低代码平台探讨-MetaStore元数据缓存
背景及需求
之前提到我们模型驱动的实现选择的是解释型,需要模型的元数据信息,在接到请求后动态处理逻辑.
此外,应用的通用能力中还包括:页面dsl查询,菜单查询等.
而且后期加入触发器,用户自定义api后,这些元数据也需要提供查询服务.
所以我们需要一个元数据模块,需要提供两个基础功能:加载元数据和提供元数据查询服务.
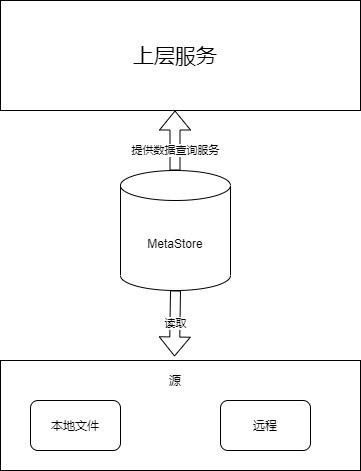
特殊说明:最开始的时候我们支持两种源:本地和远程,后期防止单独部署网络隔离问题把远程逻辑去掉了.
第一版迭代处理的元数据有:模型,页面dsl及菜单,后期加入触发器,用户自定义api,拦截器等,我们今天按照第一版迭代来讨论设计及实现.
模型元数据的需求是缓存一批模型元数据,可以根据模型name获取模型的具体信息.
页面dsl的需求是缓存一批页面dsl,根据dslId获取页面dsl信息.
菜单的需求比较简单,缓存菜单列表和获取菜单列表.
上边说的是功能性需求,接着说下非功能性需求:
- 性能,元数据的查询特别频繁,必须保证高性能,通常会使用缓存,这也是我们这个模块的核心价值之一.
- 数据要准确,从MetaStore获取的数据不能有问题和差异.
- 易于扩展,首先元数据不仅仅有根据id获取的需求,可能还有其他查询需求;其次后期加入其他元数据存储的时候要改动小.
初版设计
设计思路
上边说了需求,下边我们开始正式的设计,先选一个具体场景来说:模型元数据.
为了高性能肯定要使用缓存,开发中常用缓存方式有两种:远程和本地.
远程通常使用NoSql的中间件,如Redis和MemCache,在这种场景下肯定不适合.
该场景最适合的方式是使用内存缓存,查询逻辑简单:根据name或者id获取,所以直接使用map的数据结构即可.
元数据是在应用启动时加载,不会再有变动(后期热部署此处需要重构),利用spring的启动机制,也不用考虑线程安全问题,直接使用HashMap就可以,这里应该是利用的jvm的Happens-before原则.
到此,我们确定了缓存的数据结构及接口:

包含一个内部变量cache是HashMAP类型,一个内部方法去加载数据,对外一个接口方法getByKey,功能比较内聚,类设计是没问题的,下边我们看下具体的逻辑.
详细逻辑
getByKey的逻辑是从缓存变量cache中获取,直接使用map的get方法,不用赘述(此处有坑,下文会有说明),主要看下load加载数据的方法
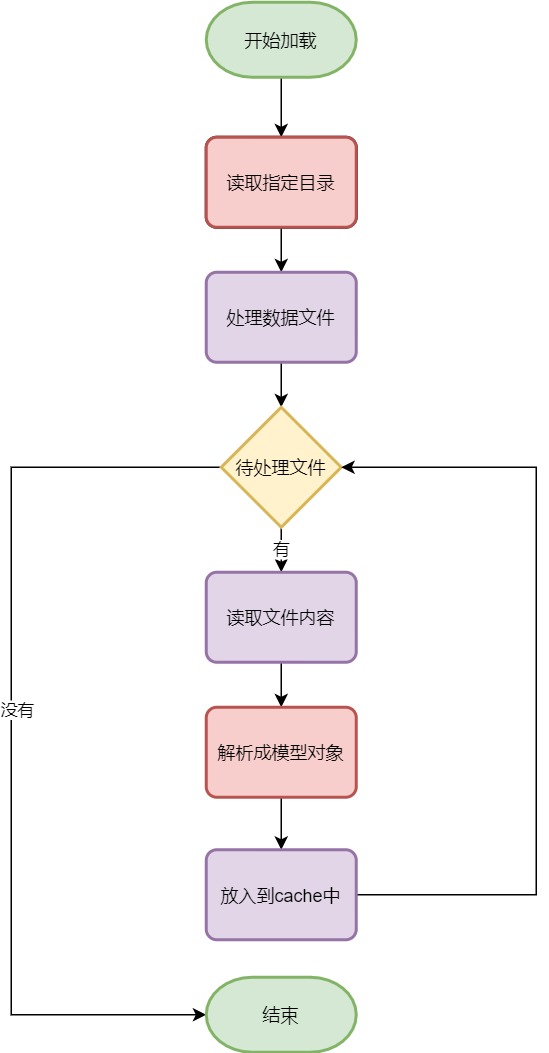
主要逻辑:
读取指定的目录,可以从配置中获取,获取不到使用默认值:models,读取出目录下所有文件.
开始循环处理每个文件,详细步骤:
读取出文件内容:json格式.
json数据转换成Model对象.
把Model对象放入到cache中,key是modelName,value是Model对象.
抽象
当具体方案确定后,如上边所述的逻辑实现起来并不复杂,甚至可以说是简单.
但我们在整体看下会发现:模型和页面dsl的元数据缓存逻辑相似度特别高!
再回头看下上边的逻辑流程图,紫色的部分都是完全相同的,差异只存在与红色的两块逻辑:"读取指定目录"和"解析成对象",我们可以把公共的逻辑抽象出去,做成抽象的父类让子类去继承,利用了继承的代码复用的场景,这是一个典型的模板模式的应用场景.
简单说下模板模式的定义:在一个方法中定义一个算法骨架,并将某些步骤推迟到子类中实现,让子类在不改变算法整体结构的情况下,重新定义算法中的某些步骤.
结合我们的场景来说下:算法骨架就是整体的加载数据流程和获取元数据方法,子类(ModelMetaStore和PageMetaModel)需要实现骨架中的两个扩展方法:"读取指定目录"和"解析成对象".
第一版设计重构后,类图如下
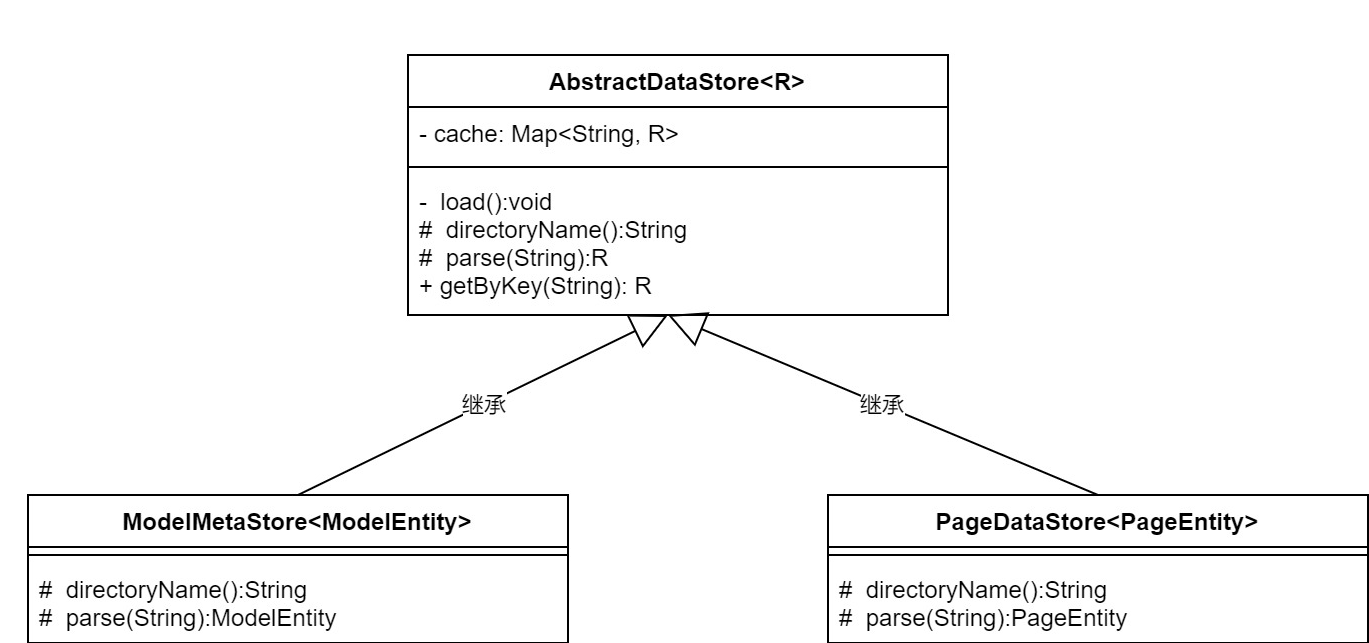
说明:
- 模型数据文件和页面dsl文件都放到各自的目录:models和dsls下,上边两个目录是默认的,但可自定义配置.
- 模型数据目录下的文件类型都是json,文件名是模型名称.
- 页面dsl目录下的文件类型也都是json,文件名是page的id.
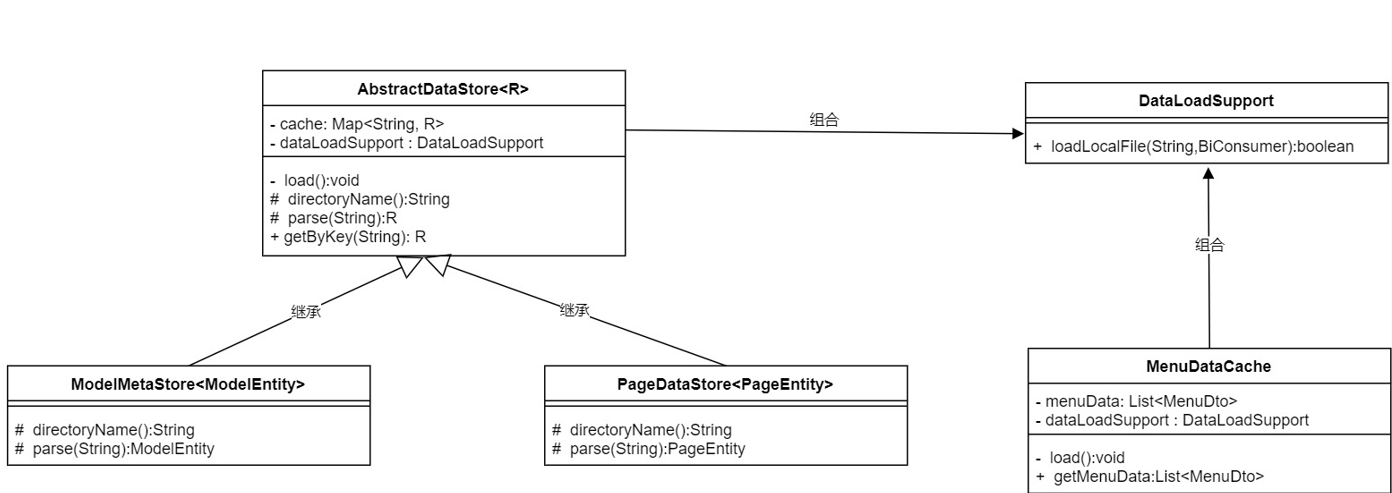
- 抽象出一个父类AbstractDataStore,泛型是子类的对象类型,包含核心逻辑和骨架.内部有一个map类型的cache变量和一个load私有函数用于加载数据,此外提供了两个抽象方法,一个是directoryName:获取文件所在目录,另一个方式是parse:根据文件内容解析成单个对象,这两个抽象方法需要子类实现,最后还有一个根据key获取元数据的公共方法.
- ModelMetaStore和PageDataStore继承了父类AbstractDataStore,泛型分别是ModelEntity和PageEntity,实现上述的两个抽象方法:directoryName和parse,两个方法的逻辑都特别简单,第一个直接返回自己的目录,第二个利用fastjson把字符串解析成指定对象.
组合
上面把模型和页面的元数据缓存设计完成了,还有一个菜单的元数据缓存.
菜单的元数据结构与上边的两个差异很大,每个应用中只会有一个菜单的元数据文件,所以无法使用上边的模板模式,我们需要单独去处理它的逻辑.
实际上菜单的元数据加载逻辑和其他两个(更准确的说应该是抽象类)有一部分重叠:读取文件的内容,这里面需要判断文件是否为空,读取内容字符串及io读取报错等.
这部分逻辑可以复制出来放到菜单的元数据缓存类中,但实际违背了DRY 原则:不要写重复的代码.
那么该如何解决这块重复代码的问题呢?有两个方案:
第一个方案:使用继承.
在AbstractDataStore上再加一层抽象类,里面只包括一个方法:读取文件内容,新的菜单元数据缓存也继承这个抽象类,把读取文件内容的方法移到最上层,类结构图如下:
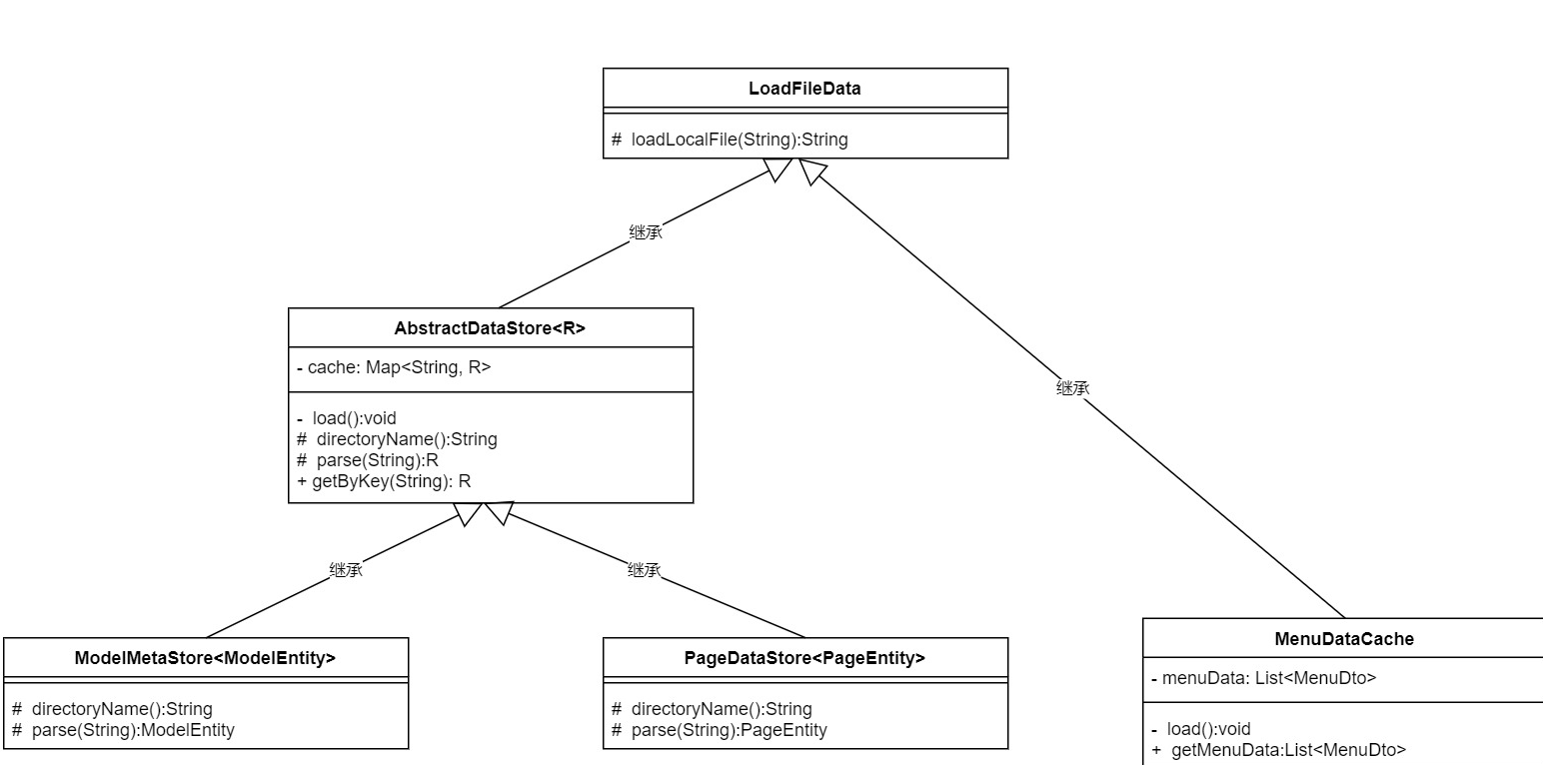
这个方案有两个问题:
- 继承层次太深,逻辑有点乱
- 最上层的抽象类很难起名
AbstractDataStore和MenuDataCache继承LoadFileData从代码上是可行的,但逻辑上不太合理,抽象继承是is-a的关系,这里需要给LoadFileData一个合适的名字才满足设计规范,而这个名字并不太好起.
第一个方案:使用组合.
这个方案实际上更合理一些,面向对象设计有一个原则:组合优于继承.
可以把读取文件内容的逻辑独立出去作为一个新的帮助类DataLoadSupport,AbstractDataStore和MenuDataCache引入它就可以解决代码重复问题.
初始化加载
上一步几乎完成了所有逻辑,但是少了数据加载的触发,这个需要放到服务启动的时候触发.
我们利用了spring的ApplicationListener,有一个细节问题要确定:如何实现ApplicationListener,是每一个类中单独实现,还是统一实现.
为了逻辑的统一,还有后期其他服务需要启动时加载的考虑,我选择了统一实现,具体逻辑和类图如下:
具体逻辑:
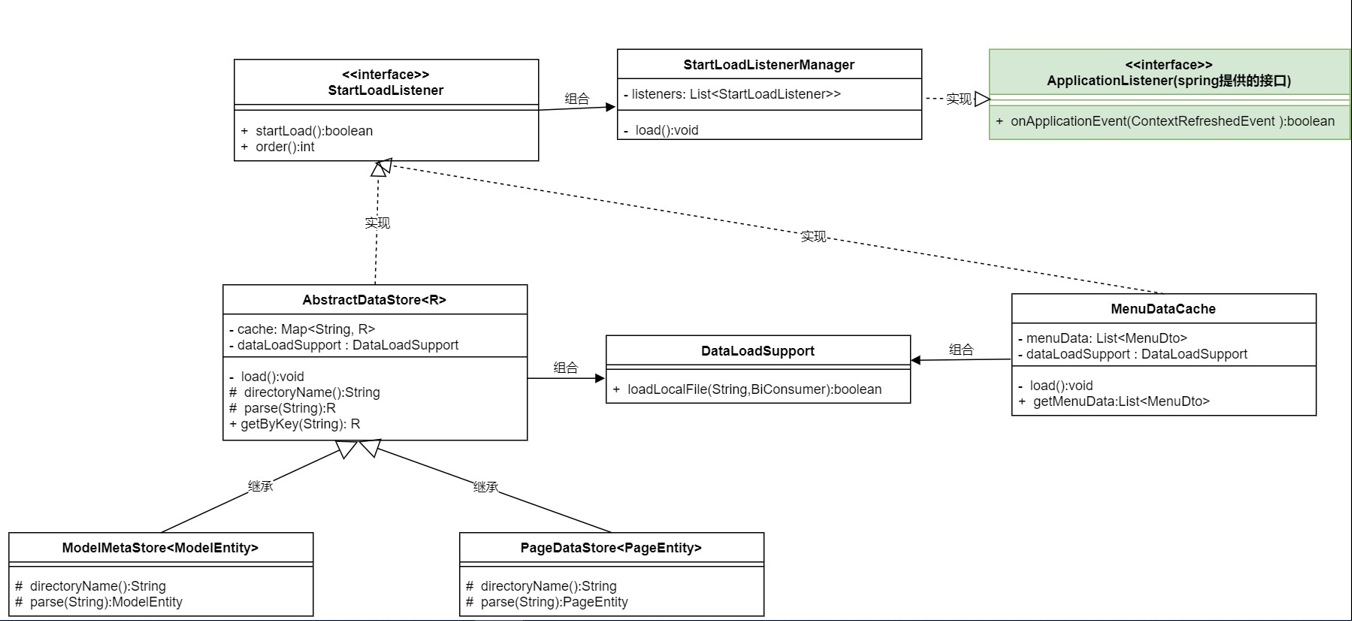
- 新增一个接口StartLoadListener:启动加载监听,启动时需要被触发的操作类实现该接口.
- AbstractDataStore和MenuDataCache实现StartLoadListener接口,标记需要在应用启动时触发,应用启动后触发自己的load方法.
- 新增StartLoadListenerManager类,里面会自动注入所有实现StartLoadListener接口的对象,该类同时实现了spring的ApplicationListener接口,在spring启动后被触发,触发后调用所有的StartLoadListener的startLoad方法,完成所有需要启动时触发的操作.
类图:
第二版设计
如文章开头所说,从元数据缓存中使用key从map中获取信息后直接返回是有问题的,开发完的时候也意识到了一些,但没有去处理,直到某天雷真的炸了.
先说下问题出现的过程,初期功能简单,低代码平台生成的应用都跑的好好的,迭代数次版本后,新增了权限能力:支持简单的数据权限和菜单权限.
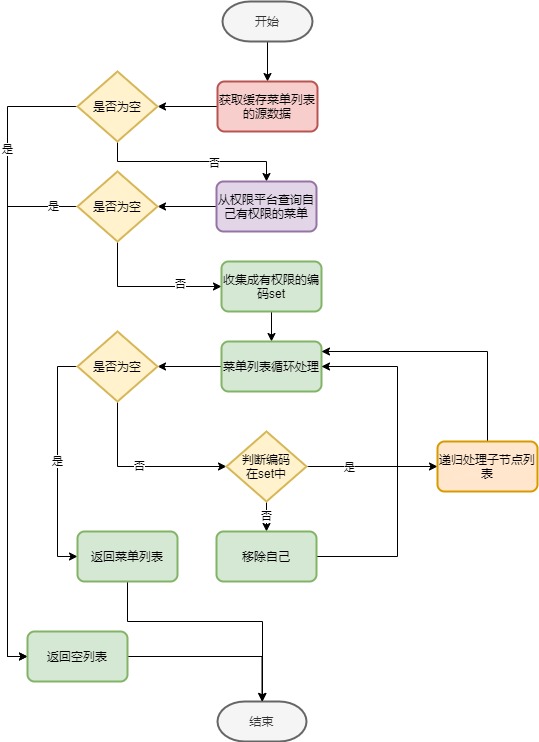
菜单权限的处理逻辑大体如下:
- 从菜单缓存中直接获取缓存的数据.
- 如果菜单列表为空,直接返回给客户端空的列表,结束菜单查询.
- 查询用户有权限的菜单编码列表(set),数据源头是科技权限系统,初期比较粗暴代码耦合到菜单权限代码中,但这不是今天讨论的重点,后边的文章会讲到权限模块的重构.
- 如果用户有权限的菜单编码列表(set)为空,直接返回给客户端空的列表,结束菜单查询.
- 递归处理获取的缓存菜单,如果编码在权限系统返回的编码列表(set)中,递归处理子节点列表(菜单是树形的),否则直接删除该节点,返回到上级递归.
- 循环上步操作,直到所有菜单节点校验完成.
逻辑并不太复杂,开发的时候特意重点关注了递归和权限系统查询,本地测试没什么问题,部署到测试环境也没发现什么问题.
但最后要上线前测试发现了一个问题:切换账号后,菜单不对,有权限的菜单变少了!!!
定位问题的时候,先排查权限系统的返回,结果没问题;在把数据拿到本地走mock测试也没有问题;在最后debug的时候发现了真正的问题,也就是之前意识到但没有解决的问题:在菜单权限逻辑中操作的菜单列表和菜单元数据缓存的菜单列表是同一个对象!
在某个用户处理完自己的权限菜单逻辑后,可能会移除一些节点,下一个用户在获取菜单的时候他的菜单元数据可能就是被处理过(在权限处理中被移除)的了.
元数据存储实际上类似原型模型,原型模式的定义:如果对象的创建成本比较大,而同一个类的不同对象之间差别不大(大部分字段都相同),在这种情况下,我们可以利用对已有对象进行复制(或者叫拷贝)的方式来创建新对象,以达到节省创建时间的目的.
我的实现只做了缓存,但没有实现复制,使得同一对象被多个场景操作.最后导致数据的错误及混乱.
而复制一般也叫拷贝,分为两类:
- 浅拷贝:只会拷贝对象中的基本数据类型的数据(比如,int、long),以及引用对象的内存地址,不会递归地拷贝引用对象本身.
- 深拷贝:不仅仅会复制索引,还会复制数据本身
我们肯定要选择深拷贝,但出现问题的时候已经有几个元数据存储了,特别是菜单数据的结构复杂(树形),短时间没法完成深度复制,市面上的工具类通常只能复制一层,无法自动完成深层次的复制.
当时的解决方案比较粗暴:问题出现在菜单,那只在菜单权限处理的时候做手脚:定义一个新的菜单列表,有权限的菜单深度复制当前对象后加入到list;递归处理子节点.继续重新定义一个list设置为上层节点的子节点,有权限的子节点放入到新的list,递归循环上述步骤.
表象的bug解决了,但实际问题还没有解决,只是被遮盖了,就拿菜单来说,我是在权限服务那处理了,但如果在其他地方使用呢,一样会出现数据缺失的错误.
更严重的是在触发器中提供了获取模型元数据的接口,开发者获取模型元数据后如果进行了修改,导致的错误会更加严重,也更加的难已排查,因为模型元数据的变更会导致模型通用接口逻辑的缺失或混乱,所以深度复制的功能一定要实现.
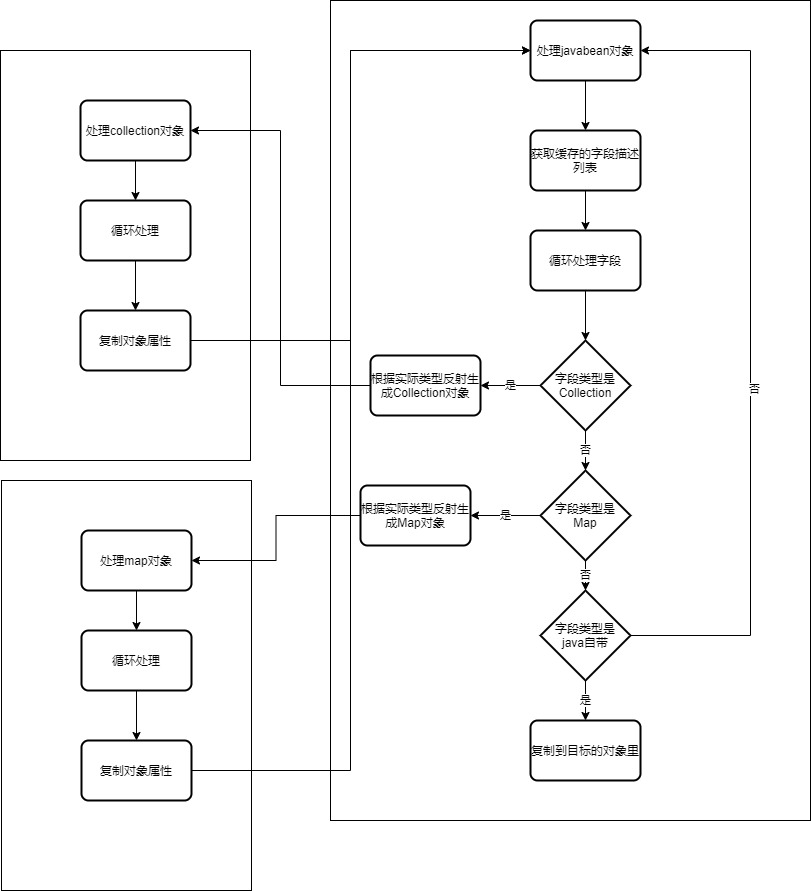
深度复制的实现一般有两种:
第一种序列化后反序列化,比如把数据序列化成json,在反序列化回来.该方案有两个问题:(1)继承的子类多态容易出问题(2)序列化和反序列化是有性能消耗的,在此处方案并不适合.
第二种是递归处理:遇到Collection和Map及javabean类型,进行递归的深度拷贝.该方案开发成本稍高,大量的递归需要特殊注意,此外一些特殊的bean也无法复制:如内部变量是final类型,或者只支持构造函数传入.
我们使用的是第二种,这种方法纯粹是算法类,不再细说,在中间碰到了一个坑:我有一个习惯遇到一些没有数据需要返回空的list的时候我会直接使用Collections.emptyList(),在深度复制的时候根据构造函数新建对象会直接报错,修复方案是:如果是list或者map不是常见的对象类型直接使用常见的对象ArrayList和HashMap.
实际上还有一种方案能解决数据修改问题,使用不变对象,不变对象就是对象在创建后,不可以被修改:没有set方法,且内部变量不会暴露,需要注意的是,内部变量也要进行保护:不变或者深拷贝.
作者:京东科技 吴籽良
来源:京东云开发者社区 转载请注明来源
低代码平台探讨-MetaStore元数据缓存的更多相关文章
- 低代码平台--基于surging开发微服务编排流程引擎构思
前言 微服务对于各位并不陌生,在互联网浪潮下不是在学习微服务的路上,就是在使用改造的路上,每个人对于微服务都有自己理解,有用k8s 就说自己是微服务,有用一些第三方框架spring cloud, du ...
- vivo 低代码平台【后羿】的探索与实践
作者:vivo 互联网前端团队- Wang Ning 本文根据王宁老师在"2022 vivo开发者大会"现场演讲内容整理而成.公众号回复[2022 VDC]获取互联网技术分会场议题 ...
- 基于低代码平台(Low Code Platform)开发中小企业信息化项目
前言:中小企业信息化需求强烈,对于开发中小企业信息化项目的软件工作和程序员来说,如何根据中小企业的特点,快速理解其信息化项目的需求并及时交付项目,是一个值得关注和研讨的话题. 最近几年来,随着全球经济 ...
- 干货!可以使用低代码平台代替Excel吗?
低代码开发平台可以代替Excel?不用惊讶,答案是肯定的,而且,低代码开发平台可以完全代替Excel.例如Zoho Creator低代码平台,可以围绕数据存储.管理和创建工作流程.期间不需要IT人员介 ...
- 2021年哪个低代码平台更值得关注?T媒体盘点国内主流低代码厂商
2020年圣诞前夜,国内知名创投科技媒体T媒体旗下的T研究发布了2020中国低代码平台指数测评报告.报告除了对国内低代码行业现状进行总结外,还对主流低代码厂商的市场渗透和曝光进行测评. 报告认为,低代 ...
- 分析师机构发布中国低代码平台现状分析报告,华为云AppCube为数字化转型加码
摘要:Forrester指出,中国企业数字化转型过程中,有58%的决策者正在采用低代码工具进行软件构建,另有16%的决策者计划采用低代码. 华为消息,知名研究与分析机构Forrester Resear ...
- 使用WtmPlus低代码平台提高生产力
低代码平台的概念很火爆,产品也是鱼龙混杂. 对于开发人员来说,在使用绝大部分低代码平台的时候都会遇到一个致命的问题:我在上面做的项目无法得到源码,完全黑盒.一旦我的需求平台满足不了,那就是无解. ...
- OpenDataV低代码平台增加自定义属性编辑
上一篇我们讲到了怎么在OpenDataV中添加自己的组件,为了让大家更快的上手我们的平台,这一次针对自定义属性编辑,我们再来加一篇说明.我们先来看一下OpenDataV中的属性编辑功能. 当我们拖动一 ...
- vivo 游戏中心低代码平台的提效秘诀
作者:vivo 互联网服务器团队- Chen Wenyang 本文根据陈文洋老师在"2022 vivo开发者大会"现场演讲内容整理而成.公众号回复[2022 VDC]获取互联网技术 ...
- 开源低代码平台开发实践二:从 0 构建一个基于 ER 图的低代码后端
前后端分离了! 第一次知道这个事情的时候,内心是困惑的. 前端都出去搞 SPA,SEO 们同意吗? 后来,SSR 来了. 他说:"SEO 们同意了!" 任何人的反对,都没用了,时代 ...
随机推荐
- Kubernetes(k8s)服务账号Service Accounts
目录 一.系统环境 二.前言 三.服务账号Service Accounts简介 四.用户账号与服务账号区别 五.服务账号(Service Accounts) 5.1 创建服务账号(Service Ac ...
- 暗黑2能用Java开发?还能生成APP?
最近烧哥发现个宝藏项目,竟然用Java开发了暗黑2出来. 众所周知,暗黑2是暴雪开发的一款经典游戏,距今虽有20多年,仍然有很多粉丝. 粉丝延续热情的方式有很多,一种是做Mod,比如魔电,对怪物.技能 ...
- Pb从入坑到放弃(三)数据窗口
写在前面 数据窗口是Pb的一个特色控件,有了数据窗口对于pb来说可谓如虎添翼. 对数据库中的数据操作,几乎都可以在数据窗口中完成. 使用数据窗口可以简单检索数据.以图形化的方式显示数据.绘制功能强大的 ...
- 2023年最具威胁的25种安全漏洞(CWE TOP 25)
摘要: CWE Top 25 是通过分析美国国家漏洞数据库(NVD)中的公共漏洞数据来计算的,以获取前两个日历年 CWE 弱点的根本原因映射. 本文分享自华为云社区<2023年最具威胁的25种安 ...
- 向量数据库Faiss的搭建与使用
向量数据库Faiss是Facebook AI研究院开发的一种高效的相似性搜索和聚类的库.它能够快速处理大规模数据,并且支持在高维空间中进行相似性搜索.本文将介绍如何搭建Faiss环境并提供一个简单的使 ...
- 【git】基于JGit通过ssh-url拉取指定commit-id的代码
实现 1️⃣ pom依赖: <dependency> <groupId>org.eclipse.jgit</groupId> <artifactId>o ...
- 报错 no currentsessioncontext configured!
no currentsessioncontext configured! 使用hibernate框架报错 配置了session工厂类,使用getCurrentSession();时候引起的,原因是cu ...
- MASABlazor在移动端点击保持出现悬停样式
提出问题 最近在学习MAUIBlazor,用的MASA Blazor,发现在移动端(触屏设备)上,点击会一直显示悬停样式,如下图所示,简单研究了一下,发现这是移动端的通病. 解决问题 MASABlaz ...
- 20.1K Star!Notion的开源替代方案:AFFiNE
Notion这款笔记软件相信很多开发者都比较熟悉了,很多读者,包括我自己都用它来记录和管理自己的笔记.今天给大家推荐一个最近比较火的开源替代方案:AFFiNE.目前该开源项目已经斩获20.1K Sta ...
- java使用apache.poi导出word文件
功能说明: 将试卷导出word,并可以打印,装订,效果图: 下面是实现代码: package com.xxxxx.business.course.utils; import com.alibaba.f ...