python进程绑定CPU的意义
1. 绑定CPU后对计算密集型的任务可能会一定程度上提升运算性能:(小幅度的性能提升,甚至小幅度落后,总之就是差别不大)
对比1代码A:
import os
from multiprocessing import Process
from timeit import timeit
import numpy as np
cpu_avia = os.sched_getaffinity(os.getpid())
os.sched_setaffinity(os.getpid(), list(cpu_avia)[:1]) # 绑定两个核心
def func():
s = np.random.random(100)
for _ in range(10000000):
s += np.random.random(100)
t = timeit('func()', "from __main__ import func", number=100)
print(t)运行时间:
2340.2266417220235
对比1代码B:
import os
from multiprocessing import Process
from timeit import timeit
import numpy as np
def func():
s = np.random.random(100)
for _ in range(10000000):
s += np.random.random(100)
t = timeit('func()', "from __main__ import func", number=100)
print(t)运行时间:
2321.7808491662145
==========================
对比2代码A:
import os
from multiprocessing import Process
from timeit import timeit
import numpy as np
cpu_avia = os.sched_getaffinity(os.getpid())
os.sched_setaffinity(os.getpid(), list(cpu_avia)[:1]) # 绑定两个核心
def func():
s = np.random.random(100)
for _ in range(1000000000):
s += np.random.random(100)
t = timeit('func()', "from __main__ import func", number=1)
print(t)运行时间:
2405.4125552885234
对比2代码B:
import os
from multiprocessing import Process
from timeit import timeit
import numpy as np
def func():
s = np.random.random(100)
for _ in range(1000000000):
s += np.random.random(100)
t = timeit('func()', "from __main__ import func", number=1)
print(t)运行时间:
2415.607121781446
可以说,绑定CPU其实对于算法的运行性能影响不大,即使有提升也是微乎其微的。但是对于绑定CPU的作用个人认为还是分隔计算资源才是最有用的应用,这就是本文要说的第二点。
-----------------------------------------
2. 绑定CPU后可以实现计算资源的分隔
场景:
1. 一个主机有8个CPU内核,现在计划用4个CPU内核运行生产者进程,另外4个CPU内核运行消费者进程。
2. 消费者进程为每个CPU核心上运行一个消费者进程,因为消费者进程为计算密集型任务,为保证消费者进程不被生产者进程抢占计算资源,因此把CPU核心0-3绑定给生产者进程,CPU核心4-7绑定给消费者进程。消费者进程共有4个。
3. 生产者进程需要接收网络数据并进行数据处理,然后把处理后的数据通过进程消息队列的方式传输给消费者进程;消费者进程则不断的从消息队列中读取数据进行下一步的处理。
4. 生产者进程需要接收的网络源有100个,即socket要开100个。
解决方案1:
为生产者进程单独设置一个网络数据接收进程,由该进程接收网络数据,然后把网络数据传递给生产者进程,这样生产者进程的进程数量设置为4个即可以保证绑定的CPU核心达到充分的利益。此时网络IO操作由网络接收进程负责,数据处理的计算任务由4个生产进程负责。该种设计简单的说就是生产者部分设置一个网络接收进程和4个生产者进程。大致总体设计如下:
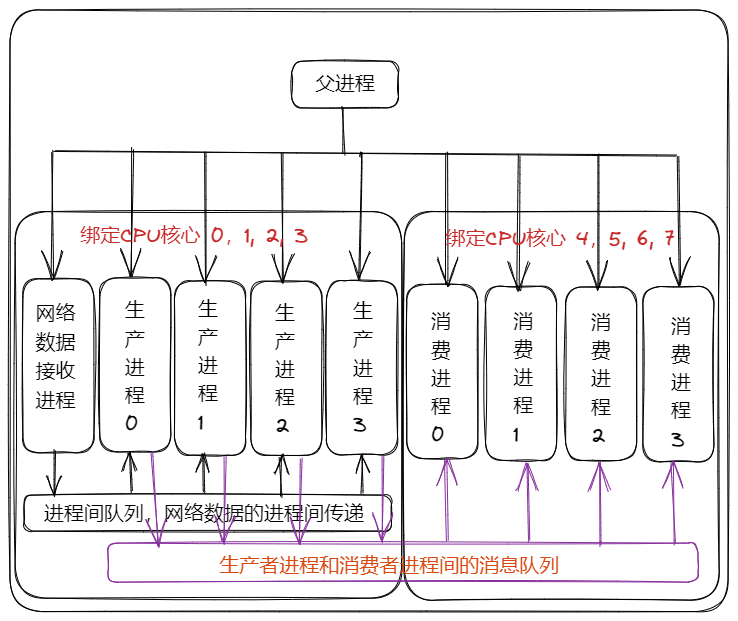
此时又出现了新的问题,那就是网络数据接收进程如何维护对100个socket数据的读取操作,使用轮询机制还是多线程阻塞等待,还是用异步的方式,不同的方式性能会有如何的影响。
对于网络数据接收进程来说,设计性能最高的方式就是使用异步的方式,而设计操作最简单的就是多线程的方式。
解决方案2:
方案2其实是对方案1的改进和补充,方案1中生产者部分中单独采用了一个网络数据接受进程,然后由该进程接收数据后再传递给其他生产者进程,但是如果由于某些原因,如数据量较大、数据难以进行序列化等原因难以进行进程间传递,因此给出方案2。
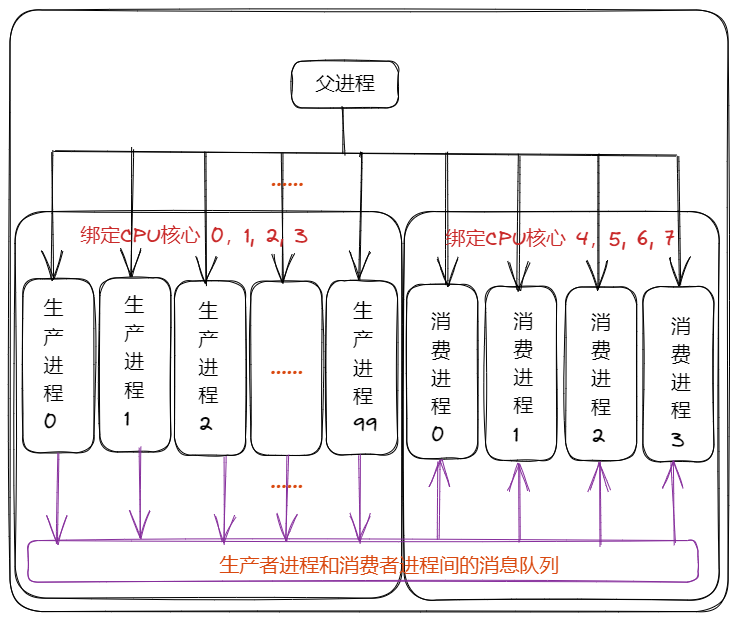
该种设计就是不使用网络数据接收进程,而是使用多个生产者进程的方式,每个生产者进程均负责一个socket数据的接收和处理。该种设计还是较大程度上依赖CPU锁定的设置,因为如果不是把这100个生产者进程锁定在0,1,2,3号CPU核心上,那么必然会出现100个进程同时进行数据处理而抢占消费者进程的计算资源的情况。
该种设计的最大好处就是简单,在编写具体代码的时候可以比较简单的快速完成;但是该种设置的最大坏处就是扩展性的问题,如果socket源过多,那么我们就需要建立大量的生产者进程,而大量的生产者进程进行切换的时候必然会占用资源,也就是说该种设计会随着生产进程数量的增加而极大的损失掉总体的性能。
这里再给出一个折中的方案,那就是在生产者进程中使用多线程或者异步,如下图:
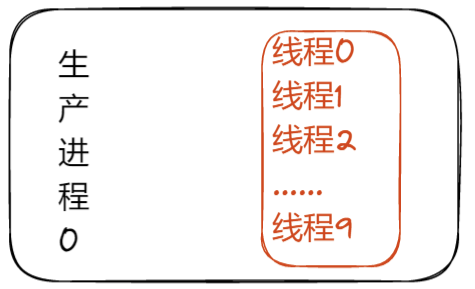
一个生产者进程中带有10个线程,10个线程分别监听10个socket,当然这里也可以使用异步方式来解决。
PS: 之所以有上面复杂的几种方案,归根到底就是因为python的多线程不能并发执行,多进程之间通信会造成性能损耗以及多方面的限制问题。
=====================================
相关:
python进程绑定CPU的意义的更多相关文章
- linux下进程绑定cpu情况查看的几种方法
1.pidstat命令 查看进程使用cpu情况,如果绑定了多个cpu会都显示出来 pidstat -p `pidof 进程名` -t 1 2.top命令 (1)top (2)按f键可以选择下面配置选项 ...
- NGINX源代码剖析 之 CPU绑定(CPU亲和性)
作者:邹祁峰 邮箱:Qifeng.zou.job@gmail.com 博客:http://blog.csdn.net/qifengzou 日期:2014.06.12 18:44 转载请注明来自&quo ...
- Ubuntu系统进程绑定CPU核
Ubuntu系统进程绑定CPU核 作者:chszs.版权全部,未经允许,不得转载. 博主主页:http://blog.csdn.net/chszs 本文讲述如何在Ubuntu系统中,把指定的进程绑定到 ...
- Linux编程之《进程/线程绑定CPU》
Intro----- 通常我们在编写服务器代码时,可以通过将当前进程绑定到固定的CPU核心或者线程绑定到固定的CPU核心来提高系统调度程序的效率来提高程序执行的效率,下面将完整代码贴上. /***** ...
- Nginx 关于进程数 与CPU核心数相等时,进程间切换的代价是最小的-- 绑定CPU核心
在阅读Nginx模块开发与架构模式一书时: "Nginx 上的进程数 与CPU核心数相等时(最好每个worker进程都绑定特定的CPU核心),进程间切换的代价是最小的;" &am ...
- Linux 和 Windows 查看当前运行的 python 进程及 GPU、CPU、磁盘利用率
目录 查看当前 python 进程 Linux Windows 查看 GPU 利用率 Linux Windows Linux CPU 利用率 Linux 磁盘利用率 查看当前 python 进程 Li ...
- 线程或进程绑定到特定的cpu
常用的宏定义有: 1) 对cpu集进行初始化, 将其设置为空集 void CPU_ZERO(cpu_set_t *set); 2) 将指定的cpu加入到cpu集中 void CPU_SET(int c ...
- 【笔记】Linux进程间同步和进程绑定至特定cpu
#define _GNU_SOURCE #include <stdio.h> #include <sys/types.h> #include <sys/stat.h> ...
- Python测试进阶——(5)Python程序监控指定进程的CPU和内存利用率
用Python写了个简单的监控进程的脚本monitor190620.py,记录进程的CPU利用率和内存利用率到文件pid.csv中,分析进程运行数据用图表展示. 脚本的工作原理是这样的:脚本读取配置文 ...
- python 进程和线程-线程和线程变量ThreadLocal
线程 线程是由若干个进程组成的,所以一个进程至少包含一个线程:并且线程是操作系统直接支持的执行单元.多任务可以由多进程完成,也可由一个进程的多个线程来完成 Python的线程是真正的Posix Thr ...
随机推荐
- vue判断开始日期不能大于截至日期
method下的方法: checkTime() { var start = new Date(this.form.startDate).getTime() var end = new Date(thi ...
- 泛型模板化设计DEMO
泛型模板化设计DEMO 1. 定义Result泛型类 package com.example.core.mydemo.java.fanxing; public class Result<T> ...
- Lecture3
Smiling & Weeping ---- 蝴蝶在双翼里藏匿夏的脉络 妄图在绿意中品鉴隆冬 第三章 Git分支管理 3.1 分支的简介 Git最重要的运用场景是多人协同开发,但是如何能保证每 ...
- 通俗理解GAN -- 基础认知
Smiling & Weeping ---- 你已春风摇曳,我仍一身旧雪 1.GAN的基本思想 GAN全称对抗生成网络,顾名思义是生成模型的一种,而他的训练则是一种对抗博弈状态中的.下面我们举 ...
- 前端Uncaught (in promise) 的解决方法及原因
问题:在Vue项目中使用axios调用一个第三方的接口时,前端无法获取到接口返回值,检查控制台Network发现接口请求已经正常发出并且有数据返回,但是控制台Console报了这么一个错误 上图可以看 ...
- 浅析Vite本地构建原理
前言 随着Vue3的逐渐普及以及Vite的逐渐成熟,我们有必要来了解一下关于vite的本地构建原理. 对于webpack打包的核心流程是通过分析JS文件中引用关系,通过递归得到整个项目的依赖关系,并且 ...
- 2020-2021 ICPC, NERC, Northern Eurasia Onsite BEIJ 题解
B. Button lock 题意:有 \(d\) 个 01 按键以及一个 reset 按键,你需要把所有题目给定的 \(n\) 个密码全部表示一遍.只有按下 reset 按键后才能使所有 01 按键 ...
- 高通Andriod开机流程与镜像说明
# 高通Andriod开机流程与镜像说明 Android镜像说明 Android设备刷机时都需要ROM包,ROM包下面有很多的.img和其他的相关镜像文件,其中这里面包含了Android很多的分区,A ...
- 安卓Camera-HAL显示值与比例
安卓Camera-HAL显示值与比例 参考:https://blog.csdn.net/wang714818/article/details/78049649?utm_source=blogxgwz4 ...
- Linux系统获取开发板的文件系统并打包成img文件
应用情形: 在实际的开发中,由于原系统包含的功能有限,而根据项目的需要,安装了相应的库及运行项目程序所创建的各种文件,和所做 的各种配置,想将调试好的系统打包发布,进行批量生产,就可参考本文提供的方法 ...