【论文阅读】Pyramid Scene Parsing Network
解决的问题:(FCN)
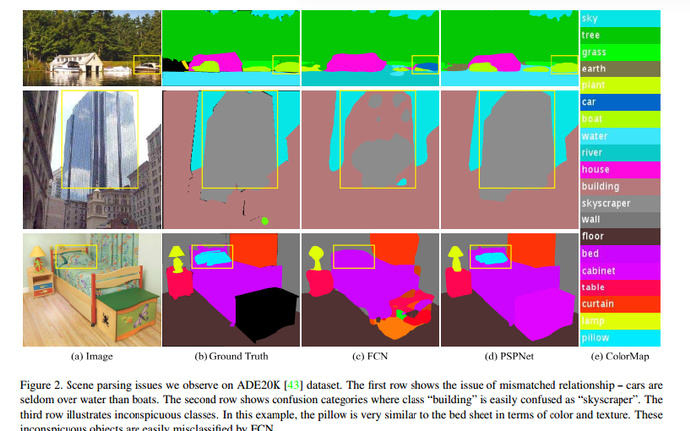
- Mismatched Relationship: 匹配关系错误,如将在水中的船识别为车。
- Confusion Categories: 模糊的分类,如 hill 和 mountain的区分。
- Inconspicuous classes: 无视小尺寸物品。
这些错误与语义间的关系以及不同感知区域的全局信息有关。
通常情况下,我们可以粗略认为,卷积层卷积核大小(感知域)能够表示结构考虑了多大范围的context。然而,在研究中表面,卷积层实际感知域小于理论。因此,很多结构并不能很好地表现全局信息。(即进行分割任务的时候,不能很好的利用全局信息来约束分割效果)
PSPNet 结构
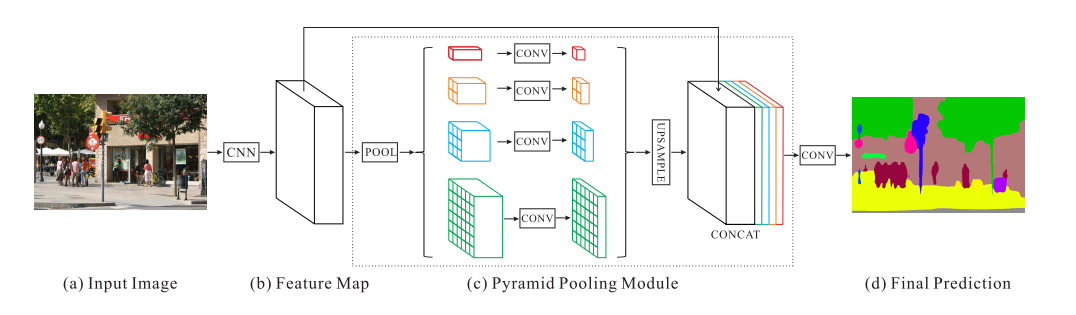
- 上图结构首先将输入图片(a)用
ResNet提取成特征图(b)。 - 通过pyramid pooling modules 来进行不同尺寸的池化。文章中将特征图大小分别池化为:
1x1,2x2,3x3,6x6。并通过一个卷积层将每个特征通道数变为feature map通道数的1/N,其中N为级数,此时N=4。 - 最后将池化结果上采样(文中使用了双线性插值),与特征图(b)连接后,通过卷积层输出结果。
这个结构与FCN不同的是,它通过pyramid的池化层考虑了不同尺寸的全局信息。而在FCN中只考虑了某一个池化层,如FCN-16s 只考虑pool4。
辅助loss
文中还提到了为了训练使用了一个辅助的loss,网络越深性能越好,但是也越难训练.(ResNet solves this problem with skip connection in each block”。作者在网络中间引入了一个额外的loss函数,这个loss函数和网络输出层的loss pass through all previous layers,图示如下
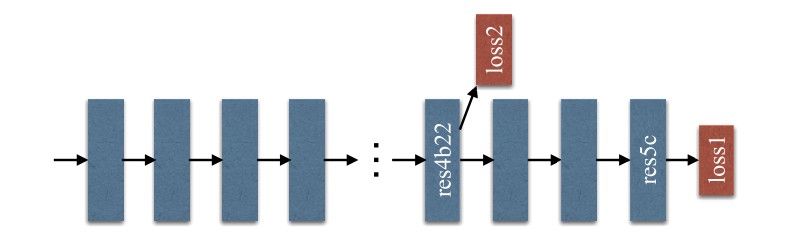
其中loss1是最终的分割loss(softmax_loss),loss2是添加的辅助loss,二类分交叉熵函数,(多分类问题)
实现细节
- 图片输入的CNN是ResNet,使用了dilated convolution
- Pyramid Pooling Module中的conv是1×1的卷积层,为了减小维度和维持全局特征的权重
- Pyramid Pooling Module中的pooling的数量以及尺寸都是可以调节的
- 上采样使用的双线性插值
- poly learning rate policy
- 数据扩增用了:random mirror, random resize(0.5-2), random rotation(-10到10度), random Gaussian blur
- 选取合适的batchsize
【论文阅读】Pyramid Scene Parsing Network的更多相关文章
- 【semantic segmentation】Pyramid Scene Parsing Network(转)
论文地址:https://arxiv.org/pdf/1612.01105.pdf源码地址:https://github.com/hszhao/PSPNet 来自:Semantic Segmentat ...
- 论文阅读笔记十五:Pyramid Scene Parsing Network(CVPR2016)
论文源址:https://arxiv.org/pdf/1612.01105.pdf tensorflow代码:https://github.com/hellochick/PSPNet-tensorfl ...
- PSPnet:Pyramid Scene Parsing Network——作者认为现有模型由于没有引入足够的上下文信息及不同感受野下的全局信息而存在分割出现错误的情景,于是,提出了使用global-scence-level的信息的pspnet
from:https://blog.csdn.net/bea_tree/article/details/56678560 2017年02月23日 19:28:25 阅读数:6094 首先声明,文末彩蛋 ...
- [论文阅读笔记] Structural Deep Network Embedding
[论文阅读笔记] Structural Deep Network Embedding 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 现有的表示学习方法大多采用浅层模型,这可能不能 ...
- [论文阅读笔记] Unsupervised Attributed Network Embedding via Cross Fusion
[论文阅读笔记] Unsupervised Attributed Network Embedding via Cross Fusion 本文结构 解决问题 主要贡献 算法原理 实验结果 参考文献 (1 ...
- 论文阅读:An End-to-End Network for Generating Social Relationship Graphs
论文链接:https://arxiv.org/abs/1903.09784v1 Abstract 社交关系智能代理在人工智能领域中越来越引人关注.为此,我们需要一个可以在不同社会关系上下文中理解社交关 ...
- 【论文阅读】Second-order Attention Network for Single Image Super-Resolution
概要 近年来,深度卷积神经网络(CNNs)在单一图像超分辨率(SISR)中进行了广泛的探索,并获得了卓越的性能.但是,大多数现有的基于CNN的SISR方法主要聚焦于更宽或更深的体系结构设计上,而忽略了 ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- 【医学图像】3D Deep Leaky Noisy-or Network 论文阅读(转)
文章来源:https://blog.csdn.net/u013058162/article/details/80470426 3D Deep Leaky Noisy-or Network 论文阅读 原 ...
- 论文阅读笔记(二十一)【CVPR2017】:Deep Spatial-Temporal Fusion Network for Video-Based Person Re-Identification
Introduction (1)Motivation: 当前CNN无法提取图像序列的关系特征:RNN较为忽视视频序列前期的帧信息,也缺乏对于步态等具体信息的提取:Siamese损失和Triplet损失 ...
随机推荐
- [nefu]算法设计与分析-锐格实验
谈点个人感想:锐格这个题目和数据要是再不维护,估计直接就裂开了,跪求学校升级改进一下OJ系统和题目Orz 实验一 递归与分治 6104 #include<bits/stdc++.h> us ...
- JsonCpp JSON格式处理库的介绍和使用(面向业务编程-文件格式处理)
JsonCpp JSON格式处理库的介绍和使用(面向业务编程-文件格式处理) 介绍 JSON是一种轻量级的数据交换格式,它是一种键值对的集合.它的值可以是数字.字符串.布尔值.序列. 想知道更多有关J ...
- w11修改ie保护模式方法
IE安全设置下有4个区域 对应的设置在不同的注册表中.[HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Internet Set ...
- ASP.NET Core如何知道一个请求执行了哪些中间件?
第一步,添加Nuget包引用 需要添加两个Nuget包分别是:Microsoft.AspNetCore.MiddlewareAnalysis和Microsoft.Extensions.Diagnost ...
- 基于SqlSugar的开发框架循序渐进介绍(26)-- 实现本地上传、FTP上传、阿里云OSS上传三者合一处理
在前面介绍的随笔<基于SqlSugar的开发框架循序渐进介绍(7)-- 在文件上传模块中采用选项模式[Options]处理常规上传和FTP文件上传>中介绍过在文件上传处理的过程中,整合了本 ...
- super 与 this 关键字
super与this用法相似: 1.普通的直接引用 2.形参与成员名字重名,用 this 来指代类本身,super指代父类 public class Students extends Person { ...
- JMeter-BeanShell预处理程序和BeanShell后置处理程序的应用
一.什么是BeanShell? BeanShell是用Java写成的,一个小型的.免费的.可以下载的.嵌入式的Java源代码解释器,JMeter性能测试工具也充分接纳了BeanShell解释器,封装成 ...
- [MAUI]模仿微信“按住-说话”的交互实现
@ 目录 创建页面布局 创建手势控件 创建TalkBox 创建动画 拖拽物动画 按钮激活动画 TalkBox动画 Layout动画 项目地址 .NET MAUI跨平台框架包含了识别平移手势的功能,在之 ...
- 谈一谈Python中的装饰器
1.装饰器基础介绍 1.1 何为Python中的装饰器? Python中装饰器的定义以及用途: 装饰器是一种特殊的函数,它可以接受一个函数作为参数,并返回一个新的函数.装饰器可以用来修改或增强函数的行 ...
- Email发送邮件使用ical4j将时间同步日历中
1.Maven依赖 <!--邮件--> <dependency> <groupId>org.springframework.boot</groupId> ...