RLChina理论三:强化学习基础
强化学习基础


马尔可夫决策过程就是在,环境自发做出转变,是个随波逐流的过程,At是智能体的行动,在St环境状态下加入At动作,c才进入下个状态S(t+1),即环境有自己的变化,也加入了智能体的决策。
有无监督学习与强化学习的区别
价值迭代和策略迭代区别
uploading-image-839474.png
五、无模型控制方法
只知道数据,不知道环境的转移函数是什么,常见的两种算法法
(1)SARSA

(2)Q学习,可以再次利用与环境交互产生的数据

价值函数近似算法

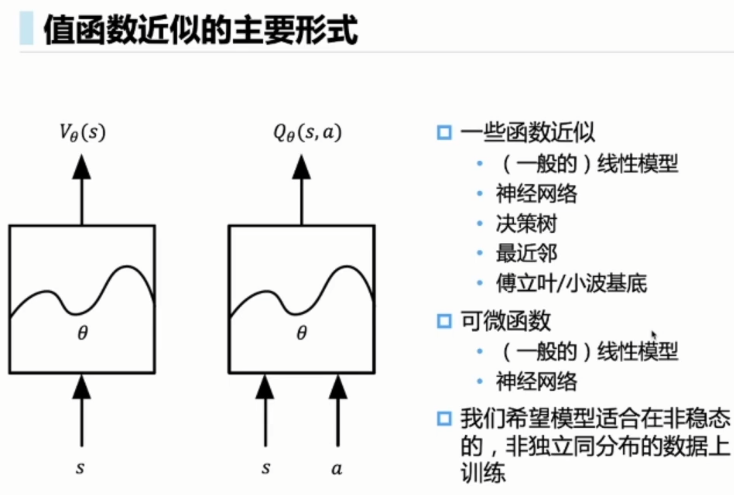
使用参数化的模型,来不断调整参数,来逼近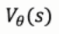 和
和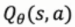
在训练过程中两者都在发生变化,由于参数可导,可以用链式法则去更新参数是θ。


策略梯度(强化学习得精髓)


A2动作得到正向得奖励,增大选择A2动作的概率,适当降低其他动作的选这概率,同理A3得到负的奖励,降低选择A3动作的概率,适当增加其他动作的概率。这就是一个交互性、试错性的学习。

在求导过程中可以使用一个技巧,似然比

RLChina理论三:强化学习基础的更多相关文章
- 分布式强化学习基础概念(Distributional RL )
分布式强化学习基础概念(Distributional RL) from: https://mtomassoli.github.io/2017/12/08/distributional_rl/ 1. Q ...
- 强化学习基础算法入门 【PPT】
该部分内容来自于定期的小组讨论,源于师弟的汇报. ==============================================
- ICML 2018 | 从强化学习到生成模型:40篇值得一读的论文
https://blog.csdn.net/y80gDg1/article/details/81463731 感谢阅读腾讯AI Lab微信号第34篇文章.当地时间 7 月 10-15 日,第 35 届 ...
- 深度强化学习(DRL)专栏(一)
目录: 1. 引言 专栏知识结构 从AlphaGo看深度强化学习 2. 强化学习基础知识 强化学习问题 马尔科夫决策过程 最优价值函数和贝尔曼方程 3. 有模型的强化学习方法 价值迭代 策略迭代 4. ...
- 深度强化学习(DRL)专栏开篇
2015年,DeepMind团队在Nature杂志上发表了一篇文章名为"Human-level control through deep reinforcement learning&quo ...
- 强化学习中的无模型 基于值函数的 Q-Learning 和 Sarsa 学习
强化学习基础: 注: 在强化学习中 奖励函数和状态转移函数都是未知的,之所以有已知模型的强化学习解法是指使用采样估计的方式估计出奖励函数和状态转移函数,然后将强化学习问题转换为可以使用动态规划求解的 ...
- 深度强化学习:Policy-Based methods、Actor-Critic以及DDPG
Policy-Based methods 在上篇文章中介绍的Deep Q-Learning算法属于基于价值(Value-Based)的方法,即估计最优的action-value function $q ...
- 深度强化学习:Deep Q-Learning
在前两篇文章强化学习基础:基本概念和动态规划和强化学习基础:蒙特卡罗和时序差分中介绍的强化学习的三种经典方法(动态规划.蒙特卡罗以及时序差分)适用于有限的状态集合$\mathcal{S}$,以时序差分 ...
- AI小白必读:深度学习、迁移学习、强化学习别再傻傻分不清
摘要:诸多关于人工智能的流行词汇萦绕在我们耳边,比如深度学习 (Deep Learning).强化学习 (Reinforcement Learning).迁移学习 (Transfer Learning ...
- 李宏毅强化学习完整笔记!开源项目《LeeDeepRL-Notes》发布
Datawhale开源 核心贡献者:王琦.杨逸远.江季 提起李宏毅老师,熟悉强化学习的读者朋友一定不会陌生.很多人选择的强化学习入门学习材料都是李宏毅老师的台大公开课视频. 现在,强化学习爱好者有更完 ...
随机推荐
- 详解prettier使用以及与主流IDE的配合
很多前端小伙伴在日常使用prettier的时候都或多或少有一点疑惑,prettier在每一个IDE中究竟是怎样工作起来的,为什么配置有时候生效,有时又毫无效果.为了让我们的前端小伙伴更加熟悉这块,本文 ...
- 《敏捷无敌之DevOps时代》读后感
背景: 2020年基于我司业务形态,我开始实行敏捷项目管理.以敏捷为道,Scrum为法,迭代为术,禅道作器,大张旗鼓的搞了2年敏捷开发.随着时间推移,问题出现在2022年,当时我们已经完全按照Scru ...
- 使用wsl 清理windows 下的C盘
大文件删除思路 ## 在wsl 中可以看到,C盘已经挂载了,挂载点为/mnt/c dewan@wsl ~% df /mnt/c Filesystem Size Used Avail Use% Moun ...
- HTML超文本标记语言4
框架标签...等等 1.框架 <frameset> 框架标签 cols="按列划分" rows="按行划分" 格式:rows="100,* ...
- 跟进 .NET 8 Blazor 之 ReuseTabs 支持 Query 属性绑定
ASP.NET 团队和社区在 .NET 8 继续全力投入 Blazor,为它带来了非常多的新特性,特别是在服务端渲染(SSR)方面,一定程度解决之前 WASM 加载慢,Server 性能不理想等局限性 ...
- go项目实现mysql接入以及web api
本文为博主原创,转载请注明出处: 创建go项目,并在go项目中接入mysql,将mysql的配置项单独整理放到一个胚子和文件中,支持项目启动时,通过加载配置文件中的值,然后创建数据库连接. 之后使用n ...
- 联通光猫获取超级管理员密码,联通宽带逻辑ID 获取
首先使用普通账户登录然后访问这个链接 http://192.168.1.1/backpresettings.conf 保存backpresettings.conf 打开文件就可以看到 cuadmin ...
- Win11和Win10怎么禁用驱动程序强制签名? 关闭Windows系统驱动强制签名的技巧?
前言 什么是驱动程序签名? 驱动程序签名又叫做驱动程序的数字签名,它是由微软的Windows硬件设备质量实验室完成的.硬件开发商将自己的硬件设备和相应的驱动程序交给该实验室,由实验室对其进行测试,测试 ...
- 《SQL与数据库基础》03. SQL-DML
目录 DML 数据插入 数据删除 数据更新 本文以 MySQL 为例 DML 数据插入 给指定字段添加数据: INSERT INTO 表(字段1, 字段2, ......, 字段n) VALUES(值 ...
- .NET开源最全的第三方登录整合库 - CollectiveOAuth
前言 我相信很多同学都对接过各种各样的第三方平台的登录授权获取用户信息(如:微信登录.支付宝登录.GitHub登录等等).今天给大家推荐一个.NET开源最全的第三方登录整合库:CollectiveOA ...