最佳实践:解读GaussDB(DWS) 统计信息自动收集方案
摘要:现在商用优化器大多都是基于统计信息进行查询代价评估,因此统计信息是否实时且准确对查询影响很大,特别是分布式数据库场景。本文详细介绍GaussDB(DWS)如何实现了一种轻量、实时、准确的统计信息自动收集方案。
本文分享自华为云社区《【最佳实践】GaussDB(DWS) 统计信息自动收集方案》,作者: leapdb。
一、统计信息收集痛点
- 何时做analyze,多做空耗系统资源,少做统计信息不及时。
- 多个数据源并发加工一张表,手动analyze不能并发。
- 数据修改后立即查询,统计信息实时性要求高。
- 需要关心每张表的数据变化和治理,消耗大量人力。
二、基本功能介绍
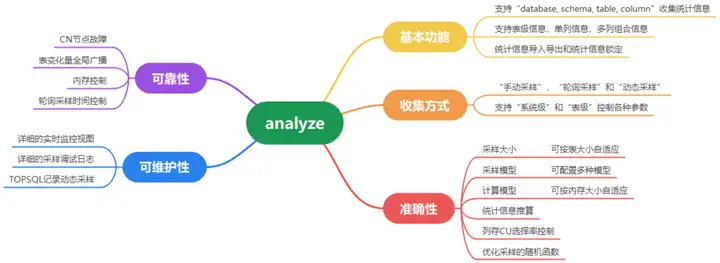
三、自动收集方案
GaussDB(DWS) 支持统计信息自动收集功能,主要解决统计信息收集不及时和不准确的问题。
手动采样:用户在作业中,手动发起的显示analyze。
轮询采样:autovacuum后台线程,轮询发起的analyze。
动态采样:查询时,优化器触发的runtime analyze。
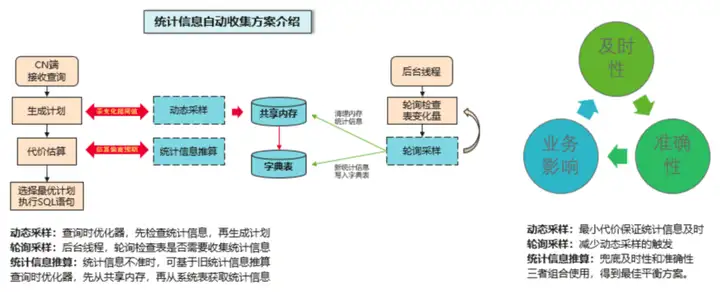
前台动态采样:负责统计信息实时准确,信息放内存(有淘汰机制),一级锁(像查询一样轻量)。
autoanalyze=on;
autoanalyze_mode='light';
后台轮询采样:负责统计信息的持久化,写系统表(四级锁),不要求特别及时。
autovacuum_mode=mix或analyze;
--- 以前只有“后台轮询采样”,都由后台autovacuum线程控制做vacuum或analyze。
--- 后来开发“前台动态采样”,叫autoanalyze。
--- 请注意二者的区别。
二者都需要开启。
替代场景
统计信息基于收集时表数据生成,数据变化较多后可能失效。自动触发也是基于阈值(50+表大小*10%)。
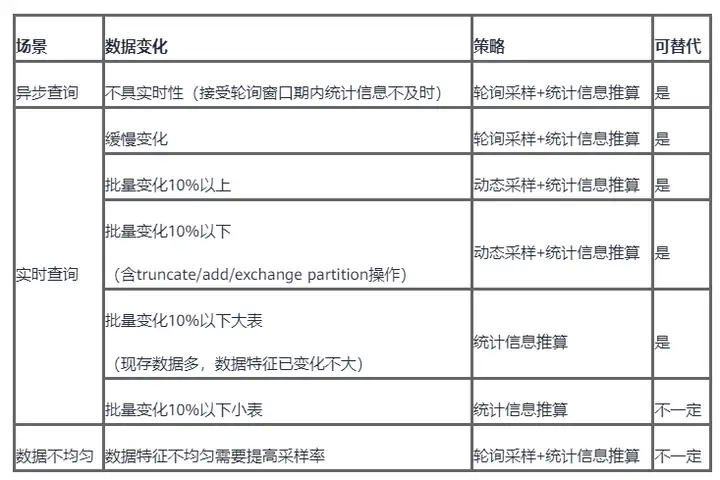
总结:
- 小表变化<10%且数据特征变化明显,需要“调低阈值自动收集”。
- 调整过采样大小且实时性要求高的场景,需要“主动收集统计信息”。
- 外表和冷热表因访问性能问题,不支持自动,需要“主动收集统计信息”。
四、如何保证及时触发
【触发条件】“无统计信息” or “表的修改量超过一定阈值(默认“50 + 表大小 * 10%”)”
【触发场景】含stream计划的SQL都可触发动态采样,包括select和带条件的delete, update。
【修改计数】
1. 哪些修改行为会被记录?
DML: Insert, Update, Delete, Copy, Merge,会累加修改计数。
DDL: truncate table,truncate/exchange/drop partition, alter column type, alter distribute,由于CN无法获取DN修改计数,所以直接记录一个超大修改计数。
2. 跨CN查询场景,如何确保修改计数全局一致?
异步广播:autovacuum后台线程轮询检查时,向所有CN广播全局修改计数。修改计数达2/3时广播一次,此后每增10%再广播一次。
实时广播:单SQL修改超过tuple_change_sync_threshold(默认1W)条时,直接实时广播修改计数到其它CN。
总结:“修改计数记录”和“修改计数广播”,覆盖都比较全面,能够保证查询及时触发动态采样。
五、最佳实践
GaussDB(DWS) analyze使用指南8.1.3及以下版本
GaussDB(DWS) analyze使用指南8.2.0及以上版本
1.事务块中手动analyze堵塞其它业务
【业务场景】

BEGIN;
ANALYZE t_ucuser;
INSERT INTO t_user_name(project_id, account_id, name_id, uid, etl_time)
with t1 AS (
select project_id, account_id, name_id
from t_user_name
WHERE uid is null or uid = ''
)
select a.project_id,a.account_id,a.name_id, b.user_name AS uid, CURRENT_TIMESTAMP AS etl_time
from t1 a join t_ucuser b ON a.project_id = b.project_id AND a.account_id = b.account_id
ON CONFLICT(project_id,account_id,name_id) DO UPDATE
SET project_id=excluded.project_id, account_id=excluded.account_id, name_id=excluded.name_id, uid=excluded.uid, etl_time=excluded.etl_time;
END;
【问题根因】
a. 某数据湖用户,多个数据源按照不同的分区进行数据导入加工。
b. 事务块中有手动analyze,且事务块中后面的查询长时间执行不完。
c. 因analyze对表加四级锁长时间不能释放,导致其它相关表上的业务等锁超时报错。
【解决方案】开启light动态采样,去掉事务块中的手动analyze。
2. 多数据源并发加工同一张表的不同分区
【业务场景】
为了保证用户查询表总有数据,需要把加工过程放到一个事务里面。堵塞其它人的动态采样。
begin;
alter table tab_partition truncate partition P2023_03;
insert into tab_partition select * from t1;
end;
【问题根因】alter table truncate parition对分区加8级锁,事务过程中长时间持锁。
【解决方案】使用exchange partition
CREATE TABLE IF NOT EXISTS tab_tmp1(like tab_partition INCLUDING DROPCOLUMNS INCLUDING DISTRIBUTION INCLUDING STORAGE INCLUDING RELOPTIONS);
INSERT INTO tab_tmp1 SELECT * FROM t1;
ALTER TABLE tab_partition exchange partition (P2023_03) WITH TABLE tab_tmp1;
3.多表并发反序analyze导致统计信息收集失败
【业务场景】
a. 某银行客户,多个表进行批处理数据加工,开启了normal类型动态采样。
b. 查询A先对t1表触发动态采样,再对t2表触发动态采样。
c. 查询B先对t2表触发动态采样,再对t1表触发动态采样。
d. 触发动态采样的顺序不一致,互相申请四级锁导致申锁超时,统计信息未收集。
【问题根因】多人同时按不同顺序analyze多表导致死锁。
【解决方案】开启light动态采样,仅加一级锁不再有四级锁冲突。
4.刚导入的数据不在统计信息中导致查询计划差
【业务场景】
a. 某财经用户,按照月度视为会计期,月初时导入少量数据,然后马上查询。
b. 触发了动态采样,但采集不到最新会计期的少量数据。
【问题根因】新插入数据占比小,及时触发了动态采样但采集不到,导致估算偏差大。
【解决方案】
a. 开启统计信息推算enable_extrapolation_stats功能,根据上一个会计期的统计信息推算当前会计期数据特征。
b. 不提高采样大小,利用历史信息增强统计信息准确性。
5.随机函数质量差导致数据特征统计不准
【业务场景】
a. 某银行客户,按月度条件进行关联查询
b. 多次analyze,最多数据月份在MCV中占比从13%~30%大幅波动
c. 详细输出样本点位置和采样随机数发现,随机数(小数点后6位)生成重复度高导致采样扎堆儿严重。
【问题根因】采样随机数不够随机,样本采集不均匀导致MCV数据特征统计偏差。
【解决方案】
a. 每次传入随机种子再生成随机数,提高随机性和并发能力。控制参数random_function_version。
b. 不提高采样大小,提升随机数质量增强统计信息准确性。
6.样本分布不均匀导致数据特征统计不准
【业务场景】
a. tpc-h的lineitem表l_orderkey列,数据每4~8条批量重复。即同一个订单购买多个商品。
b. 传统采样算法由于采样不均匀,采集到的重复数据稍多,导致采集的distinct值偏低。
【问题根因】数据特征分布不均匀,采样无法抓准数据特征,distinct值高的场景统计出的distinct值偏低。
【解决方案】
a. 使用自研的优化蓄水池采样算法,控制参数analyze_sample_mode=2,让采样更加均匀,以提升统计信息准确性。
b. 如果上述方法没有达到预期效果,可以手动修改distinct值。
select APPROX_COUNT_DISTINCT(l_orderkey) from lineitem; --近似计算distinct值
alter table lineitem alter l_orderkey set (n_distinct=10000); --手动设置distinct值,然后再analyze即可。
最佳实践:解读GaussDB(DWS) 统计信息自动收集方案的更多相关文章
- Oracle 11G统计信息自动收集及调整
查询统计信息的收集所对应的task,以及当前状态 col CLIENT_NAME for a50col TASK_NAME for a20SELECT client_name, task_name, ...
- Android最佳实践之SystemBar状态栏全版本适配方案
前言 自从MD设计规范出来后,关于系统状态栏的适配越受到关注,因为MD在5.0以后把系统状态栏的颜色改为可由开发者配置的,而在5.0之前则无法指定状态栏的颜色,所以这篇就说说使用Toolbar对系统状 ...
- 关于Oracle开启自动收集统计信息的SPA测试
主题:关于Oracle开启自动收集统计信息的SPA测试 环境:Oracle RAC 11.2.0.4(Primary + Standby) 需求:生产Primary库由于历史原因关闭了自动统计信息的收 ...
- 详解GaussDB(DWS) explain分布式执行计划
摘要:本文主要介绍如何详细解读GaussDB(DWS)产生的分布式执行计划,从计划中发现性能调优点. 前言 执行计划(又称解释计划)是数据库执行SQL语句的具体步骤,例如通过索引还是全表扫描访问表中的 ...
- 有关Oracle统计信息的知识点[z]
https://www.cnblogs.com/sunmengbbm/p/5775211.html 一.什么是统计信息 统计信息主要是描述数据库中表,索引的大小,规模,数据分布状况等的一类信息.例如, ...
- 有关Oracle统计信息的知识点
一.什么是统计信息 统计信息主要是描述数据库中表,索引的大小,规模,数据分布状况等的一类信息.例如,表的行数,块数,平均每行的大小,索引的leaf blocks,索引字段的行数,不同值的大小等,都属于 ...
- Oracle中的统计信息
一.什么是统计信息 统计信息主要是描述数据库中表,索引的大小,规模,数据分布状况等的一类信息.例如,表的行数,块数,平均每行的大小,索引的leaf blocks,索引字段的行数,不同值的大小等,都属于 ...
- oracle10g 统计信息查看、收集
1. 统计信息查看 1.1 单个表的全局统计信息.统计效果查看 2. 统计信息分析(收集) 2.1 分析工具选择 2.2 分析前做index重建 2.3 分析某数据表,可以在PL/SQL的comm ...
- Markdown最佳实践
Markdown 最佳实践 结合目前看到的信息,总结使用Markdown的最方便的方式. 我的需求是: 能够配合各种笔记软件使用,目前主要使用的是为知笔记和有道笔记.笔记的内容需要记录代码及数学公式, ...
- oracle的统计信息的查看与收集
查看某个表的统计信息 SQL> alter session set NLS_DATE_FORMAT='YYYY-MM-DD HH24:MI:SS'; Session altered. SQL&g ...
随机推荐
- LocalDateTime日期格式化和指定日期的时分秒
LocalDateTime日期格式化和指定日期的时分秒 package com.example.core.mydemo.date; import java.time.LocalDate; import ...
- hibernate映射对照表
2.3. Basic Types Basic value types usually map a single database column, to a single, non-aggregated ...
- 浅拷贝、深拷贝与序列化【初级Java必需理解的概念】
浅拷贝 首先创建两个类,方便理解浅拷贝 @Data class Student implements Cloneable{ //年龄和名字是基本属性 private int age; private ...
- Qt 应用程序中自定义鼠标光标
在 Qt 应用程序中,你可以自定义鼠标光标.你可以使用 `QCursor` 类来设置不同类型的鼠标光标,比如内置样式或者自定义的图片.以下是一些使用示例: 使用内置光标样式 Qt 提供了一些内置的光标 ...
- Nuxt3 的生命周期和钩子函数(二)
title: Nuxt3 的生命周期和钩子函数(二) date: 2024/6/26 updated: 2024/6/26 author: cmdragon excerpt: 摘要:本文深入介绍了Nu ...
- bs4解析-优美图库
import requests from bs4 import BeautifulSoup url = 'http://www.umeituku.com/bizhitupian/meinvbizhi/ ...
- 【Python】基于动态规划和K聚类的彩色图片压缩算法
引言 当想要压缩一张彩色图像时,彩色图像通常由数百万个颜色值组成,每个颜色值都由红.绿.蓝三个分量组成.因此,如果我们直接对图像的每个像素进行编码,会导致非常大的数据量.为了减少数据量,我们可以尝试减 ...
- Windows批处理文件(.bat和.cmd)
cmd文件和bat文件的区别 从文件描述中的区别是,cmd文件叫做:Windows命令脚本,bat文件叫:批处理文件,两者都可以使用任意一款文本编辑器进行创建.编辑和修改,只是在cmd中支持的命令要多 ...
- var、let、const 区别?
var 存在变量提升.let 只能在块级作用域内访问.const 用来定义常量,必须初始化,不能修改(对象特殊) 1.var[声明变量] var 没有块的概念,可以跨块访问,无法跨函数访问: 2.le ...
- 暑假Java自学每日进度总结1
今日所学: 一.常用的cmd命令: 1>盘符: 2>dir(显示当前文件所有目录) 3>cd 目录(打开该目录) 4>cd..(回到上一目录) 5>cd(回到当前盘符初始 ...