超大超详细图解,让你掌握Spark memeoryStore内存管理的精髓
摘要:memoryStore主要是将没有序列化的java对象数组或者序列化的byteBuffer放到内存中。
本文分享自华为云社区《spark到底是怎么确认内存够不够用的?超大超详细图解!让你掌握Spark memeoryStore内存管理的精髓》,作者: breakDraw 。
首先回顾一下spark中的Block Manager和memory Store是做什么的。它主要是将没有序列化的java对象数组或者序列化的byte Buffer放到内存中。
但是这就涉及到一些内存管理的问题,如果放不下,是不是要放磁盘?什么时候认为放不下?这里会一一解读。
MemoryStore的putIterator
这个方法是把一堆values的数组内容放入内存中(本质上就是放到Map<blockId, blockEntry>中。如果发现内存足够,能够申请,则调用putArray把数据写入内存(就是放到map中), 否则就去调用diskStore的接口写入磁盘中。
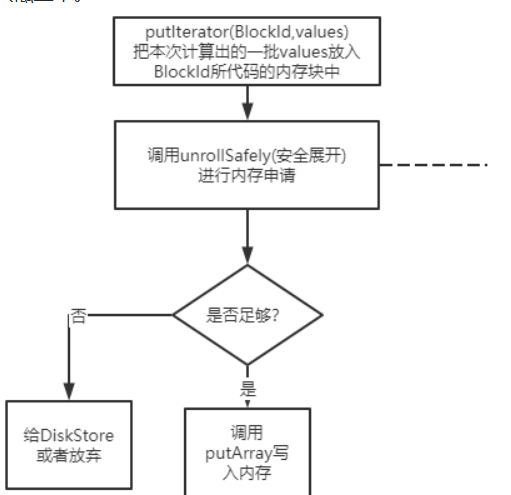
这里我先打住,不直接往下讲,而是给自己假设场景,如果是自己在开发计算引擎,写executor里的block缓存,肯定需要思考这个问题:
什么时候认为内存是足够的?
最简单的一个做法:
- 我给每个memoryStore设定一个阈值MaxMemory,
- 维护一个值currentMemory, 这个值就是memoryStroe里那个Map<BlockId,memoryEntry>所占的大小。
- 然后遍历计算一下输入参数values所占的内存大小 needMemory
- 如果needMemory > maxMemory - currentMemory, 则认为内存不足,写入到磁盘。
这个做法相当于直接把整个values大小都计算好之后,如果ok,马上进行写入内存操作。
如果是memoryStore是单线程的模块那ok, 但如果这个putIterator是一个支持多线程写入的模块呢? 当我觉得100M足够,我写入,可能得花10s, 然后另外一个线程也觉得100M足够,也要写入,结果写到一半发现内存不够,就尴尬了。
因此问题变为:
多线程时,如果确保计算的内存量是有效的?
一种方式,就是每次确定要写入时, 把要写入的这100M的量直接加到currentMemory中。 后面的线程要判断时,直接拿最新的curentMemory判断。
但实际上这个数据并没有真正写入map中, 有可能中间出现写入失败或者线程中断, 那这时候已经被处理过的currentMemory就不好搞了。
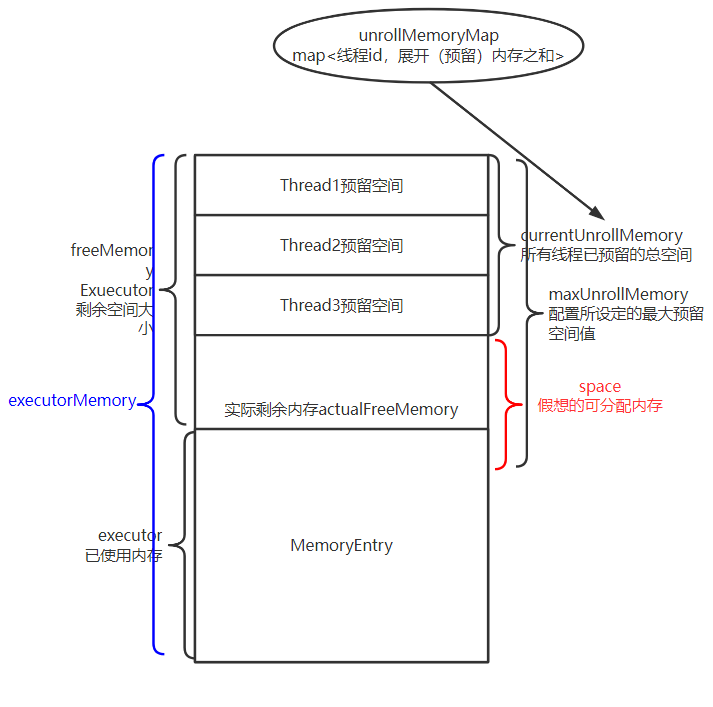
所以引入一个概念,叫展开内存unrollMemory。
每个线程都有自己的unrollMemory, 可以理解为该线程 准备 写入到内存中的大小。因此我们统计剩余可写入内存时, 实际上是等于 MaxMemory - currentMemory - 所有线程unrollMemory总和。
但是我们又不能让线程展开的这个值正好把剩余内存占满,所以会设定一个展开内存总和maxUnrollMemory,替代MaxMemory。
因此此时我这个线程可用的剩余内存space,实际上为maxUnrollMemory - cyrrentUnrollMemory。
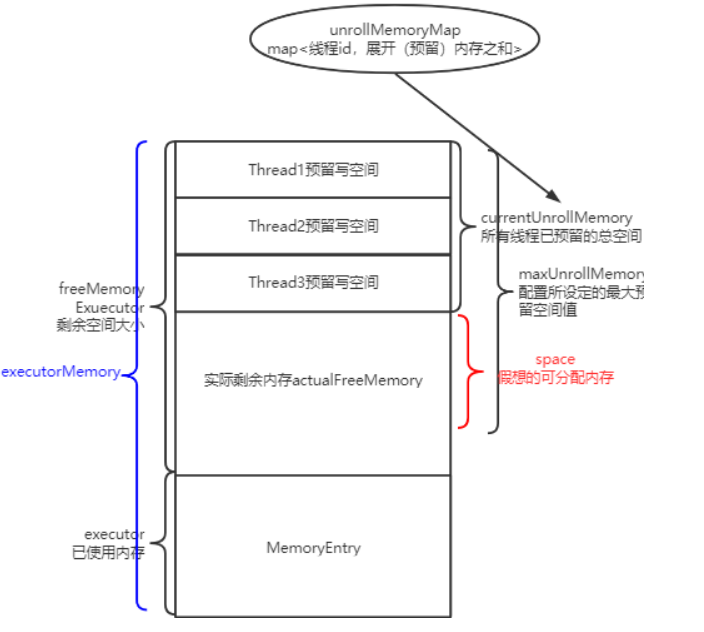
但问题又来了,如果我们假想的可分配内存比实际剩余内存小,怎么办?如下图:
一种方式,是发现假想剩余内存小于实际剩余内存时,认为内存不足,把数据写入磁盘。
但有个问题, 假设我需要写入100M, 实际剩余内存是98M, 其实只差了2M, 那为什么不能挤挤呢?只差2M了!
然而我肯定不能去动其他线程的unrollMemory,毕竟人家都认为自己是ok的准备写入了,你总不能插队吧?如果能动其他线程准备写入的数据,这管理就太复杂了。因此我们需要去已使用内存MemoryEntry里面找, 找一下是不是有比较小的block块,比如有一个块只有5M, 那我就把这个block块放入磁盘,那么我就可以塞进去了!
解答完上述问题后,再学习memoryStore的内存写入管理机制,就容易多了。
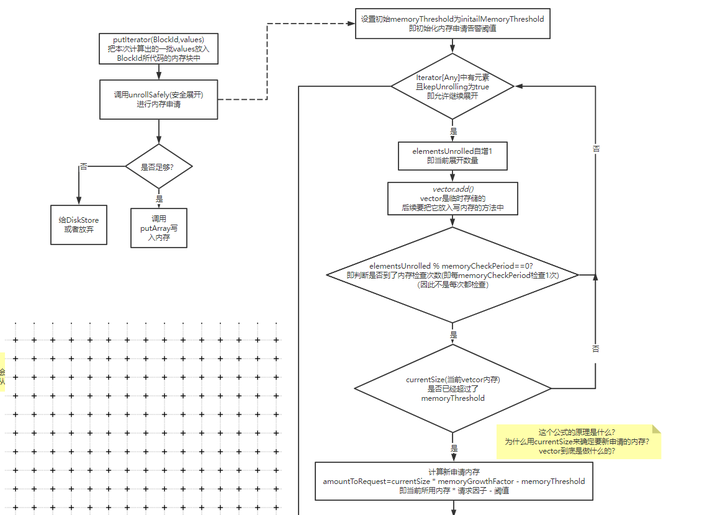
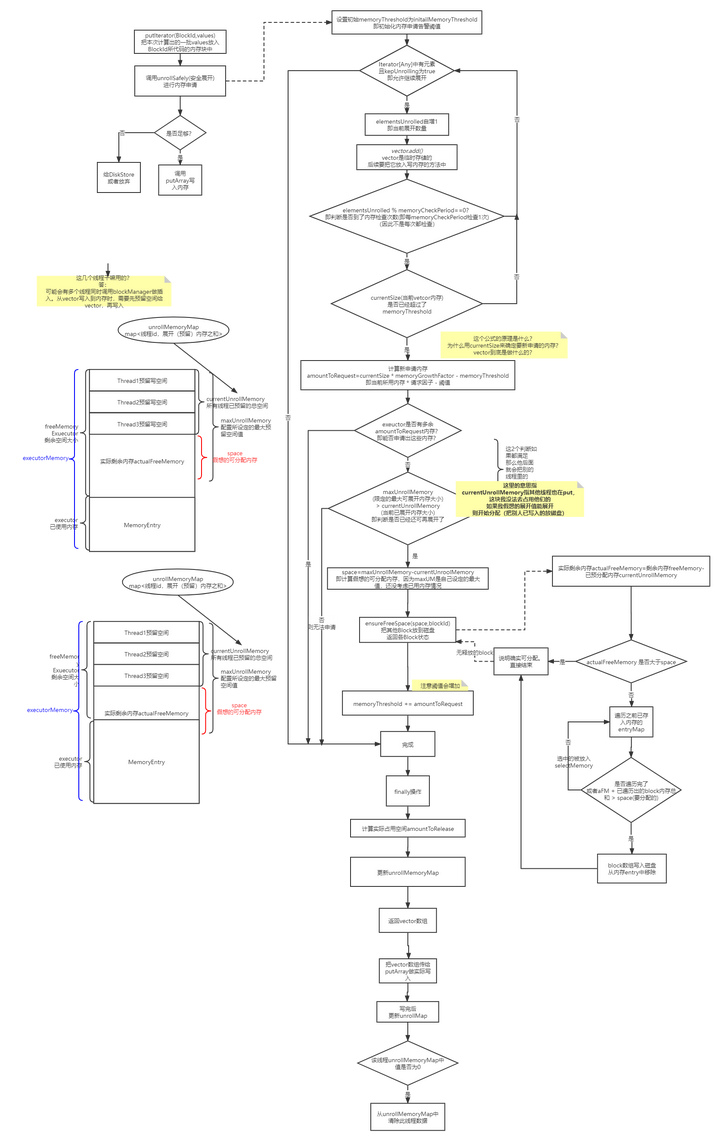
memoryStore完整安全展开流程
1. 计算需要写入的内存大小,是否需要申请新内存
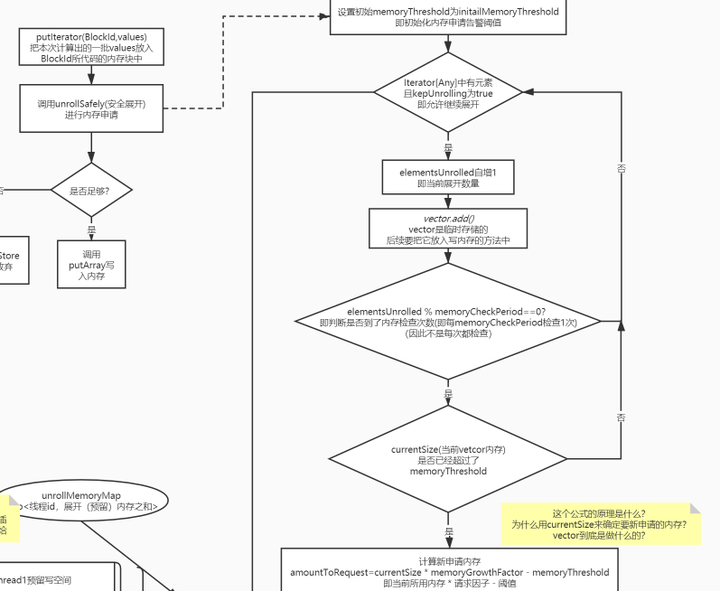
这里的计算不同于上文中提到的直接遍历完之后判断总大小
因为当时传入的是一个迭代器,只能迭代一次,每次迭代时都需要放入vector这个临时存储的列表中,万一超级大,放入vector时超出范围就GG了, 所以它实际时每隔一段就会检查一下是否超出阈值。
2. 计算剩余可用的展开空间
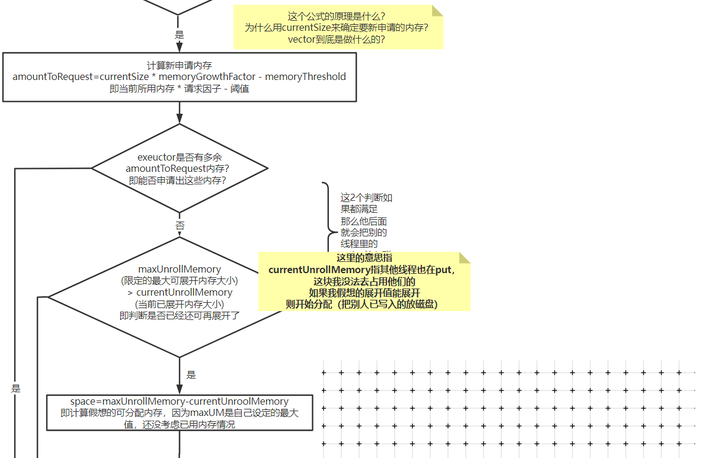
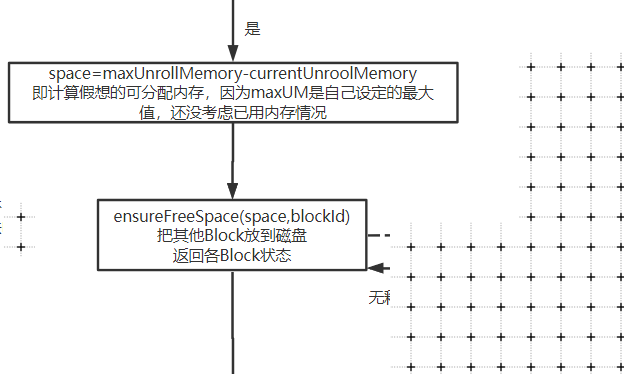
下图标注的地方就是上文最后算出的space:
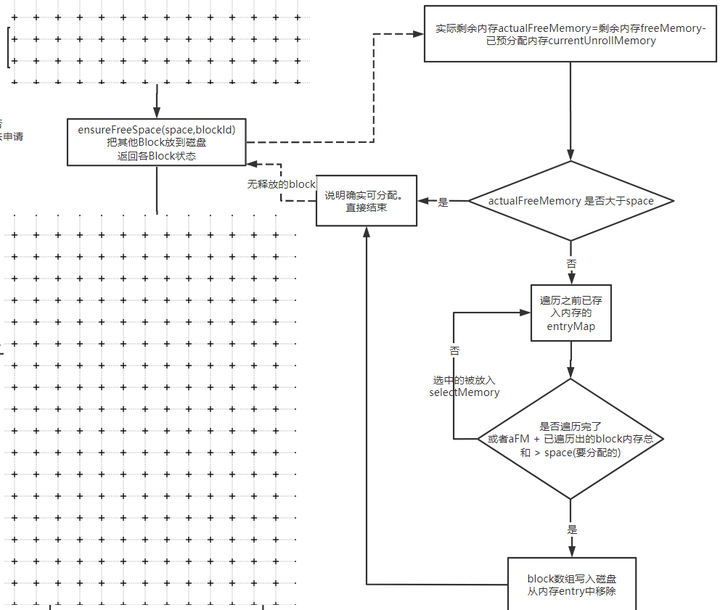
如果小于实际内存,那么就需要去已分配的内存中找,看下能不能选一些小朋友去磁盘中。
spark不足时,检查能否抽一些已分配内存区磁盘
核心方法来自ensureFreeSpace
我们看下它的实现:
这个过程比较简单,也没做太多优化,不考虑最优情况,否则会有排序的性能问题。
如果发现抽内存也不够用, 那就直接认为不行了。如果ok,那就认为可行,
内存足够分配,写入
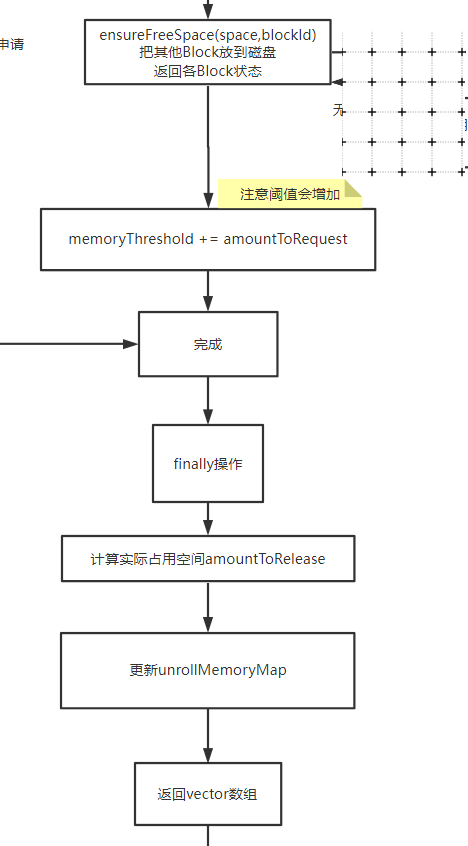
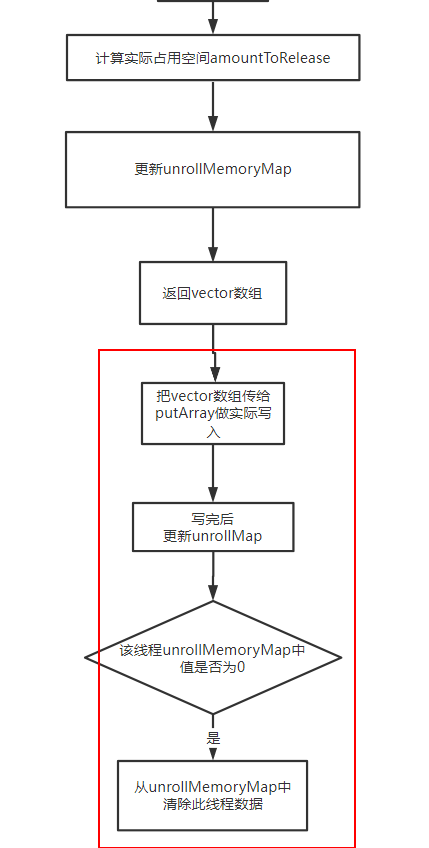
最后会返回一个vector数据
这个vector会拿去做真正的写入操作。
完整高清大图过程:
超大超详细图解,让你掌握Spark memeoryStore内存管理的精髓的更多相关文章
- [转]超详细图解:自己架设NuGet服务器
本文转自:http://diaosbook.com/Post/2012/12/15/setup-private-nuget-server 超详细图解:自己架设NuGet服务器 汪宇杰 ...
- Spark 静态内存管理
作者编辑:杜晓蝶,王玮,任泽 Spark 静态内存管理详解 一. 内容简介 spark从1.6开始引入了动态内存管理模式,即执行内存和存储内存之间可以互相抢占.spark提供两种内存分配模式,即:静态 ...
- Spark(二): 内存管理
Spark 作为一个以擅长内存计算为优势的计算引擎,内存管理方案是其非常重要的模块: Spark的内存可以大体归为两类:execution和storage,前者包括shuffles.joins.sor ...
- Spark内核-内存管理
Spark 集群会启动 Driver 和 Executor 两种 JVM 进程 我们只关注Executor的内存. 分为堆内内存和堆外内存 内存分为 存储内存 : 存储数据用的. 执行内存: 执行sh ...
- 超详细图解:自己架设NuGet服务器
原文:http://diaosbook.com/Post/2012/12/15/setup-private-nuget-server NuGet 是.NET程序员熟知的给.NET项目自动配置安装lib ...
- PyCharm 创建指定版本的 Django (超详细图解)
最近在学习胡阳老师(the5fire)的<Django企业级开发实战>,想要使用pycharm创建django项目时,在使用virtualenv创建虚拟环境后,在pycharm内,无论如何 ...
- Spark 动态(统一)内存管理模型
作者编辑:王玮,胡玉林 一.回顾 在前面的一篇文章中我们介绍了spark静态内存管理模式以及相关知识https://blog.csdn.net/anitinaj/article/details/809 ...
- Apache Spark 内存管理详解(转载)
Spark 作为一个基于内存的分布式计算引擎,其内存管理模块在整个系统中扮演着非常重要的角色.理解 Spark 内存管理的基本原理,有助于更好地开发 Spark 应用程序和进行性能调优.本文旨在梳理出 ...
- spark内存管理器--MemoryManager源码解析
MemoryManager内存管理器 内存管理器可以说是spark内核中最重要的基础模块之一,shuffle时的排序,rdd缓存,展开内存,广播变量,Task运行结果的存储等等,凡是需要使用内存的地方 ...
- spark内存管理详解
Spark 作为一个基于内存的分布式计算引擎,其内存管理模块在整个系统中扮演着非常重要的角色.理解 Spark 内存管理的基本原理,有助于更好地开发 Spark 应用程序和进行性能调优.本文旨在梳理出 ...
随机推荐
- 【Windows 开发环境配置】NVIDIA 篇
CUDA 从CUDA Toolkit Archive下载相应版本的离线安装包,这里以11.7为例. 打开安装包,在安装选项选择自定义模式,点击下一步. 在自定义安装选项中,仅选择CUDA组件(其中Ns ...
- 普冉PY32系列(十二) 基于PY32F002A的6+1通道遥控小车III - 驱动篇
目录 普冉PY32系列(一) PY32F0系列32位Cortex M0+ MCU简介 普冉PY32系列(二) Ubuntu GCC Toolchain和VSCode开发环境 普冉PY32系列(三) P ...
- 记一次在线客服系统用户遭勒索,索要茶水费事件的 Windbg 分析与应对
本文记录了几个月前,客户在使用在线客服系统过程中,遭到勒索威胁,索要茶水费 的事件.经过应对,快速的化解了攻击威胁,并继续安全使用至今. 讲故事 威胁次日,收到报警,服务器 CPU 使用率持续超过 8 ...
- 【结对作业】第一周 | 学习体会day03
昨天解决线路查询时遇到的type接受为空导致出现空指针异常抛出,后来发现是因为传递的数据类型出现了问题,更改数据类型之后问题就得到了解决今天在实现站点查询线路时遇到了乱码问题,在这之前我们单独编写代码 ...
- 热烈祝贺:薪火数据(https://www.datainside.com.cn 数据中心低代码搭建平台)参加教育博览会取得圆满成功。
- 介绍一个我开源的项目:一键部署 VictoriaMetrics 群集
作者:张富春(ahfuzhang),转载时请注明作者和引用链接,谢谢! cnblogs博客 zhihu Github 公众号:一本正经的瞎扯 我实在是非常喜欢这个强大的 metrics 监控组件 Vi ...
- 【解决方案】MySQL5.7 百万数据迁移到 ElasticSearch7.x 的思考
目录 前言 一.一次性全量 二.定时任务增量 三.强一致性问题 四.canal 框架 4.1基本原理 4.2安装使用(重点) 版本说明 4.3引入依赖(测试) 4.4代码示例(测试) 五.文章小结 前 ...
- c++学习,和友元函数
第一友元函数访问私有元素时不会显示,但是是可以调用的(我使用的是gcc10.3版本的)友元函数可以访问任何元素.就是语法你别写错了. 继承如果父类已经写了构造函数,子类一定要赋值给构造函数,要么父类就 ...
- 又有新框架上线了,测试、AI 通通有「GitHub 热点速览」
本周热点之一可能就是 Apple 刚开源便获得 8k+ star 的机器学习框架 mlx,顺带官方开源的 mlx-example(示例仓)也在热门榜上有一席之位,据说它已经跑通了大模型 Llama 7 ...
- [ABC281G] Farthest City
Problem Statement You are given positive integers $N$ and $M$. Find the number, modulo $M$, of simpl ...