RLChina理论三:强化学习基础
强化学习基础


马尔可夫决策过程就是在,环境自发做出转变,是个随波逐流的过程,At是智能体的行动,在St环境状态下加入At动作,c才进入下个状态S(t+1),即环境有自己的变化,也加入了智能体的决策。
有无监督学习与强化学习的区别
价值迭代和策略迭代区别
uploading-image-839474.png
五、无模型控制方法
只知道数据,不知道环境的转移函数是什么,常见的两种算法法
(1)SARSA

(2)Q学习,可以再次利用与环境交互产生的数据

价值函数近似算法

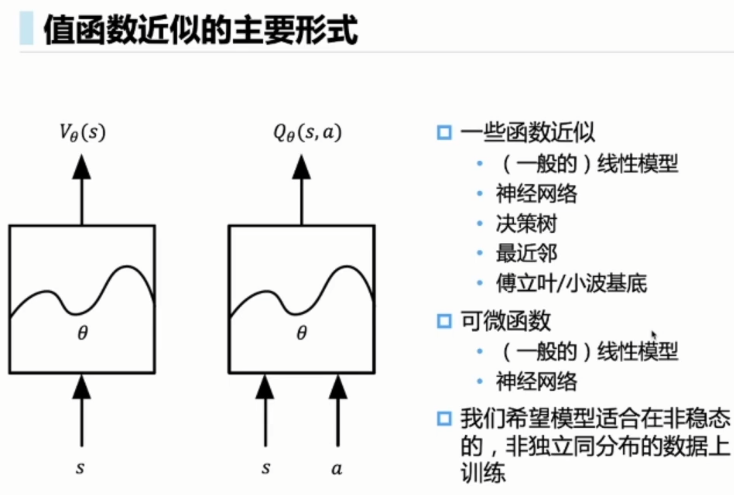
使用参数化的模型,来不断调整参数,来逼近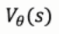 和
和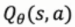
在训练过程中两者都在发生变化,由于参数可导,可以用链式法则去更新参数是θ。


策略梯度(强化学习得精髓)


A2动作得到正向得奖励,增大选择A2动作的概率,适当降低其他动作的选这概率,同理A3得到负的奖励,降低选择A3动作的概率,适当增加其他动作的概率。这就是一个交互性、试错性的学习。

在求导过程中可以使用一个技巧,似然比

RLChina理论三:强化学习基础的更多相关文章
- 分布式强化学习基础概念(Distributional RL )
分布式强化学习基础概念(Distributional RL) from: https://mtomassoli.github.io/2017/12/08/distributional_rl/ 1. Q ...
- 强化学习基础算法入门 【PPT】
该部分内容来自于定期的小组讨论,源于师弟的汇报. ==============================================
- ICML 2018 | 从强化学习到生成模型:40篇值得一读的论文
https://blog.csdn.net/y80gDg1/article/details/81463731 感谢阅读腾讯AI Lab微信号第34篇文章.当地时间 7 月 10-15 日,第 35 届 ...
- 深度强化学习(DRL)专栏(一)
目录: 1. 引言 专栏知识结构 从AlphaGo看深度强化学习 2. 强化学习基础知识 强化学习问题 马尔科夫决策过程 最优价值函数和贝尔曼方程 3. 有模型的强化学习方法 价值迭代 策略迭代 4. ...
- 深度强化学习(DRL)专栏开篇
2015年,DeepMind团队在Nature杂志上发表了一篇文章名为"Human-level control through deep reinforcement learning&quo ...
- 强化学习中的无模型 基于值函数的 Q-Learning 和 Sarsa 学习
强化学习基础: 注: 在强化学习中 奖励函数和状态转移函数都是未知的,之所以有已知模型的强化学习解法是指使用采样估计的方式估计出奖励函数和状态转移函数,然后将强化学习问题转换为可以使用动态规划求解的 ...
- 深度强化学习:Policy-Based methods、Actor-Critic以及DDPG
Policy-Based methods 在上篇文章中介绍的Deep Q-Learning算法属于基于价值(Value-Based)的方法,即估计最优的action-value function $q ...
- 深度强化学习:Deep Q-Learning
在前两篇文章强化学习基础:基本概念和动态规划和强化学习基础:蒙特卡罗和时序差分中介绍的强化学习的三种经典方法(动态规划.蒙特卡罗以及时序差分)适用于有限的状态集合$\mathcal{S}$,以时序差分 ...
- AI小白必读:深度学习、迁移学习、强化学习别再傻傻分不清
摘要:诸多关于人工智能的流行词汇萦绕在我们耳边,比如深度学习 (Deep Learning).强化学习 (Reinforcement Learning).迁移学习 (Transfer Learning ...
- 李宏毅强化学习完整笔记!开源项目《LeeDeepRL-Notes》发布
Datawhale开源 核心贡献者:王琦.杨逸远.江季 提起李宏毅老师,熟悉强化学习的读者朋友一定不会陌生.很多人选择的强化学习入门学习材料都是李宏毅老师的台大公开课视频. 现在,强化学习爱好者有更完 ...
随机推荐
- Dubbo的高级特性:服务治理篇
王有志,一个分享硬核Java技术的互金摸鱼侠 加入Java人的提桶跑路群:共同富裕的Java人 上一篇中,我们已经在Spring Boot应用中集成了Dubbo,并注册了一个服务提供方和一个服务使用方 ...
- 配置http协议访问Harbor镜像仓库
解决http: server gave HTTP response to HTTPS client问题,此问题在上传与下载时均可能出现. 由于docker镜像拉取与推送服务使用的是https协议,但是 ...
- 求任意两个正整数的最大公约数(GCD)。
问题描述 求任意两个正整数的最大公约数(GCD). 问题分析 如果有一个自然数a能被自然数b整除,则称a为b的倍数,b为a的约数.几个自然数公有的约数,叫做这几个自然数的公约数.公约数中最大的一个公约 ...
- 说说 Linux 的 curl 命令
cURL,熟悉 Linux 的同学,没有人不知道这个命令吧:) 它有非常非常多的参数,我这里就不复制粘贴了,有需要可以 -h 或者谷歌搜索看看. 我从实用性的角度,说下我比较常用的几个参数: -v:啰 ...
- Linux 软件包:添加repo、升级内核、编译内核、交叉编译
添加 repo 增加 xxx.repo 文件 在/etc/yum.repos.d/目录下创建 add_openeuler_repo.repo 文件 [add_repo] name=add_repo b ...
- springboot整合mqtt 消费端
用到的工具: EMQX , mqttx , idea 工具使用都很简单,自己看看就能会. 订阅端config代码: package com.example.demo.config; import lo ...
- error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/
解决办法: python3 是用 VC++ 14 编译的, python27 是 VC++ 9 编译的, 安装 python3 的包需要编译的也是要 VC++ 14 以上支持的.可以下载安装这个:vi ...
- mac一键获取最新datagrid 2017.3注册码到剪贴板
mac一键获取最新datagrid 2017.3注册码到剪贴板 近期datagrid 校验激活码合法性的频率提高,导致需要频繁输入激活码 遂整理一脚本,自动获取最新注册码,并拷贝到剪贴板. 打开dat ...
- Tcpdump 使用指南
论网络数据包的分析,我首选wireshark,因为图形化界面直观明了.但如果遇到没有图形化显示的Linux环境,那么此时会使用tcpdump该是一件多么美好的事情. 网上关于tcpdump的介绍很多, ...
- 在Python中使用LooseVersion进行软件版本号比对
技术背景 Python是一门极其热门.极其灵活的开发语言,其更新迭代的速度也非常的快速.有时候我们遇到不同的软件版本不同方法处理的情况,此时就需要用到版本号比对的工具.举一个例子说,我们要在pytho ...