聊聊分布式 SQL 数据库Doris(九)
优化器的作用是优化查询语句的执行效率,它通过评估不同的执行计划并选择最优的执行计划来实现这一目标。
CBO: 一种基于成本的优化器,它通过评估不同查询执行计划的成本来选择最优的执行计划。CBO会根据数据库系统定义的统计信息以及其他因素,对不同的执行计划进行评估,并选择成本最低的执行计划。CBO的目标是找到一个最优的执行计划,使得查询的执行成本最低。
RBO: 一种基于规则的优化器,它通过应用一系列的优化规则来选择最优的执行计划。RBO会根据预定义的规则对查询进行优化,这些规则基于数据库系统的特定逻辑和语义。RBO的优点是实现简单,适用于特定的查询模式和数据分布。然而,RBO可能无法找到最优的执行计划,特别是对于复杂的查询和大规模的数据集。
Doris主要整合了Google Mesa(数据模型),Apache Impala(MPP查询引擎)和Apache ORCFile (存储格式,编码和压缩) 的技术。 Doris的查询优化器则是基于Impala改造实现的。Doris官方提供的 Nereids优化器 文档。
优化器组件
查询优化器由多个部分组成,分别是: 词法语法解析、语义解析、query改写、生成执行计划。最后这步根据算法实现与业务场景的不同会有些许差异。
词法语法解析
这个步骤,其实是做两件事情,首先是解析SQL文本,提取关键字出来,比如(select、from等); 然后分析SQL文本是否满足SQL语法,最终生成一个AST树。其结构如下:
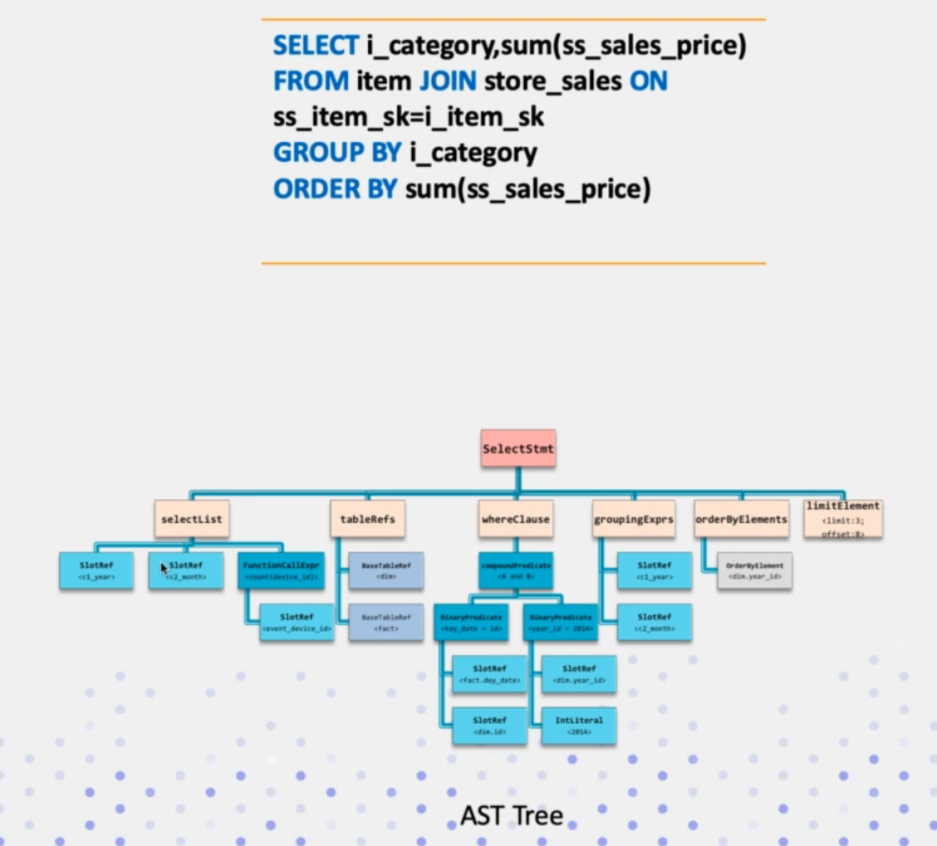
对于不同类型的SQL,其语法树的根节点类型也是不一样的。一般是InsertStmt、UpdateStmt、DeleteStmt、SelectStmt等。而这些概念其实是impala中的,Doris的SQL查询引擎是参考自impala。在其源码中有这么一段注释:
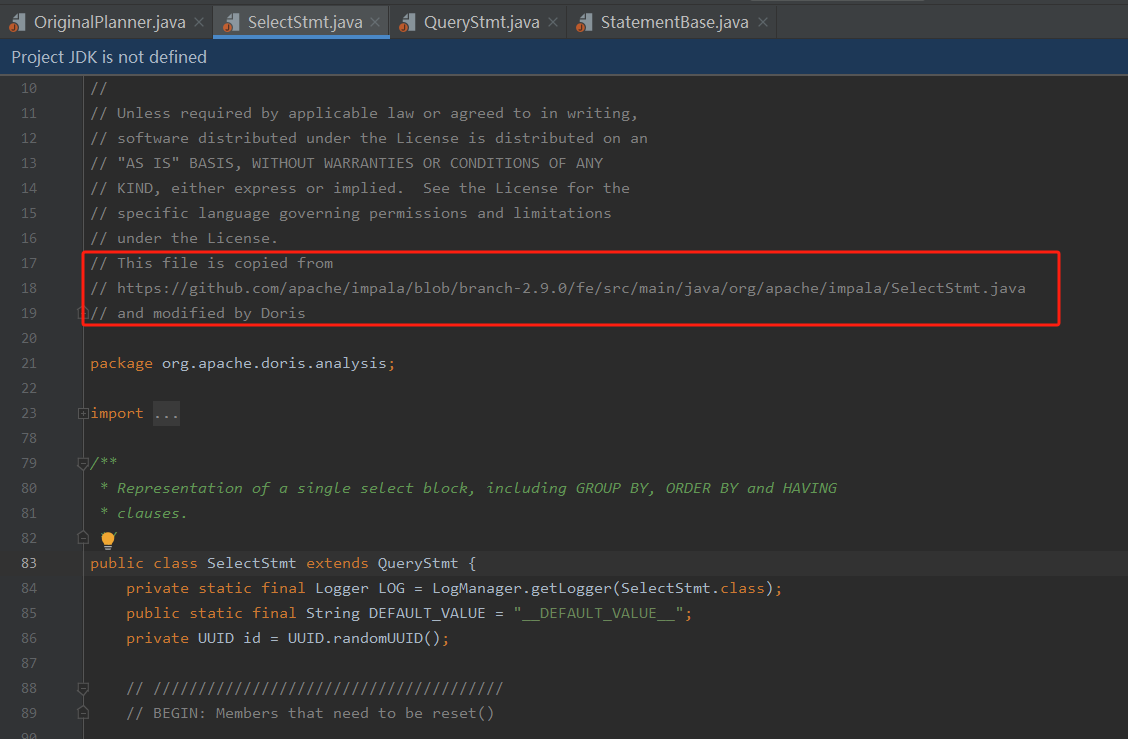
Impala是用于处理存储在Hadoop集群中的大量数据的MPP(大规模并行处理)sql查询引擎。 它是一个用C ++和Java编写的开源软件。 与其他Hadoop的SQL引擎相比,它提供了高性能和低延迟。其相关信息及文档可参考: impala中文手册
语义解析
根据AST树与元数据中的表、列信息等做一个语义校验,比如,表、字段是否在元数据中存在。其步骤一般如下:
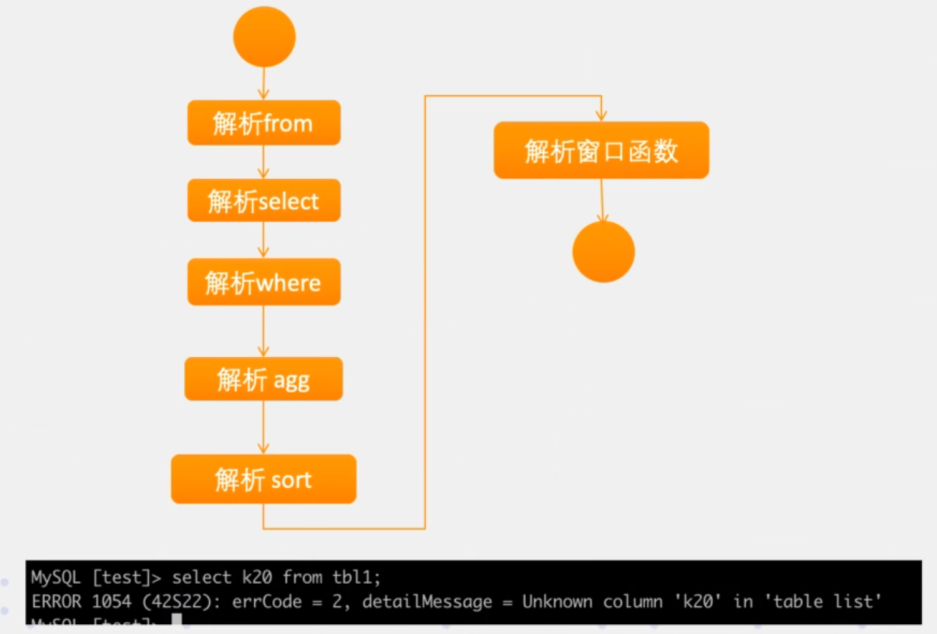
query改写
对原始的sql文本做一定程度的改写使得SQL更简单,执行效率更高;一般是条件表达式改写、子查询改写等。
在Doris中,有一个接口 ExprRewriteRule 负责表达式的改写规则,基于该接口与各种不同的规则有不同的实现,在 Analyzer类的内部类 GlobalState 构造函数中,注册了诸多的规则到rules集合中,而该list会被传递到ExprRewriter类中被应用。
StmtRewriter 类处理子查询改写逻辑,其中的方法会处理各种场景下的子查询改写,比如rewriteSelectStatement方法.
这一步骤的处理是基于词法语法解析后生成的AST树进行的。
public class GlobalState(Env env, ConnectContext context) {
this.env = env;
this.context = context;
List<ExprRewriteRule> rules = Lists.newArrayList();
// BetweenPredicates must be rewritten to be executable. Other non-essential
// expr rewrites can be disabled via a query option. When rewrites are enabled
// BetweenPredicates should be rewritten first to help trigger other rules.
rules.add(BetweenToCompoundRule.INSTANCE);
// Binary predicates must be rewritten to a canonical form for both predicate
// pushdown and Parquet row group pruning based on min/max statistics.
rules.add(NormalizeBinaryPredicatesRule.INSTANCE);
// Put it after NormalizeBinaryPredicatesRule, make sure slotRef is on the left and Literal is on the right.
rules.add(RewriteBinaryPredicatesRule.INSTANCE);
rules.add(RewriteImplicitCastRule.INSTANCE);
rules.add(RoundLiteralInBinaryPredicatesRule.INSTANCE);
rules.add(FoldConstantsRule.INSTANCE);
rules.add(EraseRedundantCastExpr.INSTANCE);
rules.add(RewriteFromUnixTimeRule.INSTANCE);
rules.add(CompoundPredicateWriteRule.INSTANCE);
rules.add(RewriteDateLiteralRule.INSTANCE);
rules.add(RewriteEncryptKeyRule.INSTANCE);
rules.add(RewriteInPredicateRule.INSTANCE);
rules.add(RewriteAliasFunctionRule.INSTANCE);
rules.add(RewriteIsNullIsNotNullRule.INSTANCE);
rules.add(MatchPredicateRule.INSTANCE);
rules.add(EliminateUnnecessaryFunctions.INSTANCE);
List<ExprRewriteRule> onceRules = Lists.newArrayList();
onceRules.add(ExtractCommonFactorsRule.INSTANCE);
onceRules.add(InferFiltersRule.INSTANCE);
exprRewriter = new ExprRewriter(rules, onceRules);
// init mv rewriter
List<ExprRewriteRule> mvRewriteRules = Lists.newArrayList();
mvRewriteRules.add(new ExprToSlotRefRule());
mvRewriteRules.add(ToBitmapToSlotRefRule.INSTANCE);
mvRewriteRules.add(CountDistinctToBitmapOrHLLRule.INSTANCE);
mvRewriteRules.add(CountDistinctToBitmap.INSTANCE);
mvRewriteRules.add(NDVToHll.INSTANCE);
mvRewriteRules.add(HLLHashToSlotRefRule.INSTANCE);
mvExprRewriter = new ExprRewriter(mvRewriteRules);
// context maybe null. eg, for StreamLoadPlanner.
// and autoBroadcastJoinThreshold is only used for Query's DistributedPlanner.
// so it is ok to not set autoBroadcastJoinThreshold if context is null
if (context != null) {
// compute max exec mem could be used for broadcast join
long perNodeMemLimit = context.getSessionVariable().getMaxExecMemByte();
double autoBroadcastJoinThresholdPercentage = context.getSessionVariable().autoBroadcastJoinThreshold;
if (autoBroadcastJoinThresholdPercentage > 1) {
autoBroadcastJoinThresholdPercentage = 1.0;
} else if (autoBroadcastJoinThresholdPercentage <= 0) {
autoBroadcastJoinThresholdPercentage = -1.0;
}
autoBroadcastJoinThreshold = (long) (perNodeMemLimit * autoBroadcastJoinThresholdPercentage);
} else {
// autoBroadcastJoinThreshold is a "final" field, must set an initial value for it
autoBroadcastJoinThreshold = 0;
}
}
单机执行计划
这一过程会生成PlanNodeTree,一般用于处理Join Reorder场景下的join调优与谓词下推等下推优化。
SingleNodePlanner类用于生成单击执行计划,该类其实也是基于impala框架改写适用于Doris的。在这个类中,除了谓词下推与join reorder外,还有类似列裁剪之类的优化,都在这个类中有处理。
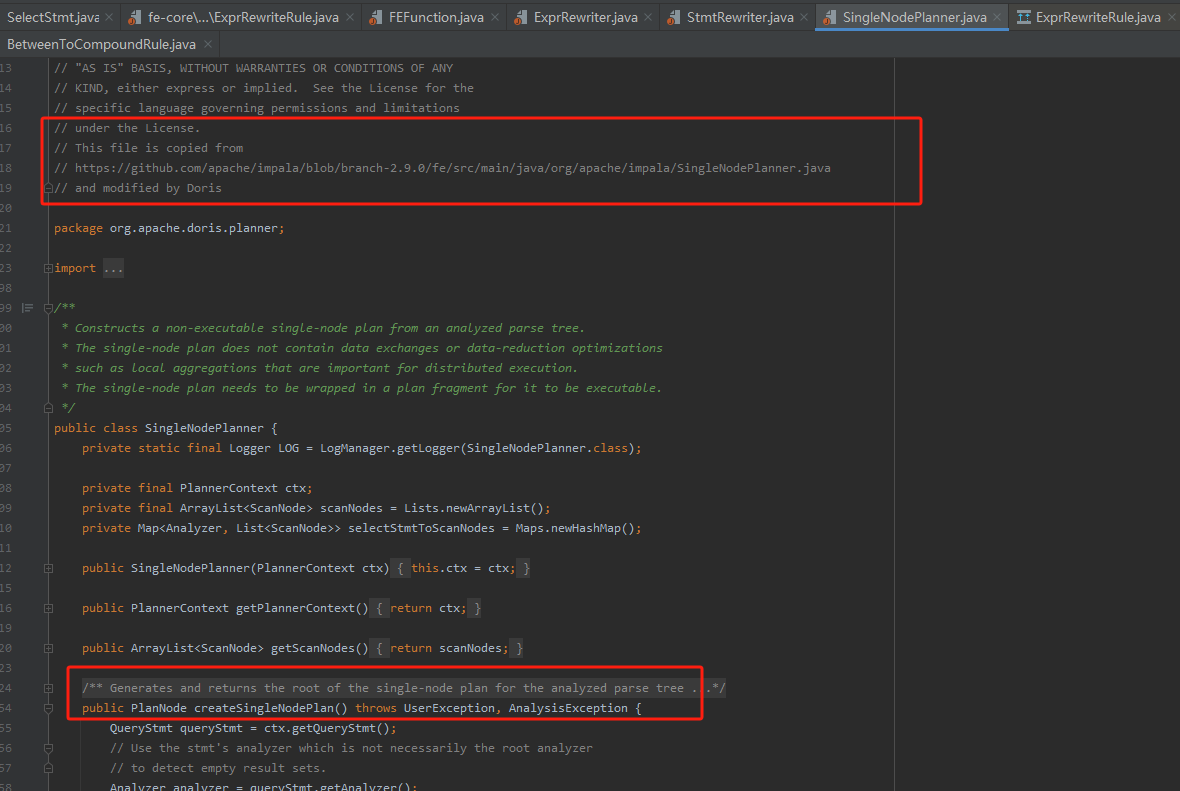
分布式执行计划
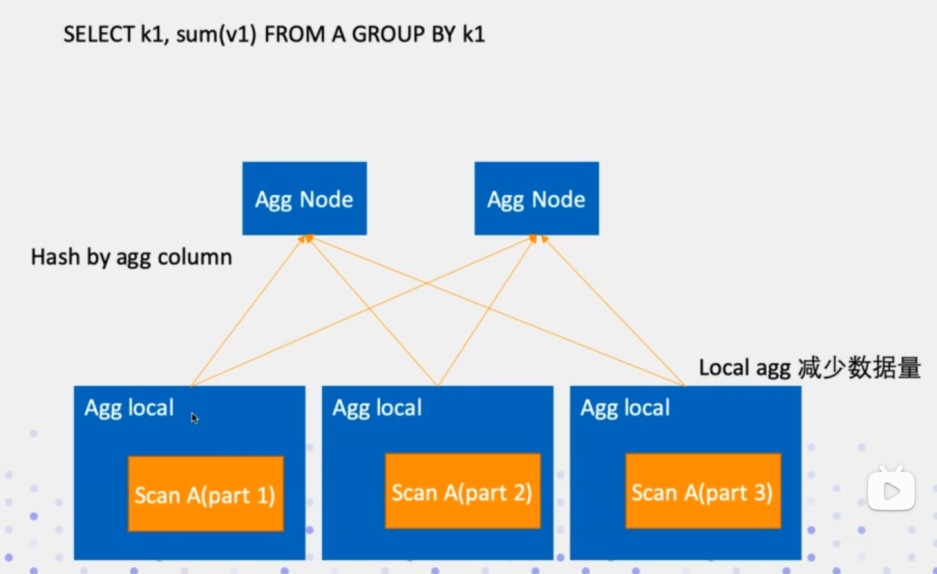
DistributedPlanner类负责分布式执行计划的优化,其中会处理Join场景下的分布式执行,选择最优的Join执行路径;其次就是Agg聚合函数的分布式执行逻辑,Agg会分两步执行,先会在local本地scan,然后再Agg Node上在做一次scan聚合;当然还有一些算子需要做分布式逻辑执行优化. 都可以在这个类中找到。当然这个类也是基于impala框架改写的。
如下是AggNode的分布式执行计划优化:
总结
Doris的很多设计,其实都是有据可依,参考借鉴已有的框架/论文,再依据实际的业务场景做改写;这也正是我们要学习了解的东西,通过一个点,然后铺开去了解学习相关的其他点,慢慢的串联起来形成面。查询优化器结合如下博客再加上自己去阅读一下代码,对整个脉络及机制就算是掌握了。
聊聊分布式 SQL 数据库Doris(五) 这是之前写的对查询优化器相关的一些知识普及.
查询优化器详解 Doris团队针对查询优化器的视频讲解.
Doris SQL 原理解析 小米工程师写的,更深入的剖析.
聊聊分布式 SQL 数据库Doris(九)的更多相关文章
- 分布式SQL数据库中部分索引的好处
在优锐课的java学习分享中,探讨了分布式SQL数据库中部分索引的优势,并探讨了性能测试,结果等. 如果使用局部索引而不是常规索引,则在可为空的列上(其中只有一小部分行的该列不具有空值),然后可以大大 ...
- 保姆级教程!手把手教你使用Longhorn管理云原生分布式SQL数据库!
作者简介 Jimmy Guerrero,在开发者关系团队和开源社区拥有20多年的经验.他目前领导YugabyteDB的社区和市场团队. 本文来自Rancher Labs Longhorn是Kubern ...
- CockroachDB学习笔记——[译]The New Stack:遇见CockroachDB,一个弹性SQL数据库
原文链接:https://www.cockroachlabs.com/blog/the-new-stack-meet-cockroachdb-the-resilient-sql-database/ 原 ...
- 【原创】分布式之数据库和缓存双写一致性方案解析(三) 前端面试送命题(二)-callback,promise,generator,async-await JS的进阶技巧 前端面试送命题(一)-JS三座大山 Nodejs的运行原理-科普篇 优化设计提高sql类数据库的性能 简单理解token机制
[原创]分布式之数据库和缓存双写一致性方案解析(三) 正文 博主本来觉得,<分布式之数据库和缓存双写一致性方案解析>,一文已经十分清晰.然而这一两天,有人在微信上私聊我,觉得应该要采用 ...
- Spring Cloud Config(一):聊聊分布式配置中心 Spring Cloud Config
目录 Spring Cloud Config(一):聊聊分布式配置中心 Spring Cloud Config Spring Cloud Config(二):基于Git搭建配置中心 Spring Cl ...
- Google的分布式关系型数据库F1和Spanner
F1是Google开发的分布式关系型数据库,主要服务于Google的广告系统.Google的广告系统以前使用MySQL,广告系统的用户经常需要使用复杂的query和join操作,这就需要设计shard ...
- 分布式MySQL数据库TDSQL架构分析
摘要:腾讯计费平台部为了解决基于内存的NoSQL解决方式HOLD平台在应对多种业务接入时的不足.结合团队在MySQL领域多年应用和优化经验,终于在MySQL存储引擎基础上,打造一套分布式SQL系统TD ...
- SQL数据库的基础操作
一,认识SQL数据库 美国Microsoft公司推出的一种关系型数据库系统.SQLServer是一个可扩展的.高性能的.为分布式客户机/服务器计算所设计的数据库管理系统,实现了与WindowsNT的有 ...
- DRDS分布式SQL引擎—执行计划介绍
摘要: 本文着重介绍 DRDS 执行计划中各个操作符的含义,以便用户通过查询计划了解 SQL 执行流程,从而有针对性的调优 SQL. DRDS分布式SQL引擎 — 执行计划介绍 前言 数据库系统中,执 ...
- ASP.NET动态网站制作(15)-- SQL数据库(1)
前言:数据库(Database)是按照数据结构来组织.存储和管理数据的仓库,用户可以对文件中的数据进行增.删.改.查.数据库有很多种类型,从简单的存储有各种数据的表格到能都进行海量数据存储的大型数据库 ...
随机推荐
- quarkus依赖注入之十一:拦截器高级特性上篇(属性设置和重复使用)
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本篇是<quarkus依赖注入> ...
- 三维模型OBJ格式轻量化压缩处理的数据质量提升方法分析
三维模型OBJ格式轻量化压缩处理的数据质量提升方法分析 在三维模型的OBJ格式轻量化压缩处理过程中,除了减小文件大小和提高加载速度之外,我们也需要考虑如何提升数据质量.以下是几种常见的方法: 1.优化 ...
- 【NestJS系列】核心概念:Middleware中间件
前言 用过express与koa的同学,对中间件这个概念应该非常熟悉了,中间件可以拿到Request.Response对象和next函数. 一般来讲中间件有以下作用: 执行任何代码 对请求与响应拦截并 ...
- 关于API数据接口获取商品的数据的说明
获取商品数据已经成为许多应用程序的重要组成部分.为了实现这一目标,许多公司和技术开发者使用API数据接口来获取相关数据.本文将详细介绍如何使用API数据接口获取商品数据,并使用Python作为编程 ...
- API接口设计规范
说明:在实际的业务中,难免会跟第三方系统进行数据的交互与传递,那么如何保证数据在传输过程中的安全呢(防窃取)?除了https的协议之外,能不能加上通用的一套算法以及规范来保证传输的安全性呢? 下面我们 ...
- Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.so
在安装Docker以后,执行命令出现错误. Got permission denied while trying to connect to the Docker daemon socket at u ...
- mysql 大表如何ddl 👑
大家好,我是蓝胖子,mysql对大表(千万级数据)的ddl语句,在生产上执行时一定要千万小心,一不小心就有可能造成业务阻塞,数据库io和cpu飙高的情况.今天我们就来看看如何针对大表执行ddl语句. ...
- [错误] SQL logic error near "date": syntax error
问题的来源 今天把一个项目的数据库从MySQL改到Sqlite 调试时发生了这个错误. 百度又看不懂英文(很多是国外发的), 就折腾了一下 原因 C# Sqlite 不能使用参数前缀"?&q ...
- 看完这篇HTTP,跟面试官扯皮就没问题了(转)
认识 HTTP 首先你听的最多的应该就是 HTTP 是一种 超文本传输协议(Hypertext Transfer Protocol),这你一定能说出来,但是这样还不够,假如你是大厂面试官,这不可能是他 ...
- JavaCore extends Plugin
/******************************************************************************* 2 * Copyright (c) 2 ...