【转载】 Ring Allreduce (深度神经网络的分布式计算范式 -------------- 环形全局规约)
作者:初七123
链接:https://www.jianshu.com/p/8c0e7edbefb9
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
------------------------------------------------------------------------------------
(深度神经网络的分布式计算范式 -------------- 环形全局规约) (副标题 自起)
------------------------------------------------------------------------------------
The Communication Problem
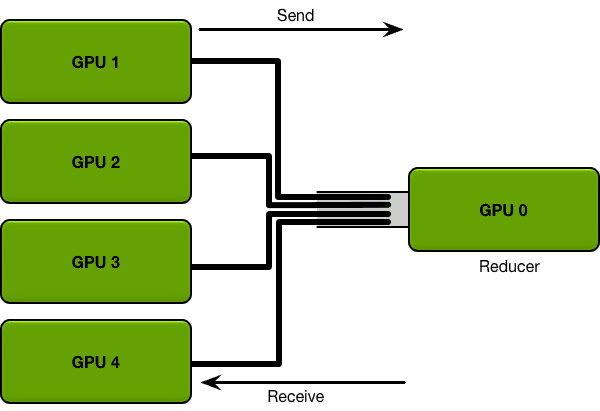
需要发送的数据越多,发送时间就越长;每个通信通道都有一个最大的吞吐量(带宽)。例如,一个好的internet连接可以提供每秒15兆字节的带宽,而千兆以太网连接可以提供每秒125兆字节的带宽。HPC集群上的专用网络硬件(如Infiniband)可以在节点之间提供每秒数gb的带宽。
相反,我们可以通过使用高性能计算领域的分布式缩减算法并利用带宽优化环来解决通信问题。
The Ring Allreduce
环中的gpu都被安排在一个逻辑环中。每个GPU应该有一个左邻和一个右邻;它只会向它的右邻居发送数据,并从它的左邻居接收数据。

The Scatter-Reduce
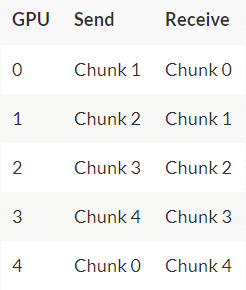
首先,gpu将数组划分为N个更小的块(其中N是环中的gpu数)。
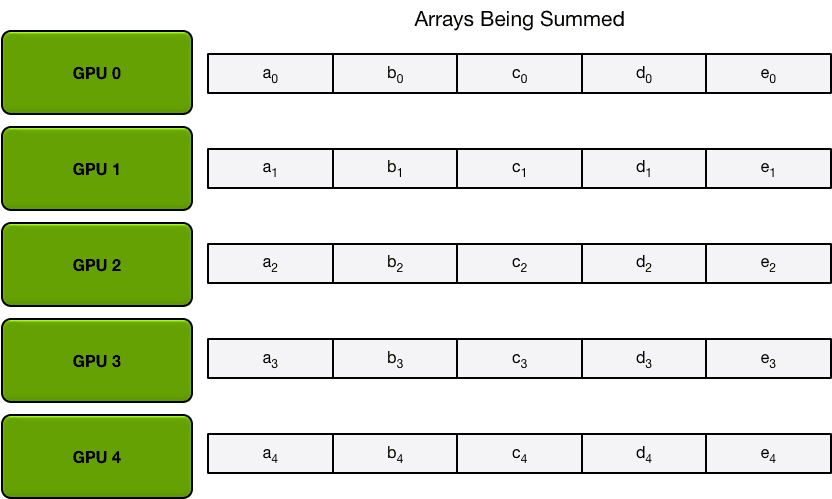
例如,在第一次迭代中,上图中的五个GPU将发送和接收以下区块:


在第一次发送和接收完成之后,每个GPU将拥有一个块,该块由两个不同GPU上相同块的和组成。例如,第二个GPU上的第一个块将是该块中来自第二个GPU和第一个GPU的值的和。

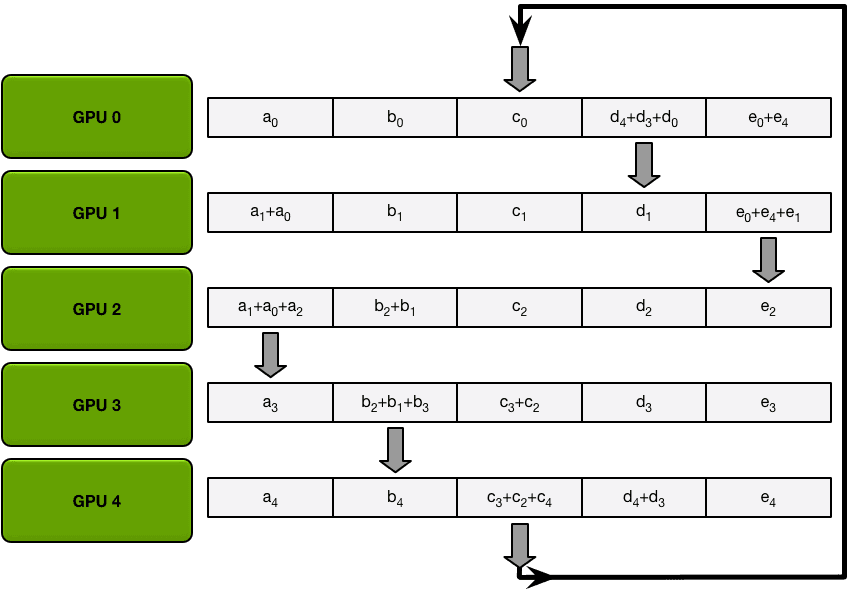
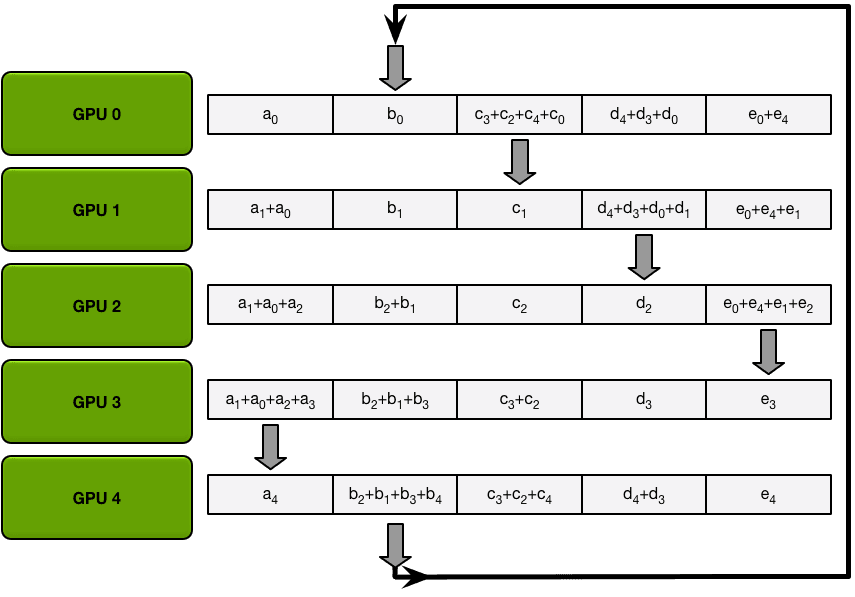

The Allgather
例如,在我们的5 - gpu设置的第一次迭代中,gpu将发送和接收以下块
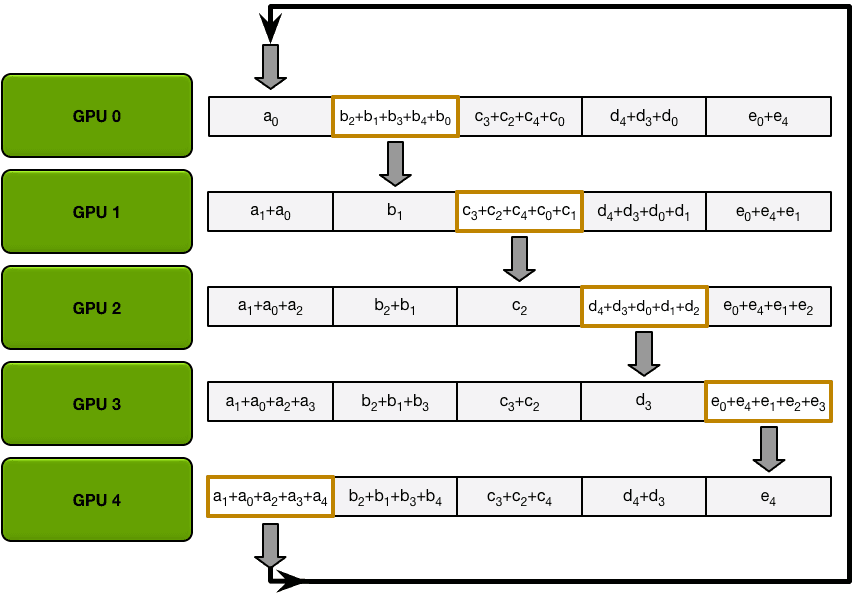
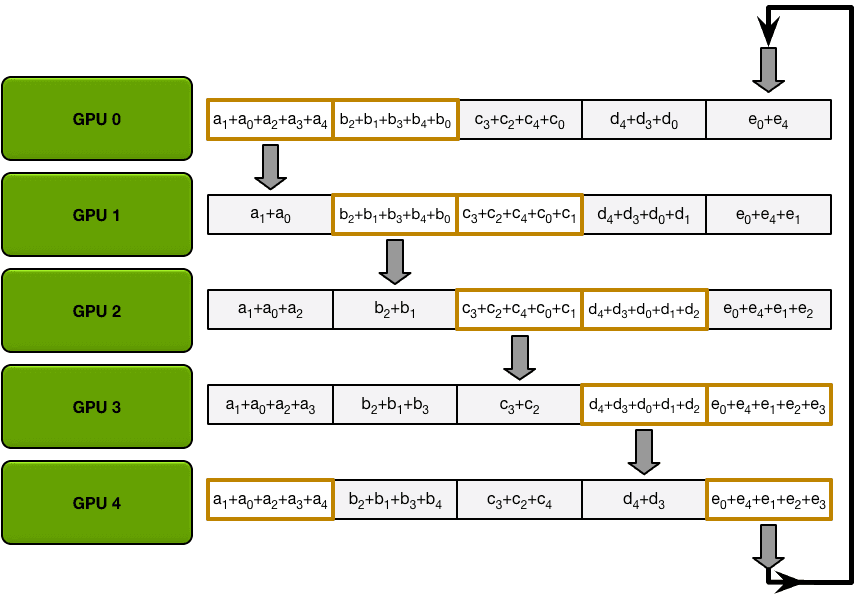
第一次迭代完成后,每个GPU将拥有最终数组的两个块。
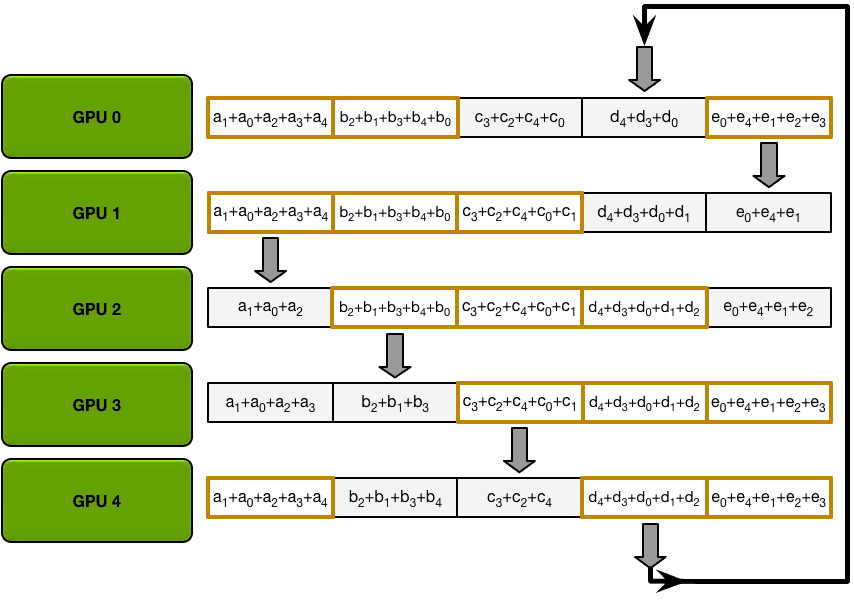


All-reduce Communication Cost
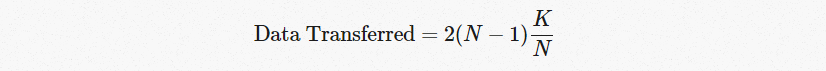
重要的是,这与GPU的数量无关。
Applying the Allreduce to Deep Learning


【转载】 Ring Allreduce (深度神经网络的分布式计算范式 -------------- 环形全局规约)的更多相关文章
- TensorFlow 深度学习笔记 TensorFlow实现与优化深度神经网络
转载请注明作者:梦里风林 Github工程地址:https://github.com/ahangchen/GDLnotes 欢迎star,有问题可以到Issue区讨论 官方教程地址 视频/字幕下载 全 ...
- TensorFlow实现与优化深度神经网络
TensorFlow实现与优化深度神经网络 转载请注明作者:梦里风林Github工程地址:https://github.com/ahangchen/GDLnotes欢迎star,有问题可以到Issue ...
- 如何用70行Java代码实现深度神经网络算法
http://www.tuicool.com/articles/MfYjQfV 如何用70行Java代码实现深度神经网络算法 时间 2016-02-18 10:46:17 ITeye 原文 htt ...
- 深度神经网络(DNN)模型与前向传播算法
深度神经网络(Deep Neural Networks, 以下简称DNN)是深度学习的基础,而要理解DNN,首先我们要理解DNN模型,下面我们就对DNN的模型与前向传播算法做一个总结. 1. 从感知机 ...
- 深度神经网络(DNN)反向传播算法(BP)
在深度神经网络(DNN)模型与前向传播算法中,我们对DNN的模型和前向传播算法做了总结,这里我们更进一步,对DNN的反向传播算法(Back Propagation,BP)做一个总结. 1. DNN反向 ...
- 深度神经网络(DNN)损失函数和激活函数的选择
在深度神经网络(DNN)反向传播算法(BP)中,我们对DNN的前向反向传播算法的使用做了总结.里面使用的损失函数是均方差,而激活函数是Sigmoid.实际上DNN可以使用的损失函数和激活函数不少.这些 ...
- 深度神经网络(DNN)的正则化
和普通的机器学习算法一样,DNN也会遇到过拟合的问题,需要考虑泛化,这里我们就对DNN的正则化方法做一个总结. 1. DNN的L1&L2正则化 想到正则化,我们首先想到的就是L1正则化和L2正 ...
- 最大似然估计 (Maximum Likelihood Estimation), 交叉熵 (Cross Entropy) 与深度神经网络
最近在看深度学习的"花书" (也就是Ian Goodfellow那本了),第五章机器学习基础部分的解释很精华,对比PRML少了很多复杂的推理,比较适合闲暇的时候翻开看看.今天准备写 ...
- 神经网络 之 DNN(深度神经网络) 介绍
CNN(卷积神经网络).RNN(循环神经网络).DNN(深度神经网络) CNN 专门解决图像问题的,可用把它看作特征提取层,放在输入层上,最后用MLP 做分类. RNN 专门解决时间序列问题的,用来提 ...
- AlphaGo论文的译文,用深度神经网络和树搜索征服围棋:Mastering the game of Go with deep neural networks and tree search
转载请声明 http://blog.csdn.net/u013390476/article/details/50925347 前言: 围棋的英文是 the game of Go,标题翻译为:<用 ...
随机推荐
- 极限科技(INFINI labs)荣获中国信通院大数据“星河”标杆案例
12 月 6 日,由中国信息通信研究院和中国通信标准化协会大数据技术标准推进委员会(CCSA TC601)共同组织的 2023 大数据"星河(Galaxy)"案例评选结果正式公示. ...
- edge浏览器禁用搜索工具栏或七七八八的东西
edge浏览器禁用搜索工具栏或七七八八的东西 在浏览器地址里输入: edge://flags/#edge-show-feature-recommendations 把"Show featur ...
- Scrapy框架(九)--分布式爬虫
分布式爬虫 - 概念:我们需要搭建一个分布式的机群,让其对一组资源进行分布联合爬取. - 作用:提升爬取数据的效率 - 如何实现分布式? - 安装一个scrapy-redis的组件 爬取到的数据自动存 ...
- java8 多条件的filter过滤
java8 多条件的filter过滤 package com.example.core.mydemo.java; import java.io.Serializable; import java.ti ...
- Task2 -- 关于Lecture3
Smiling & Weeping ---- 玲珑骰子安红豆, 入骨相思知不知. 1. 学习Git分支管理: Git分支是灵活开发的关键.创建.切换和合并分支是基础操作.使用如下命令: bas ...
- uniapp 使用z-paging 分页组件 写在头部插槽内的单选按钮无法点击
这个问题是因为组件层级太低 <z-paging ref="paging" v-model="dataList" @query="queryLis ...
- 开箱即用的Live2d
安装 npm i @tomiaa/live2d 代码 <template> <div ref="live2dContentRef" id="live2d ...
- Python中的常见方法
Python中有三种比较常见的方法类型,如类方法和静态方法,实例方法,他们是面向对象编程中重要的概念. 1.类方法 类方法是通过使用装饰器@classmethod来定义的,他的第一个参数是cls,指向 ...
- pytest_fixture通过参数request获取测试数据,并在fixture方法里面使用
pytest fixture传参request的使用 获取request对pytest插件的版本有要求,如果找不到request报错的话, 建议先升级pytest的版本 要实现的效果 执行测试用例,调 ...
- CentOS8 安装ansible
# 安装epel扩展源 yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm -y # ...