机器学习策略:详解什么时候该改变开发/测试集和指标?(When to change dev/test sets and metrics)
什么时候该改变开发/测试集和指标?
有时候在项目进行途中,可能意识到,目标的位置放错了。这种情况下,应该移动的目标。

来看一个例子,假设在构建一个猫分类器,试图找到很多猫的照片,向的爱猫人士用户展示,决定使用的指标是分类错误率。所以算法\(A\)和\(B\)分别有3%错误率和5%错误率,所以算法\(A\)似乎做得更好。
但实际试一下这些算法,观察一下这些算法,算法\(A\)由于某些原因,把很多色情图像分类成猫了。如果部署算法\(A\),那么用户就会看到更多猫图,因为它识别猫的错误率只有3%,但它同时也会给用户推送一些色情图像,这是的公司完全不能接受的,用户也完全不能接受。相比之下,算法\(B\)有5%的错误率,这样分类器就得到较少的图像,但它不会推送色情图像。所以从公司的角度来看,以及从用户接受的角度来看,算法\(B\)实际上是一个更好的算法,因为它不让任何色情图像通过。

那么在这个例子中,发生的事情就是,算法A在评估指标上做得更好,它的错误率达到3%,但实际上是个更糟糕的算法。在这种情况下,评估指标加上开发集它们都倾向于选择算法\(A\),因为它们会说,看算法A的错误率较低,这是自己定下来的指标评估出来的。但和的用户更倾向于使用算法\(B\),因为它不会将色情图像分类为猫。所以当这种情况发生时,当评估指标无法正确衡量算法之间的优劣排序时,在这种情况下,原来的指标错误地预测算法A是更好的算法这就发出了信号,应该改变评估指标了,或者要改变开发集或测试集。在这种情况下,用的分类错误率指标可以写成这样:
\(Error = \frac{1}{m_{{dev}}}\sum_{i = 1}^{m_{{dev}}}{I\{ y_{{pred}}^{(i)} \neq y^{(i)}\}}\)
\(m_{{dev}}\)是的开发集例子数,用\(y_{{pred}}^{(i)}\)表示预测值,其值为0或1,\(I\)这符号表示一个函数,统计出里面这个表达式为真的样本数,所以这个公式就统计了分类错误的样本。这个评估指标的问题在于,它对色情图片和非色情图片一视同仁,但其实真的希望的分类器不会错误标记色情图像。比如说把一张色情图片分类为猫,然后推送给不知情的用户,他们看到色情图片会非常不满。
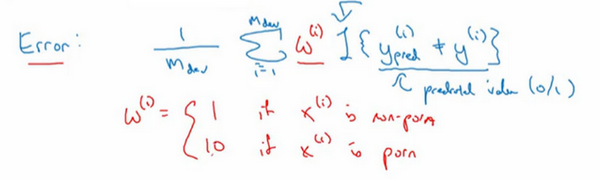
其中一个修改评估指标的方法是,这里(\(\frac{1}{m_{{dev}}}\)与\(\sum_{i =1}^{m_{{dev}}}{I\{ y_{{pred}}^{(i)} \neq y^{(i)}\}}\)之间)加个权重项,即:
\(Error = \frac{1}{m_{{dev}}}\sum_{i = 1}^{m_{{dev}}}{w^{(i)}I\{ y_{{pred}}^{(i)} \neq y^{(i)}\}}\)
将这个称为\(w^{\left( i \right)}\),其中如果图片\(x^{(i)}\)不是色情图片,则\(w^{\left( i \right)} = 1\)。如果\(x^{(i)}\)是色情图片,\(w^{(i)}\)可能就是10甚至100,这样赋予了色情图片更大的权重,让算法将色情图分类为猫图时,错误率这个项快速变大。这个例子里,把色情图片分类成猫这一错误的惩罚权重加大10倍。
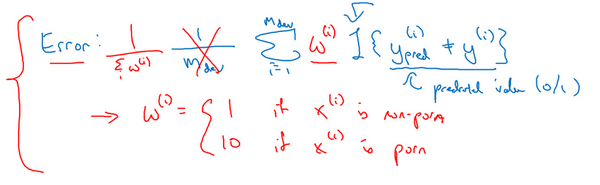
如果希望得到归一化常数,在技术上,就是\(w^{(i)}\)对所有\(i\)求和,这样错误率仍然在0和1之间,即:
\(Error = \frac{1}{\sum_{}^{}w^{(i)}}\sum_{i = 1}^{m_{{dev}}}{w^{(i)}I\{ y_{{pred}}^{(i)} \neq y^{(i)}\}}\)
加权的细节并不重要,实际上要使用这种加权,必须自己过一遍开发集和测试集,在开发集和测试集里,自己把色情图片标记出来,这样才能使用这个加权函数。
但粗略的结论是,如果的评估指标无法正确评估好算法的排名,那么就需要花时间定义一个新的评估指标。这是定义评估指标的其中一种可能方式(上述加权法)。评估指标的意义在于,准确告诉已知两个分类器,哪一个更适合的应用。就这个随笔的内容而言,不需要太注重新错误率指标是怎么定义的,关键在于,如果对旧的错误率指标不满意,那就不要一直沿用不满意的错误率指标,而应该尝试定义一个新的指标,能够更加符合的偏好,定义出实际更适合的算法。
可能注意到了,到目前为止只讨论了如何定义一个指标去评估分类器,也就是说,定义了一个评估指标帮助更好的把分类器排序,能够区分出它们在识别色情图片的不同水平,这实际上是一个正交化的例子。

想处理机器学习问题时,应该把它切分成独立的步骤。一步是弄清楚如何定义一个指标来衡量想做的事情的表现,然后可以分开考虑如何改善系统在这个指标上的表现。要把机器学习任务看成两个独立的步骤,用目标这个比喻,第一步就是设定目标。所以要定义要瞄准的目标,这是完全独立的一步,这是可以调节的一个旋钮。如何设立目标是一个完全独立的问题,把它看成是一个单独的旋钮,可以调试算法表现的旋钮,如何精确瞄准,如何命中目标,定义指标是第一步。
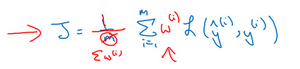
然后第二步要做别的事情,在逼近目标的时候,也许的学习算法针对某个长这样的成本函数优化,\(J=\frac{1}{m}\sum\limits_{i=1}^{m}{L({{\hat y}^{(i)}},{{y}^{(i)}})}\),要最小化训练集上的损失。可以做的其中一件事是,修改这个,为了引入这些权重,也许最后需要修改这个归一化常数,即:
\(J=\frac{1}{\sum{{{w}^{(i)}}}}\sum\limits_{i=1}^{m}{{{w}^{(i)}}L({{\hat y}^{(i)}},{{y}^{(i)}})}\)
再次,如何定义\(J\)并不重要,关键在于正交化的思路,把设立目标定为第一步,然后瞄准和射击目标是独立的第二步。换种说法,鼓励将定义指标看成一步,然后在定义了指标之后,才能想如何优化系统来提高这个指标评分。比如改变神经网络要优化的成本函数\(J\)。
在继续之前,再讲一个例子。假设的两个猫分类器\(A\)和\(B\),分别有用开发集评估得到3%的错误率和5%的错误率。或者甚至用在网上下载的图片构成的测试集上,这些是高质量,取景框很专业的图像。但也许在部署算法产品时,发现算法\(B\)看起来表现更好,即使它在开发集上表现不错,发现一直在用从网上下载的高质量图片训练,但当部署到手机应用时,算法作用到用户上传的图片时,那些图片取景不专业,没有把猫完整拍下来,或者猫的表情很古怪,也许图像很模糊,当实际测试算法时,发现算法\(B\)表现其实更好。

这是另一个指标和开发集测试集出问题的例子,问题在于,做评估用的是很漂亮的高分辨率的开发集和测试集,图片取景很专业。但的用户真正关心的是,他们上传的图片能不能被正确识别。那些图片可能是没那么专业的照片,有点模糊,取景很业余。
所以方针是,如果在指标上表现很好,在当前开发集或者开发集和测试集分布中表现很好,但的实际应用程序,真正关注的地方表现不好,那么就需要修改指标或者的开发测试集。换句话说,如果发现的开发测试集都是这些高质量图像,但在开发测试集上做的评估无法预测的应用实际的表现。因为的应用处理的是低质量图像,那么就应该改变的开发测试集,让的数据更能反映实际需要处理好的数据。
但总体方针就是,如果当前的指标和当前用来评估的数据和真正关心必须做好的事情关系不大,那就应该更改的指标或者的开发测试集,让它们能更够好地反映的算法需要处理好的数据。
有一个评估指标和开发集让可以更快做出决策,判断算法\(A\)还是算法\(B\)更优,这真的可以加速和的团队迭代的速度。所以建议是,即使无法定义出一个很完美的评估指标和开发集,直接快速设立出来,然后使用它们来驱动团队的迭代速度。如果在这之后,发现选的不好,有更好的想法,那么完全可以马上改。对于大多数团队,建议最好不要在没有评估指标和开发集时跑太久,因为那样可能会减慢的团队迭代和改善算法的速度。本随笔讲的是什么时候需要改变的评估指标和开发测试集,希望这些方针能让的整个团队设立一个明确的目标,一个可以高效迭代,改善性能的目标。
机器学习策略:详解什么时候该改变开发/测试集和指标?(When to change dev/test sets and metrics)的更多相关文章
- EasyPR--开发详解(6)SVM开发详解
在前面的几篇文章中,我们介绍了EasyPR中车牌定位模块的相关内容.本文开始分析车牌定位模块后续步骤的车牌判断模块.车牌判断模块是EasyPR中的基于机器学习模型的一个模块,这个模型就是作者前文中从机 ...
- 18个示例详解 Spring 事务传播机制(附测试源码)
什么是事务传播机制 事务的传播机制,顾名思义就是多个事务方法之间调用,事务如何在这些方法之间传播. 举个例子,方法 A 是一个事务的方法,方法 A 执行的时候调用了方法 B,此时方法 B 有无事务以及 ...
- 【Python】详解Python多线程Selenium跨浏览器测试
前言 在web测试中,不可避免的一个测试就是浏览器兼容性测试,在没有自动化测试前,我们总是苦逼的在一台或多台机器上安装N种浏览器,然后手工在不同的浏览器上验证主业务流程和关键功能模块功能,以检测不同浏 ...
- Ajax|看这一篇就够了!详解Ajax工作原理及开发步骤
传统开发的缺点,是对于浏览器的页面,全部都是全局刷新的体验.如果我们只是想取得或是更新页面中的部分信息那么就必须要应用到局部刷新的技术. 局部刷新也是有效提升用户体验的一种非常重要的方式. Ajax技 ...
- 开源PLM软件Aras详解三 服务端简易开发
废话少说,直接进入主题, 以CAD为例: 先找到CAD对象类:具体操作见下图 双击打开,找到服务端事件:见下图 点击新建对象,点击添加,新建Method 编写Method,语言分为前端和后端,前端支持 ...
- 【北京站】详解Visual Studio 2013:开发iOS及android应用!现场图集
现场图集: 活动介绍地址:http://huiyi.csdn.net/module/meeting/meeting/info/660/biz
- 详解MySQL三项实用开发知识
其实项目应用的瓶颈还是在db端,在只有少量数据及极少并发的情况下,并不需要多少的技巧就可以得到我们想要的结果,但是当数据量达到一定量级的时 候,程序的每一个细节,数据库的设计都会影响到系统的性能.这里 ...
- 详解Windows平台搭建Androiod开发环境
http://blog.csdn.net/lyq8479/article/details/6348330 1.安装JDK 2.安装SDK管理器,安装SDK(在线.离线) 3.下载安装Eclipse 4 ...
- 转】[1.0.2] 详解基于maven管理-scala开发的spark项目开发环境的搭建与测试
场景 好的,假设项目数据调研与需求分析已接近尾声,马上进入Coding阶段了,辣么在Coding之前需要干马呢?是的,“统一开发工具.开发环境的搭建与本地测试.测试环境的搭建与测试” - 本文详细记录 ...
- 详解Linux开源安全审计和渗透测试工具Lynis
转载自FreeBuf.COM Lynis是一款Unix系统的安全审计以及加固工具,能够进行深层次的安全扫描,其目的是检测潜在的时间并对未来的系统加固提供建议.这款软件会扫描一般系统信息,脆弱软件包以及 ...
随机推荐
- 基于rv1126 rkmeida 一路多出 原理
基于rv1126 rkmeida 一路多出的坑 首先说要的是介绍一下rkmedia 相关内容 RKMedia提供了一种媒体处理方案,可支持应用软件快速开发.RKMedia在各模块基础API上做进一 ...
- windows系统python3.6(Anaconda3)安装对应版本 torch、torchvision
一.官网下载 .whl 文件 https://download.pytorch.org/whl/torch_stable.html 二.使用pip命令安装 打开你的anaconda,选择对应虚拟环境终 ...
- Java面试题【4】
28)Java 栈和堆的区别 1 栈:为编译器自动分配和释放,如函数参数.局部变量.临时变量等等 2 堆:为成员分配和释放,由程序员自己申请.自己释放.否则发生内存泄露.典型为使用new申请的堆内容. ...
- Linux下Bochs,NASM安装和使用
安装环境 以Ubuntu为例,先更新一下: sudo apt-get update sudo apt-get upgrade 然后安装Bochs环境: sudo apt-get install bui ...
- #dp#nssl 1478 题
分析 设\(f[i]\)表示第\(i\)个是否幸存,\(dp[i][j]\)表示若第\(i\)个幸存,第\(j\)个是否必死 倒序枚举人,如果存在\(dp[i][a[x]],dp[i][b[x]]\) ...
- 【LGR-069】洛谷 2 月月赛 II & EE Round 2
目录 前言 洛谷 6101 [EER2]出言不逊 分析 代码 洛谷 6102 [EER2]谔运算 分析 代码 洛谷 6103 [EER2] 直接自然溢出啥事没有 分析 代码 洛谷 6105 [Ynoi ...
- #树状数组,CDQ分治#洛谷 4390 [BOI2007]Mokia 摩基亚
题目 分析 考虑离线处理,那么询问区间和就可以转换为四个询问, CDQ分治按横坐标处理询问,树状数组维护前缀和就可以了 代码 #include <cstdio> #include < ...
- 【Learning eBPF-3】一个 eBPF 程序的深入剖析
从这一章开始,我们先放下 BCC 框架,来看仅通过 C 语言如何实现一个 eBPF.如此一来,你会更加理解 BCC 所做的底层工作. 在这一章中,我们会讨论一个 eBPF 程序被执行的完整流程,如下图 ...
- 使用GUI--tkinter 制作一个批量修改文件名的桌面软件
''' title:批量修改文件名称 author:huyang createtime:2021-01-29 14:50:00 ''' from tkinter import * from tkint ...
- Openstack之工作流程
组件 OpenStack的核心部件即包括Nova(用于计算).Keystone(用于身份服务).Neutron(用于网络和地址管理).Cinder(块存储).Swift(对象存储).Glance(镜像 ...