Bellman-Ford算法及SPFA算法的思路及进一步优化
Bellman-Ford算法
算法
以边为研究对象的最短路算法。
应用场景
有负边权的最短路问题。
负环的判定。
算法原理
\(n\) 个点的最短路径最多经过 \(n - 1\) 条边。
每条边要么经过,要么不经过,对于一条边的两个端点 \(x\) 和 \(y\)。
所以我们把每一条边都枚举一遍看是否可以进行松弛。将步骤 \(2\) 重复 \(n - 1\) 轮后,\(dis[i]\) 即为起点到达点 \(i\) 的最短路。
代码:
for (int i = 1; i <= n - 1; i++)
for (int j = 1; j <= m; j++)
if (dis[e[j].x] + e[j].w < dis[e[j].y])
dis[e[j].y] = dis[e[j].x] + e[j].w;
时间复杂度
显然是\(O(nm)\)。
Bellman-Ford算法的队列优化(SPFA)
一个点只会松弛它的邻接点,因此,只有 \(x\) 的邻接点的 \(y\) 被松驰过,点 \(x\) 才有松弛的必要。
用队列维护被松弛过的点集。
对于随机数据优化明显,但是最坏情况时间复杂度仍然为 \(O(nm)\)。
模板:Luogu P3371
1.SPFA代码
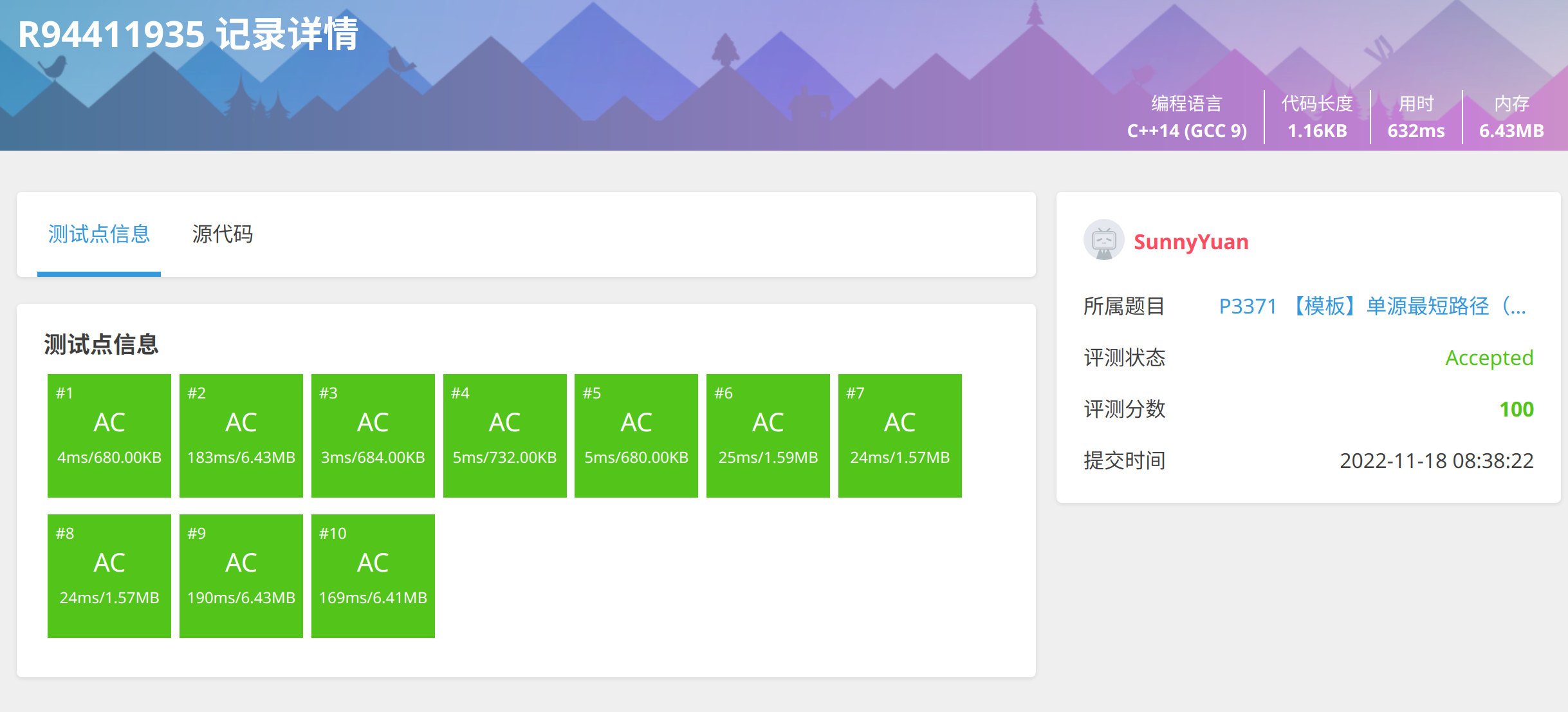
#include <iostream>
#include <cstring>
#include <algorithm>
#include <climits>
#include <queue>
using namespace std;
const int N = 10010, M = 500010, INF = 0x3f3f3f3f;
struct Edge
{
int to;
int next;
int w;
}e[M];
int head[N], idx;
void add(int a, int b, int c)
{
idx++, e[idx].to = b, e[idx].next = head[a], e[idx].w = c, head[a] = idx;
}
int n, m, s;
int dis[N];
void spfa(int u)
{
queue<int> q;
q.push(u);
memset(dis, 0x3f, sizeof(dis));
dis[u] = 0;
while (q.size())
{
int t = q.front();
q.pop();
for (int i = head[t]; i; i = e[i].next)
{
int to = e[i].to;
if (dis[to] > dis[t] + e[i].w)
{
dis[to] = dis[t] + e[i].w;
q.push(to);
}
}
}
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> m >> s;
for (int i = 1; i <= m; i++)
{
int a, b, c;
cin >> a >> b >> c;
add(a, b, c);
}
spfa(s);
for (int i = 1; i <= n; i++)
{
if (dis[i] == INF) cout << INT_MAX << ' ';
else cout << dis[i] << ' ';
}
return 0;
}
2. 优化1:加一个st数组,防止元素重复进队列。
快了215ms
重点关注第27,35,41,49,50,51,52,53行。
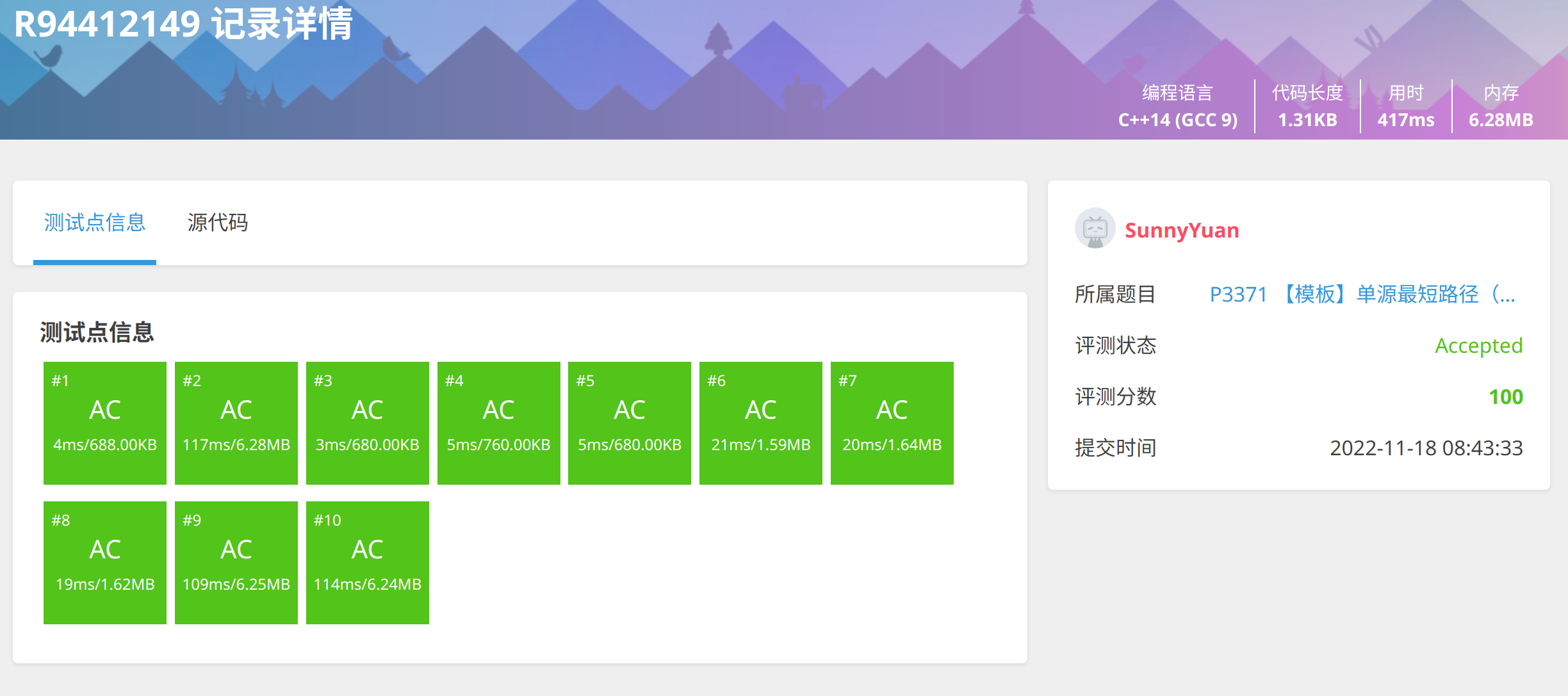
#include <iostream>
#include <cstring>
#include <algorithm>
#include <climits>
#include <queue>
using namespace std;
const int N = 10010, M = 500010, INF = 0x3f3f3f3f;
struct Edge
{
int to;
int next;
int w;
}e[M];
int head[N], idx;
void add(int a, int b, int c)
{
idx++, e[idx].to = b, e[idx].next = head[a], e[idx].w = c, head[a] = idx;
}
int n, m, s;
int dis[N];
bool st[N];
void spfa(int u)
{
queue<int> q;
q.push(u);
memset(dis, 0x3f, sizeof(dis));
dis[u] = 0;
st[u] = true;
while (q.size())
{
int t = q.front();
q.pop();
st[t] = false;
for (int i = head[t]; i; i = e[i].next)
{
int to = e[i].to;
if (dis[to] > dis[t] + e[i].w)
{
dis[to] = dis[t] + e[i].w;
if (!st[to])
{
st[to] = true;
q.push(to);
}
}
}
}
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> m >> s;
for (int i = 1; i <= m; i++)
{
int a, b, c;
cin >> a >> b >> c;
add(a, b, c);
}
spfa(s);
for (int i = 1; i <= n; i++)
{
if (dis[i] == INF) cout << INT_MAX << ' ';
else cout << dis[i] << ' ';
}
return 0;
}
3. 优化2:SLF 优化
每次压入队列时,是看放后面还是前面,所以需要双端队列。
快了18ms
重点关注代码第31,52,53行。
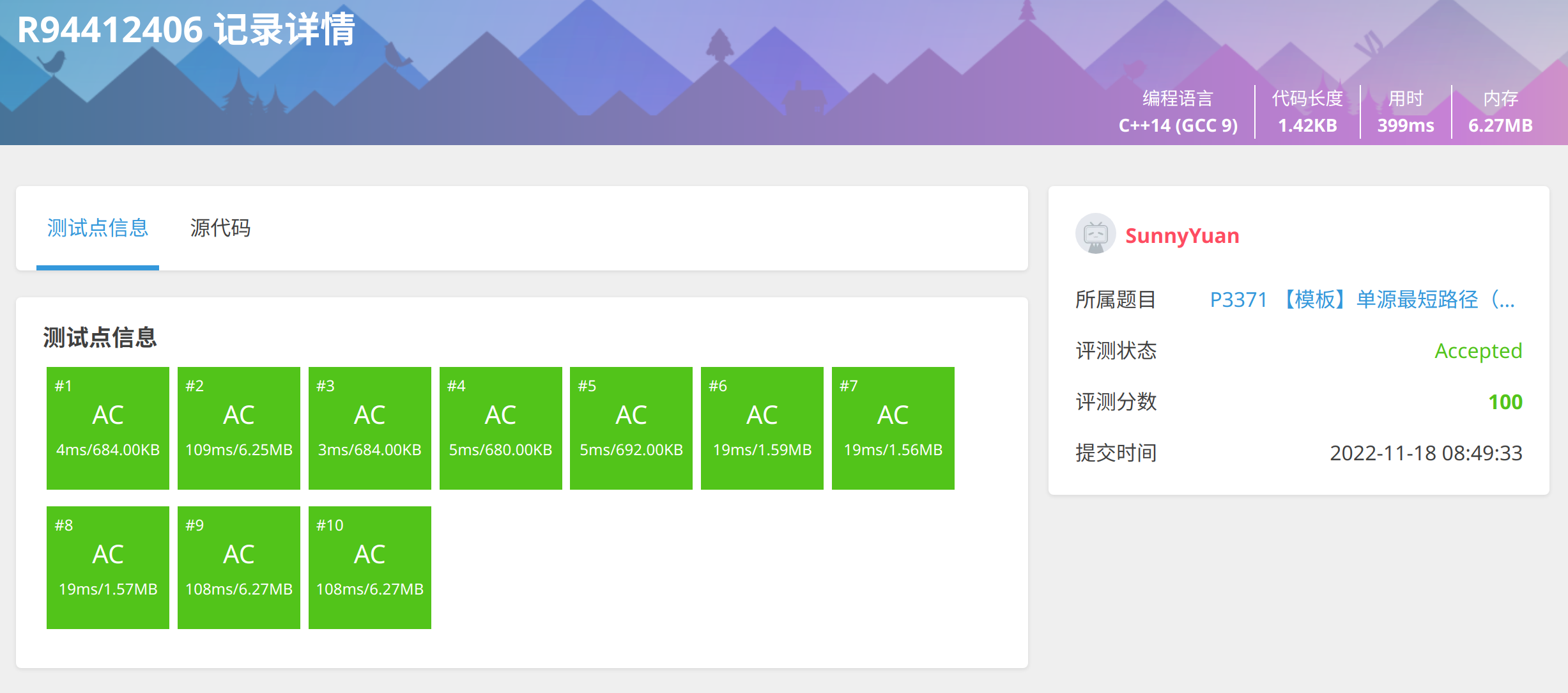
#include <iostream>
#include <cstring>
#include <algorithm>
#include <climits>
#include <queue>
using namespace std;
const int N = 10010, M = 500010, INF = 0x3f3f3f3f;
struct Edge
{
int to;
int next;
int w;
}e[M];
int head[N], idx;
void add(int a, int b, int c)
{
idx++, e[idx].to = b, e[idx].next = head[a], e[idx].w = c, head[a] = idx;
}
int n, m, s;
int dis[N];
bool st[N];
void spfa(int u)
{
deque<int> q;
q.emplace_back(u);
memset(dis, 0x3f, sizeof(dis));
dis[u] = 0;
st[u] = true;
while (q.size())
{
int t = q.front();
q.pop_front();
st[t] = false;
for (int i = head[t]; i; i = e[i].next)
{
int to = e[i].to;
if (dis[to] > dis[t] + e[i].w)
{
dis[to] = dis[t] + e[i].w;
if (!st[to])
{
st[to] = true;
if (q.size() && dis[q.front()] >= dis[to]) q.emplace_front(to);
else q.emplace_back(to);
}
}
}
}
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> m >> s;
for (int i = 1; i <= m; i++)
{
int a, b, c;
cin >> a >> b >> c;
add(a, b, c);
}
spfa(s);
for (int i = 1; i <= n; i++)
{
if (dis[i] == INF) cout << INT_MAX << ' ';
else cout << dis[i] << ' ';
}
return 0;
}
4. 优化3:此优化仅针对不开O2优化时。
使用循环队列进行优化(我改编的)。
(开了O2优化效果不明显,亲自测试在跑网络流时快了800ms,TLE->AC)
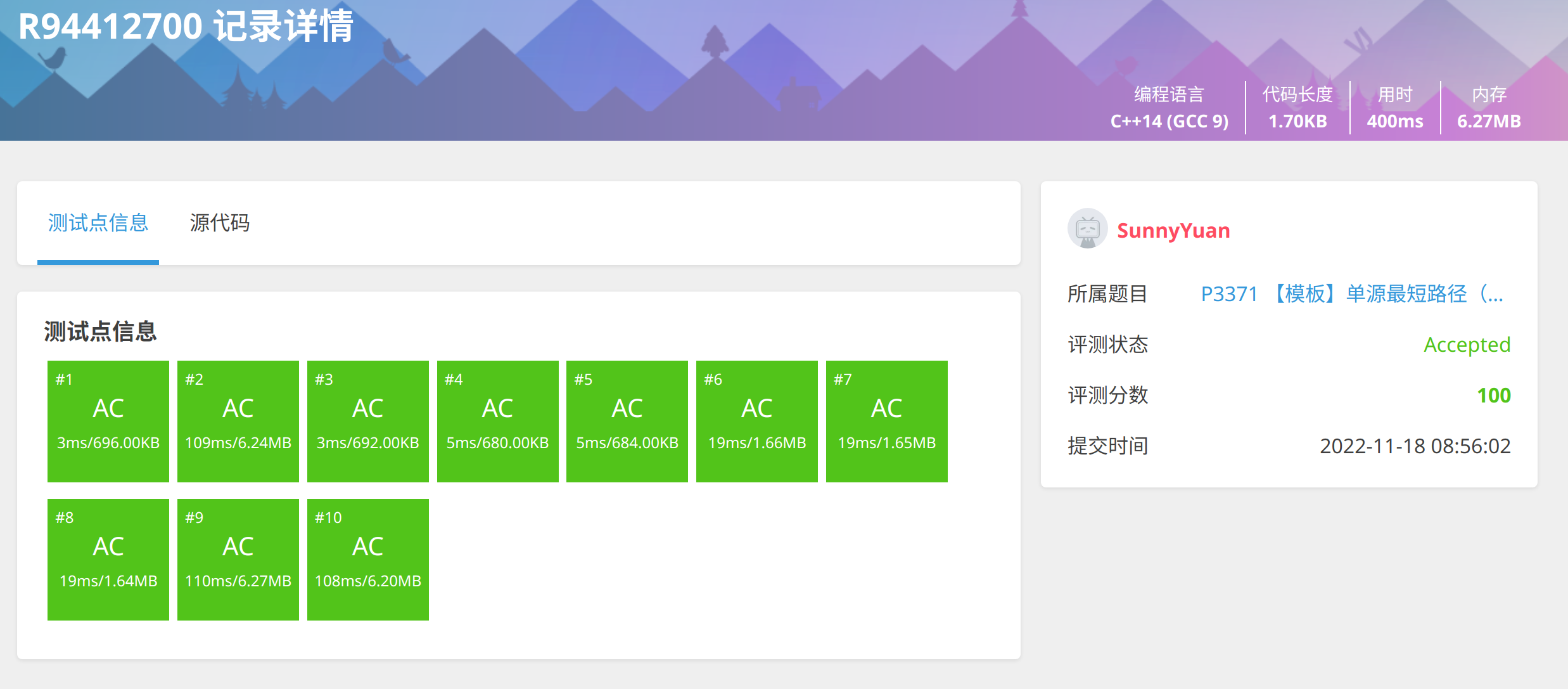
#include <iostream>
#include <cstring>
#include <algorithm>
#include <climits>
#include <queue>
using namespace std;
const int N = 10010, M = 500010, INF = 0x3f3f3f3f;
struct Edge
{
int to;
int next;
int w;
}e[M];
int head[N], idx;
void add(int a, int b, int c)
{
idx++, e[idx].to = b, e[idx].next = head[a], e[idx].w = c, head[a] = idx;
}
int n, m, s;
int dis[N];
bool st[N];
int q[N];
int hh, tt;
int sz;
void push_back(int x)
{
sz++;
q[tt++] = x;
if (tt == N) tt = 0;
}
void push_front(int x)
{
sz++;
hh--;
if (hh == -1) hh = N - 1;
q[hh] = x;
}
void pop_back()
{
sz--;
tt--;
if (tt == -1) tt = N - 1;
}
void pop_front()
{
sz--;
hh++;
if (hh == N) hh = 0;
}
void spfa(int u)
{
push_back(u);
memset(dis, 0x3f, sizeof(dis));
dis[u] = 0;
st[u] = true;
while (sz)
{
int t = q[hh];
pop_front();
st[t] = false;
for (int i = head[t]; i; i = e[i].next)
{
int to = e[i].to;
if (dis[to] > dis[t] + e[i].w)
{
dis[to] = dis[t] + e[i].w;
if (!st[to])
{
st[to] = true;
if (sz && dis[q[hh]] >= dis[to]) push_front(to);
else push_back(to);
}
}
}
}
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> m >> s;
for (int i = 1; i <= m; i++)
{
int a, b, c;
cin >> a >> b >> c;
add(a, b, c);
}
spfa(s);
for (int i = 1; i <= n; i++)
{
if (dis[i] == INF) cout << INT_MAX << ' ';
else cout << dis[i] << ' ';
}
return 0;
}
5. 优化4:LLL优化
如果当前队首元素 \(t\),队列长度为 \(size\),队列里各元素和为 \(sum\) ,有 \(dis[t] \times size \leq sum\),才取队首。
否则把队首元素压入队尾并弹出队首。
效果好像不怎么明显
重点关注代码的第68,72,73,74,75,76,91行。
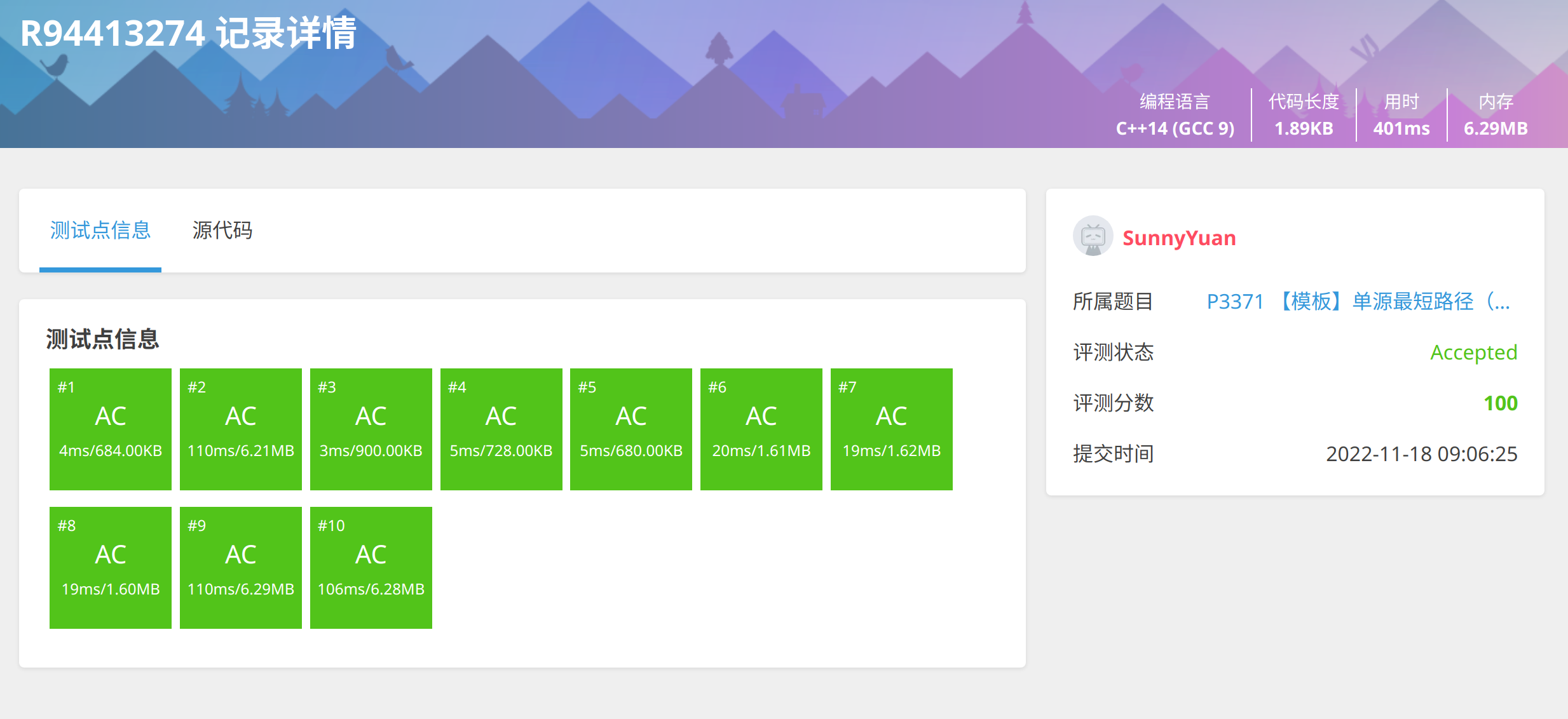
#include <iostream>
#include <cstring>
#include <algorithm>
#include <climits>
#include <queue>
using namespace std;
const int N = 10010, M = 500010, INF = 0x3f3f3f3f;
struct Edge
{
int to;
int next;
int w;
}e[M];
int head[N], idx;
void add(int a, int b, int c)
{
idx++, e[idx].to = b, e[idx].next = head[a], e[idx].w = c, head[a] = idx;
}
int n, m, s;
int dis[N];
bool st[N];
int q[N];
int hh, tt;
int sz;
void push_back(int x)
{
sz++;
q[tt++] = x;
if (tt == N) tt = 0;
}
void push_front(int x)
{
sz++;
hh--;
if (hh == -1) hh = N - 1;
q[hh] = x;
}
void pop_back()
{
sz--;
tt--;
if (tt == -1) tt = N - 1;
}
void pop_front()
{
sz--;
hh++;
if (hh == N) hh = 0;
}
void spfa(int u)
{
push_back(u);
memset(dis, 0x3f, sizeof(dis));
dis[u] = 0;
st[u] = true;
int sum = dis[u];
while (sz)
{
while (dis[q[hh]] * sz > sum)
{
push_back(q[hh]);
pop_front();
}
int t = q[hh];
pop_front();
st[t] = false;
sum -= dis[t];
for (int i = head[t]; i; i = e[i].next)
{
int to = e[i].to;
if (dis[to] > dis[t] + e[i].w)
{
dis[to] = dis[t] + e[i].w;
if (!st[to])
{
st[to] = true;
sum += dis[to];
if (sz && dis[q[hh]] >= dis[to]) push_front(to);
else push_back(to);
}
}
}
}
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n >> m >> s;
for (int i = 1; i <= m; i++)
{
int a, b, c;
cin >> a >> b >> c;
add(a, b, c);
}
spfa(s);
for (int i = 1; i <= n; i++)
{
if (dis[i] == INF) cout << INT_MAX << ' ';
else cout << dis[i] << ' ';
}
return 0;
}
本文终
Bellman-Ford算法及SPFA算法的思路及进一步优化的更多相关文章
- 数据结构与算法--最短路径之Bellman算法、SPFA算法
数据结构与算法--最短路径之Bellman算法.SPFA算法 除了Floyd算法,另外一个使用广泛且可以处理负权边的是Bellman-Ford算法. Bellman-Ford算法 假设某个图有V个顶点 ...
- 最短路径——Bellman-Ford算法以及SPFA算法
说完dijkstra算法,有提到过朴素dij算法无法处理负权边的情况,这里就需要用到Bellman-Ford算法,抛弃贪心的想法,牺牲时间的基础上,换取负权有向图的处理正确. 单源最短路径 Bellm ...
- Bellman-ford算法、SPFA算法求解最短路模板
Bellman-ford 算法适用于含有负权边的最短路求解,复杂度是O( VE ),其原理是依次对每条边进行松弛操作,重复这个操作E-1次后则一定得到最短路,如果还能继续松弛,则有负环.这是因为最长的 ...
- Bellman-Ford算法与SPFA算法详解
PS:如果您只需要Bellman-Ford/SPFA/判负环模板,请到相应的模板部分 上一篇中简单讲解了用于多源最短路的Floyd算法.本篇要介绍的则是用与单源最短路的Bellman-Ford算法和它 ...
- 最短路径算法 4.SPFA算法(1)
今天所说的就是常用的解决最短路径问题最后一个算法,这个算法同样是求连通图中单源点到其他结点的最短路径,功能和Bellman-Ford算法大致相同,可以求有负权的边的图,但不能出现负回路.但是SPFA算 ...
- 图论之最短路算法之SPFA算法
SPFA(Shortest Path Faster Algorithm)算法,是一种求最短路的算法. SPFA的思路及写法和BFS有相同的地方,我就举一道例题(洛谷--P3371 [模板]单源最短路径 ...
- 最短路径算法之四——SPFA算法
SPAF算法 求单源最短路的SPFA算法的全称是:Shortest Path Faster Algorithm,该算法是西南交通大学段凡丁于1994年发表的. 它可以在O(kE)的时间复杂度内求出源点 ...
- 最短路径问题---Floyed(弗洛伊德算法),dijkstra算法,SPFA算法
在NOIP比赛中,如果出图论题最短路径应该是个常考点. 求解最短路径常用的算法有:Floyed算法(O(n^3)的暴力算法,在比赛中大概能过三十分) dijkstra算法 (堆优化之后是O(MlogE ...
- hdoj 1874 畅通工程续【dijkstra算法or spfa算法】
畅通工程续 Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submi ...
- Bellman-ford算法与SPFA算法思想详解及判负权环(负权回路)
我们先看一下负权环为什么这么特殊:在一个图中,只要一个多边结构不是负权环,那么重复经过此结构时就会导致代价不断增大.在多边结构中唯有负权环会导致重复经过时代价不断减小,故在一些最短路径算法中可能会凭借 ...
随机推荐
- JUC(八)ThreadLocal
ThreadLocal 简介 ThreadLocal提供局部线程变量,这个变量与普通的变量不同,每个线程在访问ThreadLocal实例的时候,(通过get或者set方法)都有自己的.独立初始化变量副 ...
- Redis(七)缓存穿透、缓存击穿、缓存雪崩以及分布式锁
应用问题解决 1 缓存穿透 1.1 访问结构 正常情况下,服务器接收到浏览器发来的web服务请求,会先去访问redis缓存,如果缓存中存在数据则直接返回,否则会去查询数据库里面的数据,然后保存在red ...
- Java学习笔记14
1.Arrays类 Arrays类包含用于操作数组的各种方法(如排序和搜索).该类没有构造函数,直接使用类名.方法名()的方法调用需要的方法. 常用方法 方法 作用 public static S ...
- 【kafka】-分区-消费端负载均衡
一.为什么kafka要做分区? 因为当一台机器有可能扛不住(类比:就像redis集群中的redis-cluster一样,一个master抗不住写,那么就多个master去抗写),把一个队列的单一mas ...
- JS 实现关键字文本搜索 高亮显示
示例: 利用字符串的 split 方法,通过搜索的关键字分割成数组 在利用数组的 join 方法拼接成字符串 我是利用mock的省份 1 <template> 2 <div cl ...
- ES6 新增数组,对象,字符串的方法
1,ES6+ 新增数组方法 Array.from Array Array.from(arrayLike[, mapFn[, thisArg]]) 将类数组(伪数组)转换成数组 参数: arrayLik ...
- 痞子衡嵌入式:恩智浦i.MX RT1xxx系列MCU启动那些事(12)- 从SD/eMMC启动
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是恩智浦i.MXRT1xxx系列MCU的SD/eMMC卡启动. 最近在恩智浦官方社区上支持了一个关于 i.MXRT 从 SD 卡启动的案例 ...
- ai问答:使用 Vue3 组合式API 和 TS 父子组件共享数据
这是一个使用 Vue3 组合式 API 和 TypeScript 的简单父子组件共享数据示例 父组件 Parent.vue: <template> <div> <p> ...
- vue移动端适配方案
一.安装postcss-px-to-viewport插件 1.使用npm安装 $ npm install postcss-px-to-viewport --save-dev 2.或者使用yarn安装 ...
- 2023-03-09:用golang调用ffmpeg,将流媒体数据(以RTMP为例)保存成本地文件(以flv为例)。
2023-03-09:用golang调用ffmpeg,将流媒体数据(以RTMP为例)保存成本地文件(以flv为例). 答案2023-03-09: 这是最简单的收流器.本文记录一个最简单的基于FFmpe ...