spark 怎么读写 elasticsearch
参考文章:
- https://www.bmc.com/blogs/spark-elasticsearch-hadoop/
- https://blog.pythian.com/updating-elasticsearch-indexes-spark/
- https://qbox.io/blog/elasticsearch-in-apache-spark-python 这里有 RDD level 的写法,有些操作比如count, aggregation 在 DataFrame/DataSet level 不支持pushdown, 所有需要用到RDD level 的写法
Pre-requisite:
先装上 elasticsearch-hadoop 包
Step-by-Step guide
1. 先在ES创建3个document
[mshuai@node1 ~]$ curl -XPUT --header 'Content-Type: application/json' http://your_ip:your_port/school/doc/1 -d '{
"school" : "Clemson"
}'
[mshuai@node1 ~]$ curl -XPUT --header 'Content-Type: application/json' http://your_ip:your_port/school/doc/2 -d '{
"school" : "Harvard"
}'
2. Spark 里面去读,这里是pyspark 代码
reader = spark.read.format("org.elasticsearch.spark.sql").option("es.read.metadata", "true").option("es.nodes.wan.only","true").option("es.port","your_port").option("es.net.ssl","false").option("es.nodes", "your_ip")
df = reader.load("school")
df.show()
输出这个格式的信息
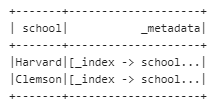
3. 接下来尝试update 一个记录,先得到一个要改的id
hot = df.filter(df["school"] == 'Harvard') \
.select(expr("_metadata._id as id")).withColumn('hot', lit(True))
hot.show()

4. 先来加一列
esconf={}
esconf["es.mapping.id"] = "id"
esconf["es.mapping.exclude"]='id'
esconf["es.nodes"] = "your_ip"
esconf["es.port"] = "your_port"
esconf["es.write.operation"] = "update"
esconf["es.nodes.discovery"] = "false"
esconf["es.nodes.wan.only"] = "true"
hot.write.format("org.elasticsearch.spark.sql").options(**esconf).mode("append").save("school/doc")
看,成功加了 hot 列,满足条件的记录赋了对应的值
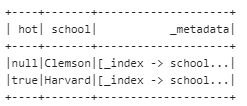
5. 又来update已经存在的信息
esconf={}
esconf["es.mapping.id"] = "id"
esconf["es.nodes"] = "your_ip"
esconf["es.port"] = "your_port"
esconf["es.update.script.inline"] = "ctx._source.school = params.school"
esconf["es.update.script.params"] = "school:<SCU>"
esconf["es.write.operation"] = "update"
esconf["es.nodes.discovery"] = "false"
esconf["es.nodes.wan.only"] = "true"
hot.write.format("org.elasticsearch.spark.sql").options(**esconf).mode("append").save("school/doc")
reader.load("school").show()
嗯。。。成功把Harvard改成了川大
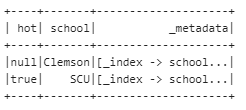
另外,怎么upload attachment 到ES呢?可以用这个plugin Ingest Attachment Processor Plugin
END
spark 怎么读写 elasticsearch的更多相关文章
- 如何在spark中读写cassandra数据 ---- 分布式计算框架spark学习之六
由于预处理的数据都存储在cassandra里面,所以想要用spark进行数据分析的话,需要读取cassandra数据,并把分析结果也一并存回到cassandra:因此需要研究一下spark如何读写ca ...
- 【原创】大叔经验分享(26)hive通过外部表读写elasticsearch数据
hive通过外部表读写elasticsearch数据,和读写hbase数据差不多,差别是需要下载elasticsearch-hadoop-hive-6.6.2.jar,然后使用其中的EsStorage ...
- spark DataFrame 读写和保存数据
一.读写Parquet(DataFrame) Spark SQL可以支持Parquet.JSON.Hive等数据源,并且可以通过JDBC连接外部数据源.前面的介绍中,我们已经涉及到了JSON.文本格式 ...
- spark block读写流程分析
之前分析了spark任务提交以及计算的流程,本文将分析在计算过程中数据的读写过程.我们知道:spark抽象出了RDD,在物理上RDD通常由多个Partition组成,一个partition对应一个bl ...
- 6.3 使用Spark SQL读写数据库
Spark SQL可以支持Parquet.JSON.Hive等数据源,并且可以通过JDBC连接外部数据源 一.通过JDBC连接数据库 1.准备工作 ubuntu安装mysql教程 在Linux中启动M ...
- kafka spark steam 写入elasticsearch的部分问题
应用版本 elasticsearch 5.5 spark 2.2.0 hadoop 2.7 依赖包版本 docker cp /Users/cclient/.ivy2/cache/org.elastic ...
- Spark SQL读写方法
一.DataFrame:有列名的RDD 首先,我们知道SparkSQL的目的是用sql语句去操作RDD,和Hive类似.SparkSQL的核心结构是DataFrame,如果我们知道RDD里面的字段,也 ...
- Spark如何读写hive
原文引自:http://blog.csdn.net/zongzhiyuan/article/details/78076842 hive数据表建立可以在hive上建立,或者使用hiveContext.s ...
- spark mysql读写
val data2Mysql2 = (iterator: Iterator[(String, Int)]) => { var conn: Connection = null; var ps: P ...
- spark 集成elasticsearch
pyspark读写elasticsearch依赖elasticsearch-hadoop包,需要首先在这里下载,版本号可以通过自行修改url解决. """ write d ...
随机推荐
- Vue 是如何实现数据双向绑定的?
Vue 数据双向绑定主要是指: 数据变化更新视图 视图变化更新数据. 即: 输入框内容变化时,Data 中的数据同步变化.即 View => Data 的变化. Data 中的数据变化时,文本节 ...
- Java实现快速快速排序算法
算法简介 快速排序(Quick Sort) 是由冒泡排序改进而得的.在冒泡排序过程中,只对相邻的两个记录进行比较,因此每次交换两个相邻记录时只能消除一个逆序.如果能通过两个(不相邻)记录的一次交换直接 ...
- [oeasy]python0066_控制序列_光标位置设置_ESC_逃逸字符_CSI
光标位置 回忆上次内容 上次讲了 三引号的输出 三引号中 回车和引号 都会 被原样输出 \ 还是需要从 \\转义 黑暗森林 快被摸排清了 还有哪个 转义序列 没 研究过吗? \e是 干什么的? 回忆转 ...
- SSH指定用户登录与限制
环境准备 :::info 实验目标:ServerA通过用户ServerB(已发送密钥和指定端口) ::: 主机 IP 身份 ServerA 192.168.10.201 SSH客户端 ServerB ...
- 提高 C# 的生产力:C# 13 更新完全指南
前言 预计在 2024 年 11 月,C# 13 将与 .NET 9 一起正式发布.今年的 C# 更新主要集中在 ref struct 上进行了许多改进,并添加了许多有助于进一步提高生产力的便利功能. ...
- 2023/4/13 SCRUM个人博客
1.我昨天的任务 ------------ 2.遇到了什么困难 ------------ 3.我今天的任务 初步了解项目的整体框架,并对接下来的人脸识别库以及组件有基本了解和安装
- PHP数组遍历的四种方法
PHP数组循环遍历的四种方式 [(重点)数组循环遍历的四种方式] 1,https://www.cnblogs.com/waj6511988/p/6927208.html 2,https://www ...
- RPA+ddddocr识别图片验证码
上篇我们已经使用python识别了验证码,接下来用RPA接收python识别验证码结果进行登录 1.RPA首先安装python包 ddddocr 2.RPA新建一个python模块 编写代码 impo ...
- 【Layui】11 滑块 Slider
文档地址: https://www.layui.com/demo/slider.html 基本滑块: <fieldset class="layui-elem-field layui-f ...
- 2024年 智能机器人元年 —— 国内的智能机器人(humanoid)公司当下最大的压力(最为急迫的任务)是什么?
可以说,2024年是人形机器人的元年.我国在去年年底将发展智能机器人立为了第一线的重要科技发展方向,并计划在2024年.2025年建立出完整的产业链条,并培育出几家成熟的行业领先的智能机器人公司.而我 ...