Java 并发编程(七)线程池
任务的创建与执行
在多线程的编程环境中,理想的情况是每个任务之间都存在理想的边界,各个任务之间相互独立,这样才能够享受到并发带来的明显的性能提升,并且,由于每个任务之间如果都是独立的,对于并发的处理也会简单许多。
一般情况下,显式地创建一个线程,启动一个任务会调用以下的构造函数创建一个 Thread 对象:
public Thread(Runnable target) {
// 。。。。。。。
}
然后调用 Thread 对象的 start() 方法启动这个任务:
Thread thread = new Thread(runnable);
thread.start();
这样显式地为每个任务创建一个单独的线程来处理存在以下几个问题:
- 创建一个线程有一定的开销,当任务数量十分大的时候,如果依旧是为每个任务创建一个单独的线程来处理,那么将会消耗大量的计算资源(主要是线程的创建和销毁)
- 将会浪费大量的资源,存活的线程会占用一定的内存空间,特别是当存货的线程的数量远大于处理器的核心数时,将会导致大量的空闲线程的存在,占用大量的内存
- 为每个任务创建单独的线程的系统是不稳定的,在
JVM中,对于线程的数量也是有限制的,特别是JVM线程栈的限制,在一个 32 位的机器上,一般允许最多存在几千到几万个线程,超过这个数量将会导致OutOfMemoryError,遇到这种情况很难再恢复
任务是一组逻辑工作单元,而线程则是使任务异步的方式[1]
认识到任务和线程之间的关系很重要,这就是引入线程池的原因,因为任务是一组逻辑工作单元,谁来处理它其实任务本身并不关心;线程是具体处理任务的负载,它只是单纯地处理任务,线程本身不知道任务的具体内容。
Executor 框架
线程池简化了线程的管理工作,java.util.concurrent 提供了一种灵活的线程池实现做为 Executor 框架的一部分,在 Java 类库中,任务执行的主要抽象不是 Thread,而是 Executor[1]
Executor 接口的定义如下:
public interface Executor {
void execute(Runnable command); // Runnable 表示任务
}
Executor 基于 “生产者—消费者” 模式,提交任务的操作相当于生产者(生产待完成的工作单元),执行任务的线程则相当于消费者(执行这些工作单元)。在 Java 程序中,如果要实现一个 “生产者—消费者” 的设计,最简单的方式通常就是使用 Executor[1]
Executor 的具体的类结构如下所示:
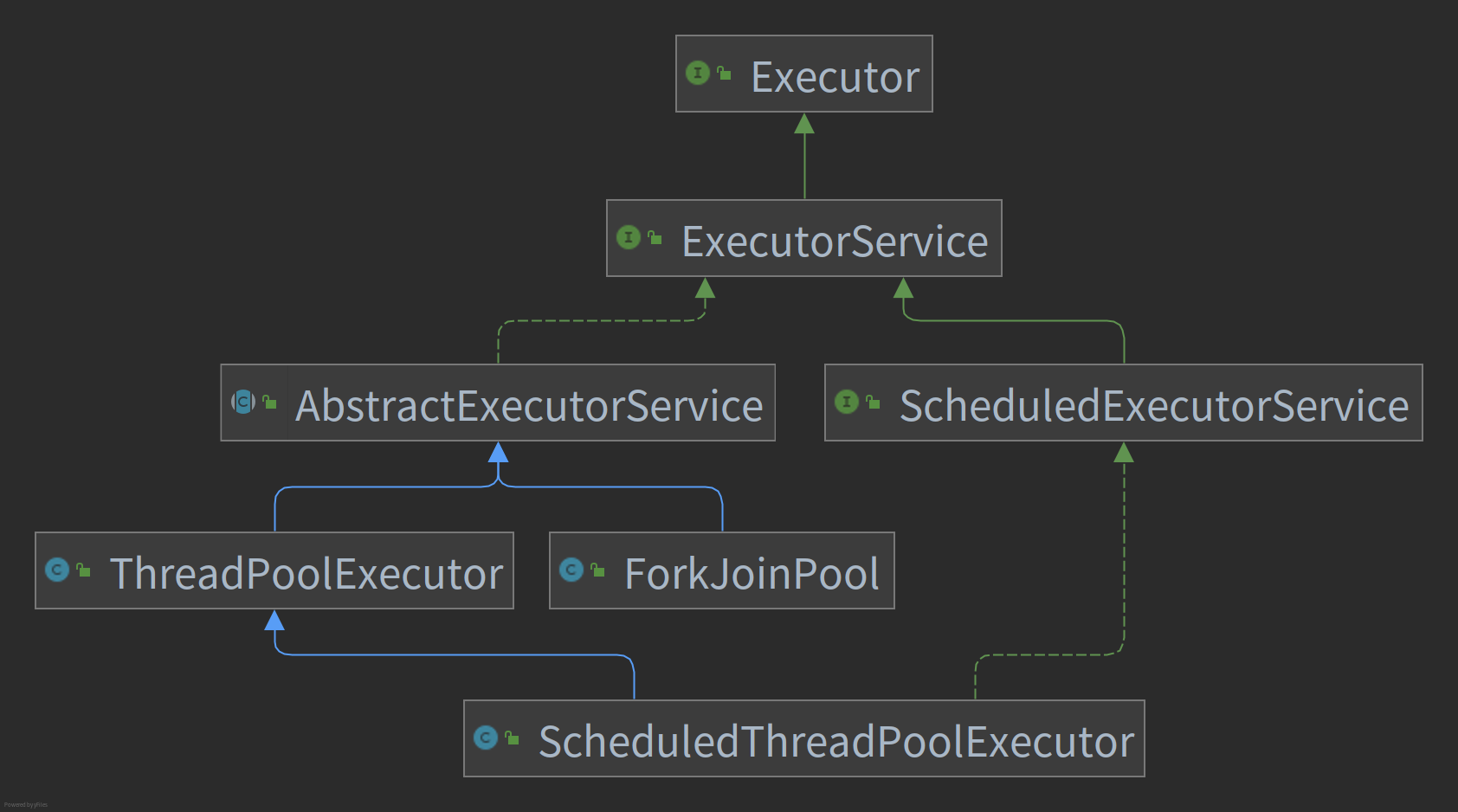
工作单元
Runnable不带返回值的任务,具体的定义如下:
public interface Runnable {
public abstract void run();
}
Callable由于
Runnable的任务不带有返回值(void在此认为不是返回值),因此如果想要获取任务的执行结果,使用Runnable是不能做到的,在这种情况下,需要使用Callable来定义任务,它认为主入口点(即call) 将返回一个值,并可能抛出一个异常具体的定义如下:
public interface Callable<V> { // 如果不需要返回值,可以使得返回值为 Void 对象
V call() throws Exception;
}
Executor 的生命周期
由于 JVM 只有在所有(非守护)线程全部终止之后才会退出,因此,如果不能正确地关闭 Executor,那么 JVM 就无法退出。
Executor 是通过异步的方式来执行任务的,因此对于每个任务的执行,在 Executor 中是无法立刻看到处理结果的。为了解决这个问题,ExecutorService 继承了 Executor,添加了一些用于生命周期管理的方法,具体如下:
public interface ExecutorService extends Executor {
// 终止任务
/*
执行平缓的关闭过程:不再接受新的任务,同时等待已经提交的任务执行完成
(包括那些已经提交但是还没有开始执行的任务)
*/
void shutdown();
/*
以一种粗暴的方式关闭:尝试取消所有运行中的任务,并且不再启动队列中尚未开始的任务
*/
List<Runnable> shutdownNow();
boolean isShutdown();
boolean isTerminated();
boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException;
// 提交任务
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
// 执行任务
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
throws InterruptedException;
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks)
throws InterruptedException, ExecutionException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
ExecutorService 的生命周期有三种状态:运行、关闭、已终止。
ScheduledExecutorService
由于 Timer 用于执行延迟任务中存在的较大的缺陷,使用 ScheduledExecutorService 来实现延迟执行可能是一个不错的选择。
ScheduleExecutorService 中定义的接口如下:
public interface ScheduledExecutorService extends ExecutorService {
public ScheduledFuture<?> schedule(Runnable command,
long delay, TimeUnit unit);
public <V> ScheduledFuture<V> schedule(Callable<V> callable,
long delay, TimeUnit unit);
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit);
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit);
}
使用示例如下:
ScheduledExecutorService service = Executors.newScheduledThreadPool(1); // 创建一个执行延迟任务的线程的线程池
// 定义要执行的延迟任务
ScheduledFuture<?> scheduledFuture = service.schedule(
() -> System.out.println("beep!"), // 具体任务
2, // 延迟的间隔
TimeUnit.SECONDS // 间隔时间的单元
);
// 在 10s 之后取消该线程池中的任务
service.schedule(
() -> scheduledFuture.cancel(true),
10,
TimeUnit.SECONDS
);
Executor 工厂
Executor 工厂对象用于创建 Executor,主要的具体类为 Executors
Executors 中的静态工厂方法如下:
public class Executors {
/*
用于创建固定大小的线程池
*/
public static ExecutorService newFixedThreadPool(int nThreads){}
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory){}
/*
用于创建 ForkJoin 任务。。。。
*/
public static ExecutorService newWorkStealingPool(int parallelism){}
public static ExecutorService newWorkStealingPool(){}
// 创建线程池基本大小只有 1,最大大小为 Integer.MAX_VALUE 的线程池
public static ExecutorService newSingleThreadExecutor(){}
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory){}
/*
创建带有缓存的线程池,实际上,就是使用 SynchronousQueue 代替原有的阻塞队列,这是一种更加有效地避免队列溢出的解决手段
具体地,通过这种方式创建的线程池,基本大小为 0,最大大小为 Integer.MAX_VALUE,由于 SynchronousQueue 的存在能够很好地处理任务排队的问题
*/
public static ExecutorService newCachedThreadPool(){}
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory){}
/*
创建 ScheduledExecutorService
*/
public static ScheduledExecutorService newSingleThreadScheduledExecutor(){}
public static ScheduledExecutorService newSingleThreadScheduledExecutor(ThreadFactory threadFactory) {}
/*
创建 ScheduledExecutorService 的线程池
*/
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize){}
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize, ThreadFactory threadFactory) {}
/*
创建不带配置的 ExecutorService
*/
public static ExecutorService unconfigurableExecutorService(ExecutorService executor){}
public static ScheduledExecutorService unconfigurableScheduledExecutorService(ScheduledExecutorService executor) {}
/*
创建 ThreadFactory,该对象用于定义创建线程的逻辑
*/
public static ThreadFactory defaultThreadFactory(){}
public static ThreadFactory privilegedThreadFactory(){}
/*
Runnable 到 Callable 的转换。。。
*/
public static <T> Callable<T> callable(Runnable task, T result) {}
public static Callable<Object> callable(Runnable task) {}
/*
从原有的 action 中创建 Callable 任务
*/
public static Callable<Object> callable(final PrivilegedAction<?> action) {}
public static Callable<Object> callable(final PrivilegedExceptionAction<?> action) {}
public static <T> Callable<T> privilegedCallable(Callable<T> callable) {}
public static <T> Callable<T> privilegedCallableUsingCurrentClassLoader(Callable<T> callable) {}
}
线程池
一般常用的线程池为 ThreadPoolExecutor
ThreadPoolExecutor
构造函数
ThreadPoolExecutor 是常用的 Executor 的具体实现,具体的类结构图如下所示:

ThreadPoolExecutor 的构造函数如下:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
主要的几个构造参数解释如下:
corePoolSize:线程池的基本大小,即线程池的目标大小,在没有任务执行时线程池的大小,只有当工作队列满了的情况下才会创建超出这个数量的线程maximumPoolSize:线程池的最大大小,表示可以同时活动的线程数量的上限keepAliveTime:线程的存活时间,如果某个线程的空闲时间超过了这个存活时间,那么将会将这个线程标记为可回收的,并且如果此时线程池中线程的数量已经超过了基本大小,那么就会回收这个线程unit:线程活动保存时间的单位workQueue:用于保存等待执行任务的阻塞队列,如ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue、PriorityBloakingQueue等(为了避免资源耗尽,尽量选择有界阻塞队列,通过定义包和策略来处理越界的请求)threadFactory:线程池中创建线程的工厂对象handler:饱和策略,当线程中的线程的数量已经达到最大大小时,并且此时阻塞队列已满的情况下,对于新来的任务的处理策略,如:AbortPolicy、CallerRunsPolicy、DiscardOldestPolicy、DiscardPolicy或者自定义实现RejectedExecutionHandler
饱和策略
JDK 提供了四种饱和策略用于处理有界队列被填满时再收到请求的情况
终止(Abort)策略
默认的饱和策略,该策略将直接抛出未经检查的
RejectedExecutionException,由调用者自行处理这个异常调用者运行(Caller-Runs)策略
该策略是一种调节机制,使用该策略既不会抛出异常,也不会丢弃任务,而是将某些任务回退给调用者,从而降低新任务的压力。具体地,该策略不会在线程池的某个线程中执行新提交的任务,而是在一个已经调用了
execute的线程中执行该任务丢弃(Discard)策略
当新的任务无法保存到队列中时,该策略将会悄悄地丢弃这个任务
丢弃最旧(Discard-Olds)策略
该策略将会丢弃下一个将被执行的任务,然后尝试提交任务。如果工作队列是一个优先级队列,那么将会抛弃优先级最高的任务
扩展 ThreadPoolExecutor
ThreadPoolExecutor 提供了几个保留的钩子方法,使得可以在子类中定义一些相关的钩子操作,具体有以下几个方法:
protected void beforeExecute(Thread t, Runnable r) { } // 执行前
protected void afterExecute(Runnable r, Throwable t) { } // 执行后
protected void terminated() { } // 线程池关闭时,一般用于定义释放资源等操作
具体的一个示例如下所示,通过继承 ThreadPoolExecutor,添加对应的日志打印处理:
import java.util.concurrent.*;
import java.util.concurrent.atomic.*;
import java.util.logging.*;
// 该示例来自 《Java 并发编程实战》
public class TimingThreadPool extends ThreadPoolExecutor {
public TimingThreadPool() {
super(1, 1, 0L, TimeUnit.SECONDS, null);
}
private final ThreadLocal<Long> startTime = new ThreadLocal<Long>();
private final Logger log = Logger.getLogger("TimingThreadPool");
private final AtomicLong numTasks = new AtomicLong();
private final AtomicLong totalTime = new AtomicLong();
// 执行任务之前打印相关的日志信息,同时记录当前的时间戳
protected void beforeExecute(Thread t, Runnable r) {
super.beforeExecute(t, r);
log.fine(String.format("Thread %s: start %s", t, r));
startTime.set(System.nanoTime());
}
/*
执行任务之后再打印日志信息,由于任务开始之前已经得到了当时的时间戳,
因此此时就可以得到该任务的执行时间
*/
protected void afterExecute(Runnable r, Throwable t) {
try {
long endTime = System.nanoTime();
long taskTime = endTime - startTime.get();
numTasks.incrementAndGet();
totalTime.addAndGet(taskTime);
log.fine(String.format("Thread %s: end %s, time=%dns",
t, r, taskTime));
} finally {
super.afterExecute(r, t);
}
}
/*
线程池关闭时执行的操作,这里只是打印对应的日志信息
*/
protected void terminated() {
try {
log.info(String.format("Terminated: avg time=%dns",
totalTime.get() / numTasks.get()));
} finally {
super.terminated();
}
}
}
ScheduledThreadPoolExecutor
执行流程
ScheduledThreadPoolExecutor 通过延时队列来实现,具体的执行流程如下图所示:

- 首先,通过
scheduleAtFixedRate或scheduleWithFixedDelay指定对应的任务与执行延迟 ScheduledThreadPoolExecutor会将这个任务首先添加到延时队列中,取出最小延迟的任务,然后等待并执行- 之后再检查是否是周期性的任务,如果是周期性的任务需要再将它加入到延迟队列中
获取任务
获取任务的具体流程如下图所示:

获取任务的执行流程:
获取
Lock获取周期任务
2.1 如果此时的
PriorityQueue为空,那么将在Condition上阻塞2.2 此时
PriorityQueue不为空,并且此时PriorityQueue的第一个任务还没有到达指定的执行时间,那么在这种情况下依旧会阻塞2.3 此时已经获取到了执行的任务,此时需要首先需要尝试唤醒在
Condition中释放
Lock
执行任务
ScheduledFutureTask 是任务执行的载体,构建该任务时关键的三个参数:
time:表示任务将要被执行的具体的时间sequenceNumber:任务被添加时设置的序号period:任务执行的间隔周期
具体的结构示意如下所示:

线程 1 获取任务并执行的步骤如下:
- 首先从延迟队列中获取一个已经到达的
ScheduledFutureTask - 线程 1 执行任务
- 修改 time 变量,使得这个任务能够周期性地执行
- 将修改之后的任务再放回到原来的延迟队列中
放回任务
放回任务的示意图如下所示:

执行流程:
获取
Lock添加周期任务
值得注意的是在 2.1 步骤中,当发现
PriorityQueue中已经存在元素时,需要唤醒在Condition中等待的线程,使得他们能够执行后续的任务释放
Lock
任务的执行
在 ThreadPoolExecutor 中执行一个任务主要有两种方式:execute 和 submit,其中,execute 用于执行不带返回值的任务,而 submit提交的任务一般都会显式地表达出希望获取执行结果的意图
execute
对于于 ThreadPoolExecutor 中的 execute(Runnable command),具体的源代码如下:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
// 如果线程池中线程的数量小于基本大小,那么直接创建一个新的线程去执行这个任务
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true)) // 线程池中创建的线程会被封装成工作线程 Worker
return;
c = ctl.get();
}
// 如果线程池中线程的数量大于基本大小,并且工作队列不满的情况下,尝试加入到工作队列中
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
/*
此时工作队列已经满了,那么将在线程池中线程的数量小于最大大小的情况下,
将会尝试创建一个新的线程来执行对应的任务
*/
else if (!addWorker(command, false))
reject(command);
}
关键在与 addWorder 方法,它的主要功能是创建一个线程去执行提交的任务,具体的代码如下:
private boolean addWorker(Runnable firstTask, boolean core) {
// 省略一部分不太重要的代码。。。。
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask); // 将当前的任务封装为 Worker
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock(); // 获取全局锁
try {
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w); // 添加 worker 到工作线程集合中
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock(); // 注意最终需要释放锁
}
if (workerAdded) { // 添加成功则启动这个任务
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
关键的地方在于 Worker 对于线程的封装,具体实例化 Worker 的代码如下:
private final class Worker
extends AbstractQueuedSynchronizer // 继承自 AQS,用于实现自身的同步需求
implements Runnable
{
final Thread thread;
Runnable firstTask;
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask; // 当前的执行任务
this.thread = getThreadFactory().newThread(this); // 使用 ThreadFactory 创建一个新的对象
}
}
Worker 中比较关键的一点在于对于任务的执行,对应 run 方法:
public void run() {
runWorker(this);
}
// runWorkers。。。。。。
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
/*
获取锁保证并发的安全性,这里的获取锁和释放锁都是基于 Worker 对象自身对于同步机制的实现
*/
w.lock();
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task); // 钩子方法,用于子类定义的实现,使得在执行任务之前做一些额外的处理
Throwable thrown = null;
try {
task.run(); // 实际执行任务的地方
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown); // 钩子方法,使得子类能够在执行任务之后做一些额外的处理
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
submit
submit 方法在 Executor 方法中定义,对于 ThreadPoolExecutor 来讲,具体的实现是在其父类 AbstractExecutorService 来完成的
ExecutorService 中对于 submit 方法有以下三种形式:
public interface ExecutorService extends Executor {
// 提交 Callable 任务,该任务会带有返回值
<T> Future<T> submit(Callable<T> task);
// 提交 Runnable 任务,该任务带有返回值
<T> Future<T> submit(Runnable task, T result);
// 不带返回值的任务
Future<?> submit(Runnable task);
}
在 AbstractExecutorService 中的具体实现如下:
public abstract class AbstractExecutorService implements ExecutorService {
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Runnable task, T result) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task, result);
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
}
// execute 是 Executor 中对于任务的执行操作,由具体的子类来实现
主要关心的为 newTaskFor 方法,用于创建对应的执行对象,AbstractExecutorService 中的 newTaskFor 的方法实现如下:
// FutureTask 是 Future 的具体实现
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
}
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
return new FutureTask<T>(callable);
}
执行流程
ThreadPoollExecutor 处理任务的流程如下:
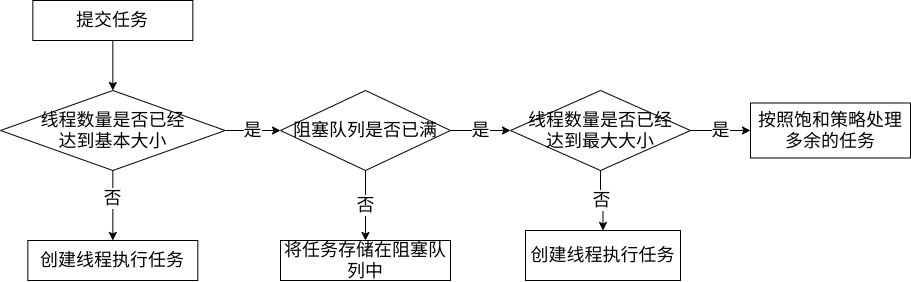
- 当提交一个任务时,如果当前线程池中的线程数量没有达到基本大小
coreSize,那么将会直接创建一个新的线程来执行这个任务 - 当线程池中的数量已经达到了基本大小
coreSize,但是此时的阻塞队列(工作队列)没有满,那么将会将该任务放入到阻塞队列中 - 如果此时线程池中线程的数量已经达到了基本大小,而且此时阻塞队列已经满了,并且此时线程池中的线程数量小于最大大小
maxSize,那么将会创建额外的线程来执行这个任务 - 如果此时线程池中线程的数量已经达到了最大大小
maxSize,此时再提交的任务将会使用预先定义的饱和策略进行处理
线程池大小
需要具体问题具体分析,一般的推荐的基本大小如下:
对于 CPU 密集型的程序,一般线程池的大小比较小,为 \(N_{cpu} + 1\)
对于 IO 密集型的程序,一般设置为 \(2\times N_{cpu}\) 是合理的
混合型
得到可用的 CPU 核心数:
N = Runtime.getRuntime().availableProcessors()定义以下一些变量:
&N_{cpu} = number \; of \; CPU \;(CPU 的总核心数)\\
&U_{cpu} = tagret \; CPU \; utilization\;(0\leq U_{cpu}\leq\quad CPU的使用率)\\
&\frac{W}{C} = ratio\; of \; wait \; time \; to \; compute \; time\; (等待计算的时间所占的比重)
\end{align*}
\]
一般来讲,设置线程池最优的大小为:
$$
N_{threads} = N_{cpu} \ast U_{cpu} \ast(1 + \frac{W}{C})
$$
以上只是推荐的基本大小,具体受到内存、文件句柄、套接字句柄等一系列资源限制的影响。但是线程池大小的上限还是比较容易计算的,只需要计算每个任务对该资源的需求量,然后用该资源的可用总量除以每个任务的需求量,得到的结果就是线程池大小的上限
参考:
[1] 《Java 并发编程实战》
Java 并发编程(七)线程池的更多相关文章
- Java并发编程:线程池的使用
Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了, ...
- Java并发编程:线程池的使用(转)
Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了, ...
- (转)Java并发编程:线程池的使用
背景:线程池在面试时候经常遇到,反复出现的问题就是理解不深入,不能做到游刃有余.所以这篇博客是要深入总结线程池的使用. ThreadPoolExecutor的继承关系 线程池的原理 1.线程池状态(4 ...
- Java并发编程:线程池的使用(转载)
转载自:https://www.cnblogs.com/dolphin0520/p/3932921.html Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实 ...
- Java并发编程:线程池的使用(转载)
文章出处:http://www.cnblogs.com/dolphin0520/p/3932921.html Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实 ...
- [转]Java并发编程:线程池的使用
Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了, ...
- 【转】Java并发编程:线程池的使用
Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了, ...
- 13、Java并发编程:线程池的使用
Java并发编程:线程池的使用 在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了, ...
- Java并发编程之线程池的使用
1. 为什么要使用多线程? 随着科技的进步,现在的电脑及服务器的处理器数量都比较多,以后可能会越来越多,比如我的工作电脑的处理器有8个,怎么查看呢? 计算机右键--属性--设备管理器,打开属性窗口,然 ...
- Java并发编程之线程池及示例
1.Executor 线程池顶级接口.定义方法,void execute(Runnable).方法是用于处理任务的一个服务方法.调用者提供Runnable 接口的实现,线程池通过线程执行这个 Runn ...
随机推荐
- MySQL系列3:缓冲池Buffer Pool的设计思想
1. 回顾 上一篇我们主要讲了InnoDB的存储引擎,其中主要的一个组件就是缓存池Buffer Pool,缓存了磁盘的真实数据,然后基于缓存做增删改查操作,同时配合了后续的redo log.刷磁盘等机 ...
- 创建及管理DSW实例
机器学习PAI 产品概述 快速入门 操作指南 准备工作 工作空间管理 AI计算资源管理 AI开发 开发流程 快速开始 智能标注(iTAG) 可视化建模(PAI-Designer) 交互式建模(PA ...
- jmeter的全局变量(将登陆token设置全局)
1.首先调用登陆接口,用json提取器,取出响应内的token值 2.在beanshell取样器中设置全局变量 //设置全局变量方法一:用函数__setProperty设置${__setProper ...
- [NSSRound#1 Basic]basic_check
打开网站,发现啥也没有: 就用dirsearch扫了一遍.发现还是没有有用信息: 只有再另找方法: 再用nikto扫一次: 发现一个put方法,就用put上传一个一句话木马:可以用插件restlien ...
- math库常用函数+产生随机数总结
math库常用函数+产生随机数总结 1.对x开平方 double sqrt(x)://返回值为double类型,输入的x类型随意,只要是数的类型 2.求常数e的x次方 double exp(x);// ...
- Rust学习 | Rustlings通关记录与题解
2023年6月19日决定对rust做一个重新的梳理,整理今年4月份做完的rustlings,根据自己的理解来写一份题解,记录在此. 周折很久,因为中途经历了推免的各种麻烦事,以及选择数据库作为未来研究 ...
- 记录一次金仓V8R3数据库坏块处理过程、PostgreSQL数据库适用
因数广政务云华为业务存储固件升级,导致数据库产生坏块,业务SQL查询报错如下: ERROR: missing chunk number 0 for toast value 38166585 in SY ...
- 拓展欧几里得 edgcd 模板+简易推论
LL exgcd(LL a,LL b, LL &x, LL &y) { if(b == 0) { x=1,y=0; return a; } LL d = exgcd(b, a%b, x ...
- Vite4+Typescript+Vue3+Pinia 从零搭建(3) - vite配置
项目代码同步至码云 weiz-vue3-template 关于vite的详细配置可查看 vite官方文档,本文简单介绍vite的常用配置. 初始内容 项目初建后,vite.config.ts 的默认内 ...
- 聊聊分布式 SQL 数据库Doris(三)
详细内容阅读: Apache Doris 分区分桶新功能 与 数据划分. 在此基础上做总结与延伸. 在 Doris 的存储引擎规则: 表的数据是以分区为单位存储的,不指定分区创建时,默认就一个分区. ...