解决Few-shot问题的两大方法:元学习与微调
.center { width: auto; display: table; margin-left: auto; margin-right: auto }
基于元学习(Meta-Learning)的方法:
Few-shot问题或称为Few-shot学习是希望能通过少量的标注数据实现对图像的分类,是元学习(Meta-Learning)的一种。
Few-shot学习,不是为了学习、识别训练集上的数据,泛化到测试集,而是为了让模型学会学习。也就是模型训练后,能理解事物的异同、区分不同的事物。如果给出两张图片,不是为了识别两张图片是什么,而是让模型知道两张图片是相同的事物还是不同的事物。
Few-shot可以被定义为K-way,N-shot问题,表示支持集有k个类别,每个类别有n个样本。不同于训练深度深度神经网络每个类有大量样本的数据集,Few-shot的训练数据集规模很小
Meta-Learning的核心思想就是先学习到一个先验知识(prior),这需要经历多个task的训练,每个task的分为支持集(support set)和查询集(query set),支持集包含了k个类、每个类n张图,模型需要对查询集的样本进行归类以训练模型的学习能力。
经过了很多个task学习先验知识,才能解决新的task,新的task涉及的类,不包含在学习过的task! 我们把学习训练的task称为meta-training task,新的task称为meta-testing task。最后的评价指标就是根据红色部分表现结果。
| meta training task | |
|---|---|
| support | query |
| support | query |
| ... | |
| support | query |
| meta testing task | |
|---|---|
| support | query |
需要注意查询集和测试集的区别,因为在Few-shot训练过程也有查询集,在Few-shot测试中,接触的支持集和测试集都是全新的类。
Supervised Learning vs. Few-shot Learning
| 传统监督学习 | Few-shot 学习 |
|---|---|
| 测试样本未在训练集中见过 | 查询样本没见过 |
| 测试样本的类在训练集中见过 | 查询样本的类属于未知 |
基于微调(Fine-Tuning)的方法:
基于微调的Few-shot方法封为三个步骤:
- 预训练:使用模型在大规模的数据集进行预训练作为特征提取器\(f\)。
- 微调:在支持集上训练分类器。
- Few-shot预测:
- 将支持集上的图像通过分类器转为特征向量;
- 对每一个类的特征向量求平均,得到类的特征向量:\(\mu_1,\dots,\mu_k\);
- 将查询的特征与\(\mu_1,\dots,\mu_k\)比较。
先省略第二步的微调,看看一般的预训练Few-shot预测。
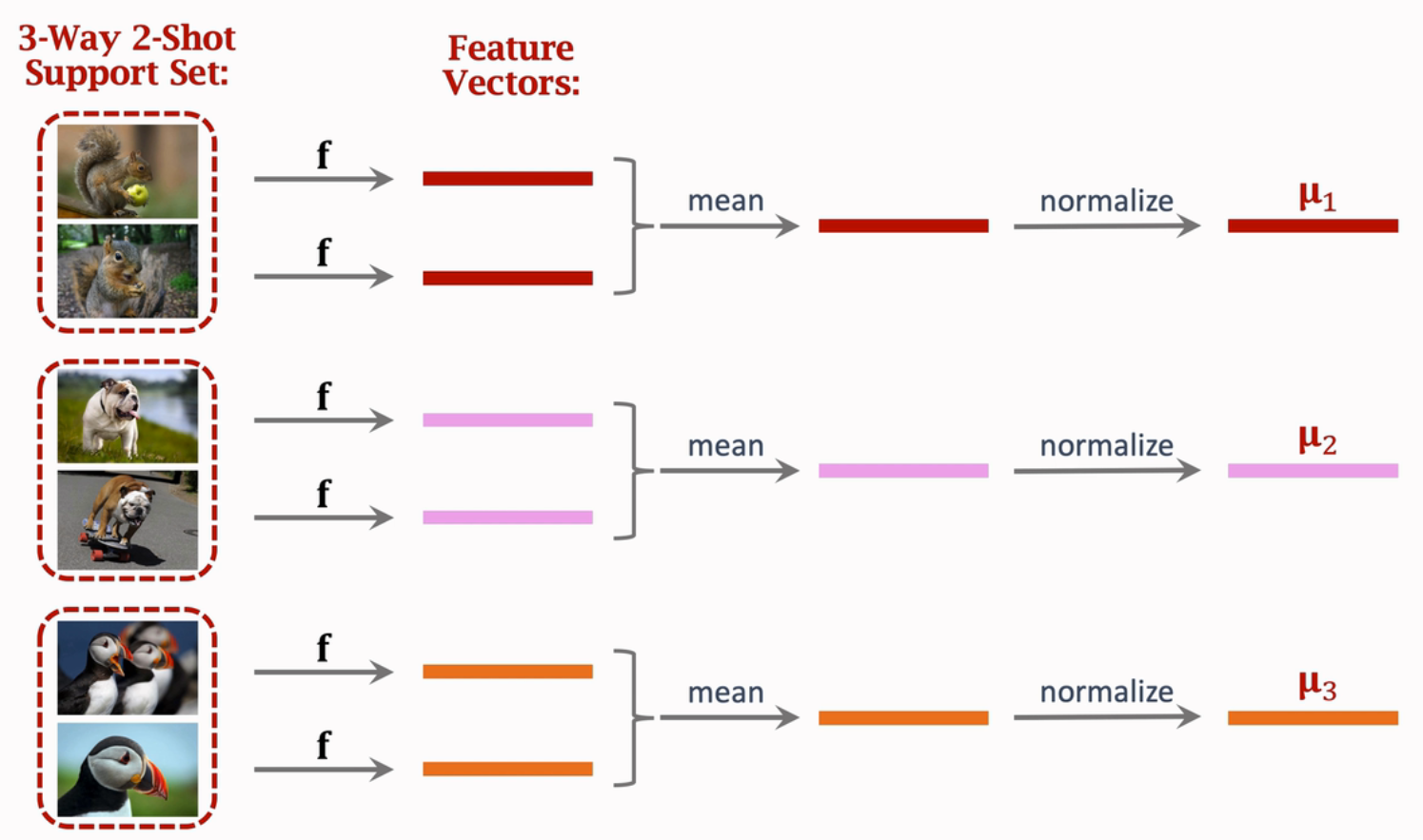
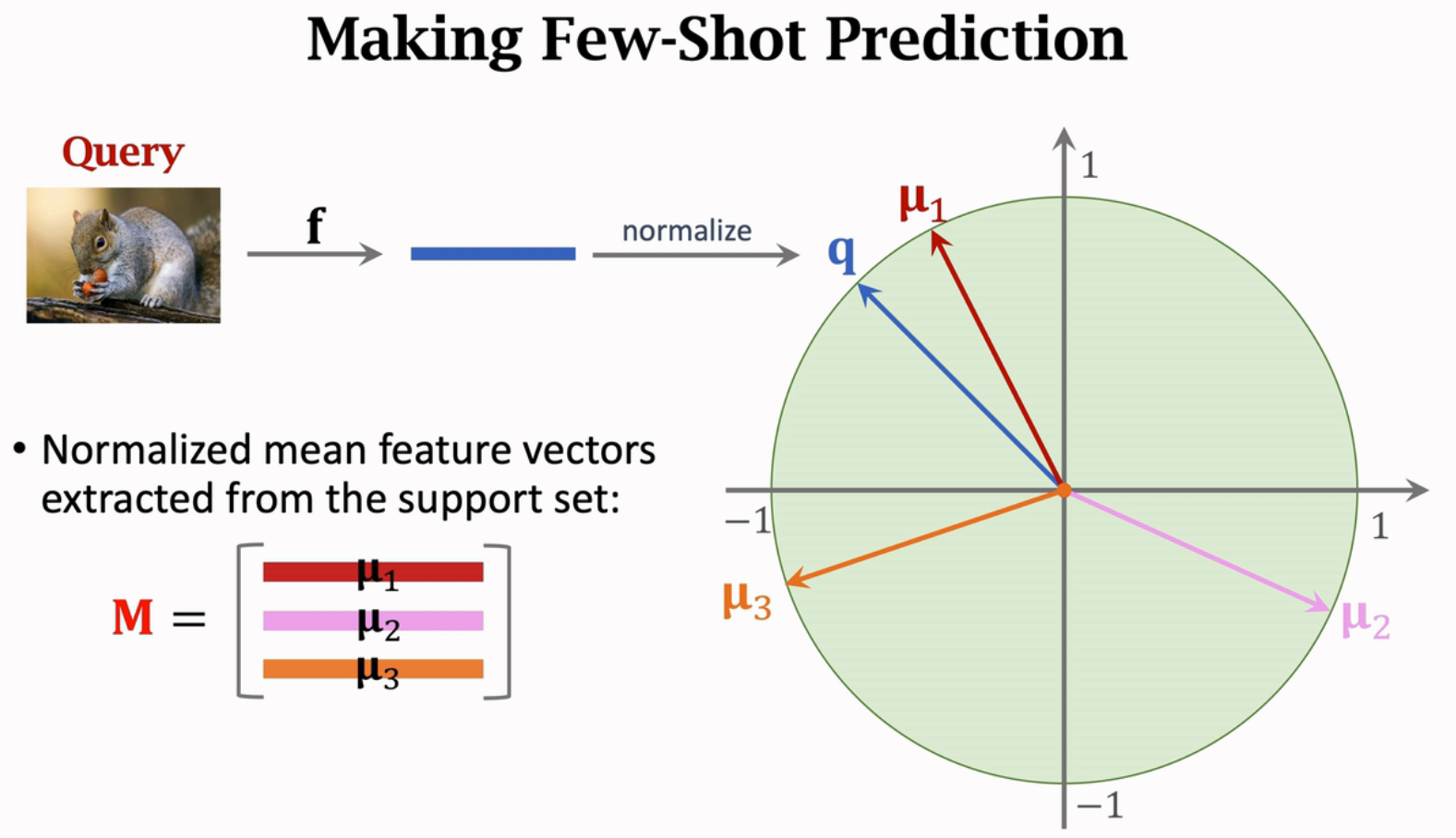
以上图为例,将每一个类的平均特征堆叠得到矩阵\(M\in\mathbb{R}^{3\times n}\),这里\(n\)表示特征数。
\]
将查询的图片提取特征、做归一化得到\(q\in\mathbb{R}^{1\times n}\),并进行预测。
\]
本例中,输出的第一类的概率最大。
归纳一下上述使用预训练模型预测查询集图像的步骤:
- 设置查询集的标记样本:\((x_j,y_j)\)。
- 用预训练模型提取特征:\(f(x_j)\)。
- 进行预测:\(p_j = \mathrm{Softmax}(W\cdot f(x_j)+b)\)。
以上固定了\(W=M, b=2\)。但可以在支持集进行训练,微调\(W\)和\(b\)。于是设置损失函数去学习\(W\)和\(b\),由于支持集较小,需要加入正则项防止过拟合:
\]
大量实验证明,微调确实能提高精度。以下是一些常用的技巧:
- 对于预测分类器\(p=\mathrm{Softmax}=(W\cdot f(x)+b)\),可以进行初始化\(W=M,b=0\)。
- 对于正则项的选择可以考虑Entropy Regularization,相关的解释可以参考文献[3]。
- 将余弦相似度加入Softmax分类器,即:
w^T_1q+b_1 \\
w^T_2q+b_2 \\
w^T_3q+b_3
\end{bmatrix})
\\ \Downarrow
\\
p=\mathrm{Softmax}(\begin{bmatrix}
\mathrm{sim}(w_1,q)+b_1 \\
\mathrm{sim}(w_2,q)+b_2 \\
\mathrm{sim}(w_3,q)+b_3
\end{bmatrix}) \tag{4}
\]
其中\(\mathrm{sim}=\frac{w^Tq}{\lVert w\rVert_2\cdot \lVert q\rVert_2}\)。
对比
基于两种方式解决Few-shot问题的对比
| 元学习(Meta-Learning) | 微调(Fine-Tuning) | |
|---|---|---|
| 策略 | 基于元学习的方法旨在通过在元任务上训练来使模型学会更好地适应新任务。它们通常涉及在多个元任务(task)上进行训练,以使模型能够从不同任务中学到共性。 | 基于微调的方法通常涉及在一个预训练的模型上进行微调,以适应特定的 few-shot 任务。在训练阶段,模型通常会使用大规模的数据集进行预训练,然后在少量训练数据上进行微调。 |
| 适用性 | 基于元学习的方法特别适用于 few-shot 任务,因为它们的目标是使模型从少量示例中快速学习。它们在少量数据和新任务上通常表现出色。 | 基于微调的方法在具有大量预训练数据的情况下通常表现出色。它们适用于很多不同类型的任务,但在数据稀缺或新领域的 few-shot 问题上可能表现不佳。 |
| 泛化能力 | 基于元学习的方法旨在提高模型在新任务上的泛化能力,因为它们通过从多个元任务中学习共性来实现这一目标。它们在适应新任务和未见数据上的表现通常较好。 | 基于微调的方法通常在预训练领域上有较强的泛化能力,但在新任务上的泛化能力可能有限,特别是当训练数据非常有限时。 |
参考文献
解决Few-shot问题的两大方法:元学习与微调的更多相关文章
- 3、Object对象的两大方法(hashCode-equals)总结
Object类是所有java类的父类. 用户定义了如下一个Person类 public class Person{} 在类定义中并没有明确继承Object类,但是编译器会自动的完成这个过程. 既然所有 ...
- 解决android 大图OOM的两种方法
最近做程序中,需要用到一张大图.这张图片是2880*2180大小的,在我开发所用的华为3C手机上显示没有问题,但是给米3装的时候,一打开马上报OOM错误.给nexus5装,则是图片无法出来,DDMS中 ...
- Mysql使用binlog恢复数据解决误操作问题的两种方法
为保证没有其他参数配置影响,重新安装配置了一台最小化安装的CentOS7虚拟机 1. 基础知识 安装mysql5.6数据库Mysql binlog初步理解 2. 配置mysql 开启binlog.修 ...
- 解决php中文乱码的两种方法
第一种是添加html标签变为如下格式: <html> <head> <meta http-equiv="Content-Type" content=& ...
- filter()和sort()这两个方法一块学习,案例中。
<!doctype html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- WPF多线程UI更新——两种方法
WPF多线程UI更新——两种方法 前言 在WPF中,在使用多线程在后台进行计算限制的异步操作的时候,如果在后台线程中对UI进行了修改,则会出现一个错误:(调用线程无法访问此对象,因为另一个线程拥有该对 ...
- 解决多线程安全问题-无非两个方法synchronized和lock 具体原理(百度-美团)
还有其他的锁,如果想要了解,参考:JAVA锁机制-可重入锁,可中断锁,公平锁,读写锁,自旋锁, 用synchronized实现ReentrantLock 美团面试题参考:使用synchronized ...
- HDU 1160 排序或者通过最短路两种方法解决
题目大意: 给定一堆点,具有x,y两个值 找到一组最多的序列,保证点由前到后,x严格上升,y严格下降,并把最大的数目和这一组根据点的编号输出来 这里用两种方法来求解: 1. 我们可以一开始就将数组根据 ...
- 两种方法解决 "The License CNEKJPQZEX- has been cancelled..." 问题
今天在使用 2017 的 IDEA 和 Pycharm 等IDE的时候,提示了如题的问题.之前实在 http://idea.lanyus.com/ 网站点击生成注册码,复制粘贴到 IDEA 中就好了, ...
- hive权威安装出现的不解错误!(完美解决)两种方法都可以
以下两种方法都可以,推荐用方法一! 方法一: 步骤一: yum -y install mysql-server 步骤二:service mysqld start 步骤三:mysql -u root - ...
随机推荐
- <学习笔记> 关于二项式反演
1 容斥原理的式子: \[|A1∪A2∪...∪An|=\sum_{1≤i≤n}|Ai|−\sum_{1≤i<j≤n}|Ai∩Aj|+...+(−1)^{n−1}×|A1∩A2∩...∩An| ...
- 2023-07-31:用r、e、d三种字符,拼出一个回文子串数量等于x的字符串。 1 <= x <= 10^5。 来自百度。
2023-07-31:用r.e.d三种字符,拼出一个回文子串数量等于x的字符串. 1 <= x <= 10^5. 来自百度. 答案2023-07-31: 大体步骤如下: 1.初始化一个字符 ...
- Kubernetes: Kubectl 源码分析
0. 前言 kubectl 看了也有一段时间,期间写了两篇设计模式的文章,是时候对 kubectl 做个回顾了. 1. kubectl 入口:Cobra kubectl 是 kubernetes 的命 ...
- [jmeter]简介与安装
简介 JMeter是开源软件Apache基金会下的一个性能测试工具,用来测试部署在服务器端的应用程序的性能. 安装 安装jmeter 从 官网 下载jmeter的压缩包 安装jdk并配置 JAVA_H ...
- 国标GB28181视频平台EasyGBS视频监控平台无法播放,抓包返回ICMP排查过程
国标GB28181视频平台EasyGBS是基于国标GB/T28181协议的行业内安防视频流媒体能力平台,可实现的视频功能包括:实时监控直播.录像.检索与回看.语音对讲.云存储.告警.平台级联等功能.国 ...
- C#程序变量统一管理例子 - 开源研究系列文章
今天讲讲关于C#应用程序中使用到的变量的统一管理的代码例子. 我们知道,在C#里使用变量,除了private私有变量外,程序中使用到的公共变量就需要进行统一的存放和管理.这里笔者使用到的公共变量管理库 ...
- 半导体行业通信标准SECS/GEM协议一看就懂的
半导体行业通信标准SECS/GEM透析 HSMS通信的设备端通常为客户端(Equipment)(也可称为Active 在通信中主动连接对方的),工厂会部署服务端(Host)(也可称为Passive 被 ...
- MySQL 1130错误原因及解决方案
错误:ERROR 1130: Host 'http://xxx.xxx.xxx.xxx' is not allowed to connect to thisMySQL serve 错误1130:主机x ...
- 【pandas小技巧】--DataFrame的显示参数
我们在jupyter notebook中使用pandas显示DataFrame的数据时,由于屏幕大小,或者数据量大小的原因,常常会觉得显示出来的表格不是特别符合预期. 这时,就需要调整pandas显示 ...
- 深度学习(十二)——神经网络:搭建小实战和Sequential的使用
一.torch.nn.Sequential代码栗子 官方文档:Sequential - PyTorch 2.0 documentation # Using Sequential to create a ...