安装,二者任选其一即可。
3.1.3 编写Python脚本
编写Python脚本,导入所需的库(如openai、pathlib等),并配置OpenAI的API密钥。
from pathlib import Path
from openai import OpenAI # 要求openai库版本1.0以上
# 配置OpenAI的API密钥
client = OpenAI(api_key="your_api_key")
# 设置文件路径
speech_file_path = Path(__file__).parent / "speech.mp3"
3.1.4 使用TTS模型生成语音
在脚本中调用OpenAI的TTS模型,指定模型类型、声音类型和输入文本,然后将生成的语音保存到文件。
# 调用OpenAI的TTS模型
response = client.audio.speech.create(
model="tts-1-hd", # 模型选择
voice="echo", # 不同语音模式选择
input="你好,世界!" # 生成内容选择
)
# 将生成的语音保存到文件
response.stream_to_file(speech_file_path)
3.1.5 不同的语音模式(voice option)
ChatGPT 在OpenAI的TTS-1模型中,Alloy、Echo、Fable、Onyx、Nova和Shimmer代表不同的语音模式或声音类型。每种语音模式都具有独特的音质、音调和语音特点。以下是对这六种语音模式的简要介绍:
Alloy(合金):
- Alloy 是一种女声语音模式。
- 声音可能具有音乐感,适用于一般性的语音合成任务。
Echo(回声):
- Echo 是一种男声语音模式。
- 可能具有较深的音调,适用于需要男声的场景。
Fable(寓言):
- Fable 是一种语音模式,具有独特的声音特点。
- 可能呈现出富有魅力和讲故事感的音质。
Onyx(黑玛瑙):
- Onyx 是一种语音模式,可能具有深沉和富有表现力的音质。
- 适用于需要更加庄重和深情的场景。
Nova(新星):
- Nova 是一种语音模式,可能呈现出明亮、清晰和生动的音质。
- 适用于需要更加活泼和清晰的语音的场景。
Shimmer(闪光):
- Shimmer 是一种语音模式,可能具有更加明亮和闪耀的音质。
- 适用于需要更加活泼和轻松的场景。
3.1.6 配置
3.1.6.1 法一 配置代理后,再开代理软件
_base_client.pyps:这个文件我忘了在哪了,应该在opneai这个包里。
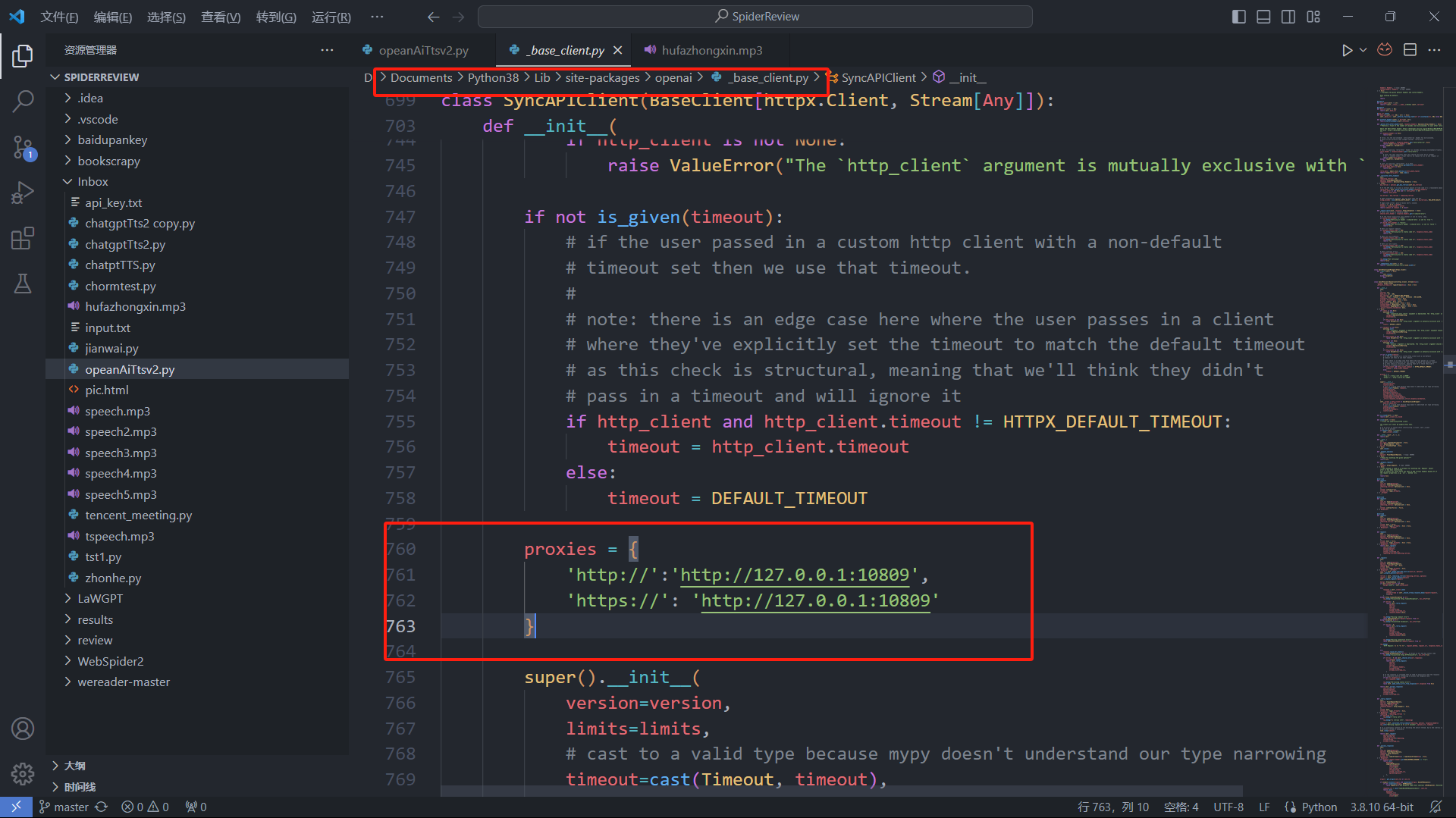
proxies = {
'http://':'http://127.0.0.1:端口',
'https://': 'http://127.0.0.1:端口'
}
3.1.6.2 法二 开全局代理(必须是tun模式,i.e 改网卡的那种)
3.1.7 运行脚本
运行编写好的Python脚本,根据需要提供相应的命令行参数,如API密钥、模型类型、声音类型和输入文本。
也可以在ide中直接运行,不用按照如下方式
python your_script.py --api_key="your_api_key" --model="tts-1-hd" --voice="echo" --input_text="你好,世界!"
3.1.8 完整代码
from pathlib import Path
from openai import OpenAI
client = OpenAI(api_key="your_api_key") # 此处属于你的api
speech_file_path = Path(__file__).parent / "speech.mp3" # 设置文件路径
response = client.audio.speech.create(
model="tts-1",
voice="alloy",
input="Today is a wonderful day to build something people love!"
) # 生成的文本内容,支持中文
response.stream_to_file(speech_file_path)
如何调用openai的TTS模型的更多相关文章
- 使用C++调用并部署pytorch模型
1.背景(Background) 上图显示了目前深度学习模型在生产环境中的方法,本文仅探讨如何部署pytorch模型! 至于为什么要用C++调用pytorch模型,其目的在于:使用C++及多线程可以加 ...
- matlab调用keras深度学习模型(环境搭建)
matlab没有直接调用tensorflow模型的接口,但是有调用keras模型的接口,而keras又是tensorflow的高级封装版本,所以就研究一下这个……可以将model-based方法和le ...
- Android实例-调用GOOGLE的TTS实现文字转语音(XE7+小米2)(无图)
注意:在手机上必须选安装文字转语音引擎“google Text To Speech”地址:http://www.shouji56.com/soft/GoogleWenZiZhuanYuYinYinQi ...
- phpcms调用指定文章内容模型的ID
一.使用GET调用Phpcms V9指定id页面数据方法 {pc:get sql="SELECT * FROM cmsyou_news WHERE id='55'" cache=& ...
- 调用GOOGLE的TTS实现文字转语音(XE7+小米2)(XE10.1+小米5)
相关资料: 注意:在手机上必须选安装文字转语音引擎“google Text To Speech”地址:http://www.shouji56.com/soft/GoogleWenZiZhuanYuYi ...
- Android实例-调用GOOGLE的TTS实现文字转语音(XE7+小米2)(XE10.1+小米5)
相关资料: 注意:在手机上必须选安装文字转语音引擎“google Text To Speech”地址:http://www.shouji56.com/soft/GoogleWenZiZhuanYuYi ...
- 配置django的环境实现外部脚本调用django中的模型类
通过导入os模块,os设置django的settings文件,配置好django项目的环境,然后执行django.set_up()使环境生效,然后就可以导入模型类,使用增删改查
- tensorflow C++接口调用目标检测pb模型代码
#include <iostream> #include "tensorflow/cc/ops/const_op.h" #include "tensorflo ...
- PyTorch Hub发布!一行代码调用最潮模型,图灵奖得主强推
为了调用各种经典机器学习模型,今后你不必重复造轮子了. 刚刚,Facebook宣布推出PyTorch Hub,一个包含计算机视觉.自然语言处理领域的诸多经典模型的聚合中心,让你调用起来更方便. 有多方 ...
- 使用VS+OpenCV调用深度学习模型
最近项目有个任务,要在windows环境下用VS+OpenCV实现caffe模型的调用,于是在网上找了几个相关的博客跑了几个demo练练手.这些博客写得都很详细,但是有些细节由于版本更新的问题,配置的 ...
随机推荐
- ubuntu16.04 python2&3 pip升级后报错:sys.stderr.write(f"ERROR: {exc}")
ubuntu16.04 python2&3 pip升级后报错: sys.stderr.write(f"ERROR: {exc}") 描述 最近使用ubuntu16.04上的 ...
- Yaml配置文件语法详解
YAML 简介 YAML,即 "YAML Ain't a Markup Language"(YAML 不是一种标记语言)的递归缩写,YAML 意思其实是" Yet Ano ...
- HTTP 和 HTTPS,为什么HTTPS安全?
HTTP协议通常承载与 TCP协议之上,在HTTP和TCP之间添加一个安全协议层(SSL或TSL),这个时候,就成了我们常说的HTTPS 默认HTTP的端口号为80,HTTPS的端口号为443 因为网 ...
- redis基本数据结构-有序集合
redis基本数据结构-有序集合zset 特性 使用哈希表+跳表数据结构存储 每个元素由 分数和字段名 两部分组成 增加元素 zadd key score1 member1 [score2 membe ...
- 10 pdf分享失败
PC端分享pdf,复制粘贴pdf链接后跳转搜索首页
- [oeasy]python0053_ 续行符_line_continuation_python行尾续行
续行符与三引号 回忆上次内容 上次还是转义序列 类型 英文 符号 \a bell 响铃 \b backspace 退格 \t tab 水平制表符 \v vertical tab 垂直制表符换行不回车 ...
- vue进阶一~数据响应式,数据响应到视图层,手写v-model,订阅发布者模式,
1,数据响应式 当数据发生改变的时候,我们立即知道数据发生改变,并做出相关的操作:发送请求,打印文字,操作DOM等. 1.1,vue实现数据响应的原理 vue中使用了两种模式来实现数据响应式,分别是v ...
- Python Kafka客户端confluent-kafka学习总结
实践环境 Python 3.6.2 confluent-kafka 2.2.0 confluent-kafka简介 Confluent在GitHub上开发和维护的confluent-kafka-pyt ...
- RPA+ddddocr识别图片验证码
上篇我们已经使用python识别了验证码,接下来用RPA接收python识别验证码结果进行登录 1.RPA首先安装python包 ddddocr 2.RPA新建一个python模块 编写代码 impo ...
- 【Hibernate】Re03 注解方式实现
使用JPA规范提供的注解即可实现,这样的好处是不需要配置Entity.hbm.xml文件了 但是考虑到多表查询的情况,还是会有xml配置的需要. 一.常用的JPA注解: 1.public @inter ...