叫板GPT-4的Gemini,我做了一个聊天网页,可图片输入,附教程
先看效果:
简介
Gemini 是谷歌研发的最新一代大语言模型,目前有三个版本,被称为中杯、大杯、超大杯,Gemini Ultra 号称可与GPT-4一较高低:
- Gemini Nano(预览访问)
为设备端体验而构建的最高效模型,支持离线使用场景。 - Gemini Pro(已推出)
性能最佳的模型,具有各种文本和图像推理任务的功能。 - Gemini Ultra(预览访问)
将于2024年初推出,用于大规模高度复杂文本和图像推理任务的最强大模型。
Gemini Pro在八项基准测试中的六项上超越了GPT-3.5,被誉为“市场上最强大的免费聊天AI工具”。
本文,我们使用的是 Gemini Pro,Pro有两个模型:
- gemini-pro:针对仅文本提示进行了优化。
- gemini-pro-vision:针对文本和图像提示进行了优化。
API 免费!
Google这次确实给力,API直接免费开放,只要申请就给!
如何本地执行脚本 或 开发一个前端页面,顺利白嫖Google的Gemini呢?
先去 https://ai.google.dev/ 创建Gemini API key

顺便说一句,感兴趣可以去深入学习一下文档:https://ai.google.dev/docs
Gemini 构建应用程序所需的所有信息都可以在这个网站查到,包括Python、Android(Kotlin)、Node.js 和 Swift的支持文档。

我们直接看Python 快速入门指南:
https://ai.google.dev/tutorials/python_quickstart
更省事儿的是直接从这个官方示例中copy代码:
https://github.com/google/generative-ai-docs/blob/main/site/en/tutorials/python_quickstart.ipynb
核心代码
本地运行脚本,代码其实简单到离谱,6行足矣。
注:网络要畅通
# 先安装google-generativeai
pip install -q -U google-generativeai
文本对话
import google.generativeai as genai
GOOGLE_API_KEY='这里填写上一步获取的api'
genai.configure(api_key=GOOGLE_API_KEY)
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("你好")
print(response.text)
运行一下:

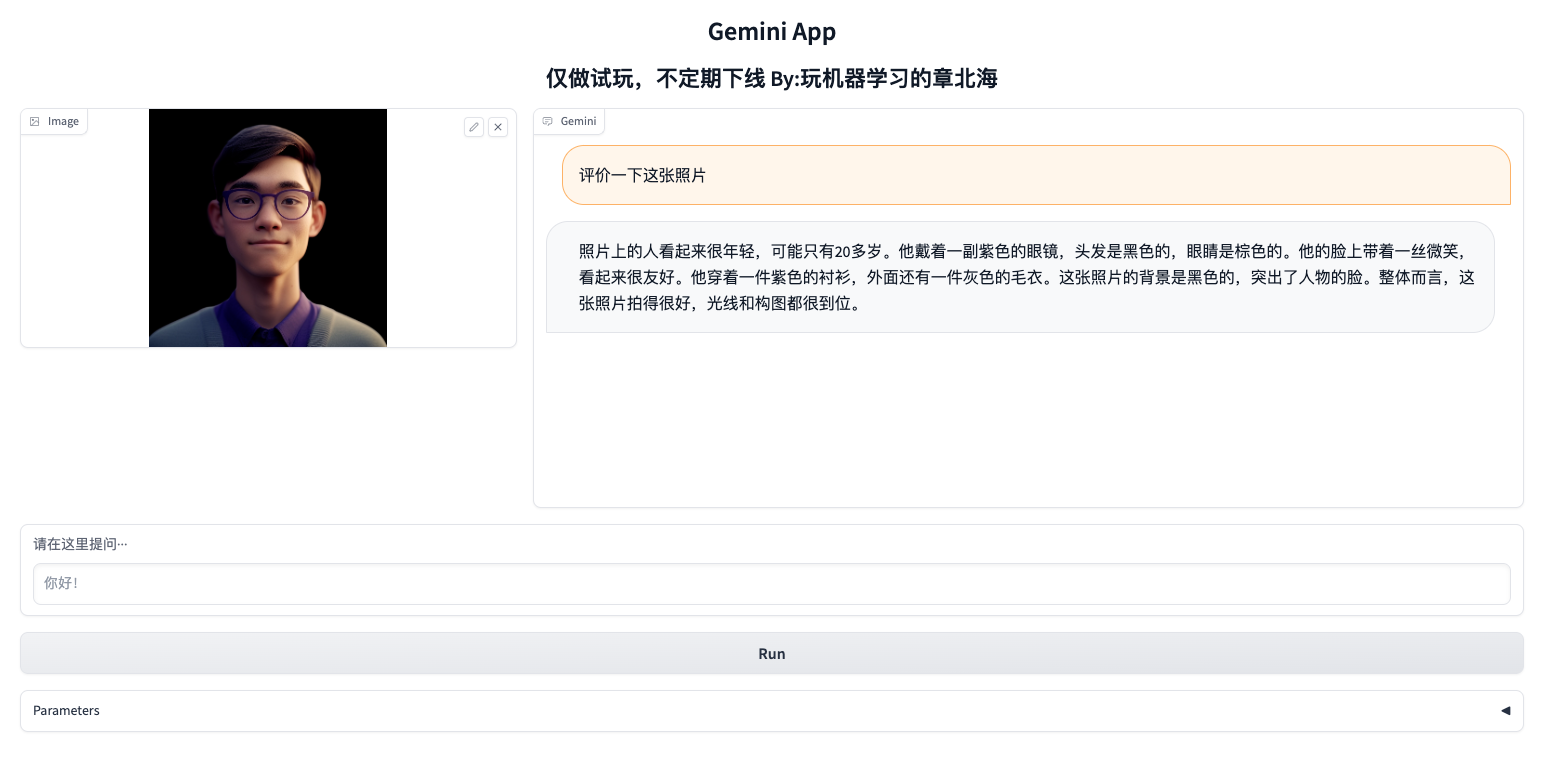
图片也可以作为输入,比如让Gemini评价一下我的头像

import PIL.Image
import google.generativeai as genai
img = PIL.Image.open('img.png')
GOOGLE_API_KEY='这里填写上一步获取的api'
genai.configure(api_key=GOOGLE_API_KEY)
model = genai.GenerativeModel('gemini-pro-vision')
response = model.generate_content(["请评价一下这张照片", img])
response.resolve()
print(response.text)
运行一下:

做个网页版
网页版可以使用streamlit或者Gradio实现,Gradio 本公众号写过,包括如何将项目免费部署到huggingface。需要了解更多:可以参考我这篇文章腾讯的这个算法,我搬到了网上,随便玩!
也可以部署到自己的服务器,加个域名就OK了
这里参考了这位大佬的代码:https://github.com/meryemsakin/GeminiGradioApp
我修改了源代码中GOOGLE_API_KEY获取方式并加了登陆认证,还做了一点中文翻译
代码如下:
import time
from typing import List, Tuple, Optional
import google.generativeai as genai
import gradio as gr
from PIL import Image
print("google-generativeai:", genai.__version__)
TITLE = """<h1 align="center">Gemini App</h1>"""
SUBTITLE = """<h2 align="center">仅做试玩,不定期下线</h2>"""
GOOGLE_API_KEY='这里填写上一步获取的api'
AVATAR_IMAGES = (
None,
"image.png"
)
def preprocess_stop_sequences(stop_sequences: str) -> Optional[List[str]]:
if not stop_sequences:
return None
return [sequence.strip() for sequence in stop_sequences.split(",")]
def user(text_prompt: str, chatbot: List[Tuple[str, str]]):
return "", chatbot + [[text_prompt, None]]
def bot(
#google_key: str,
image_prompt: Optional[Image.Image],
temperature: float,
max_output_tokens: int,
stop_sequences: str,
top_k: int,
top_p: float,
chatbot: List[Tuple[str, str]]
):
text_prompt = chatbot[-1][0]
genai.configure(api_key=GOOGLE_API_KEY)
generation_config = genai.types.GenerationConfig(
temperature=temperature,
max_output_tokens=max_output_tokens,
stop_sequences=preprocess_stop_sequences(stop_sequences=stop_sequences),
top_k=top_k,
top_p=top_p)
if image_prompt is None:
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content(
text_prompt,
stream=True,
generation_config=generation_config)
response.resolve()
else:
model = genai.GenerativeModel('gemini-pro-vision')
response = model.generate_content(
[text_prompt, image_prompt],
stream=True,
generation_config=generation_config)
response.resolve()
# streaming effect
chatbot[-1][1] = ""
for chunk in response:
for i in range(0, len(chunk.text), 10):
section = chunk.text[i:i + 10]
chatbot[-1][1] += section
time.sleep(0.01)
yield chatbot
image_prompt_component = gr.Image(type="pil", label="Image", scale=1)
chatbot_component = gr.Chatbot(
label='Gemini',
bubble_full_width=False,
avatar_images=AVATAR_IMAGES,
scale=2
)
text_prompt_component = gr.Textbox(
placeholder="你好!",
label="请在这里提问···"
)
run_button_component = gr.Button()
temperature_component = gr.Slider(
minimum=0,
maximum=1.0,
value=0.4,
step=0.05,
label="Temperature",
info=(
"Temperature 控制令牌选择的随机程度 "
"较低的Temperature适用于期望获得真实或正确回答的提示, "
"而较高的Temperature可以导致更多样化或意外的结果 "
))
max_output_tokens_component = gr.Slider(
minimum=1,
maximum=2048,
value=1024,
step=1,
label="Token limit",
info=(
"Token 限制确定每个提示可以获得的最大文本输出量 "
"每个 Token 大约为四个字符,默认值为 2048 "
))
stop_sequences_component = gr.Textbox(
label="Add stop sequence",
value="",
type="text",
placeholder="STOP, END",
info=(
"停止序列是一系列字符(包括空格),如果模型遇到它,会停止生成响应"
"该序列不作为响应的一部分,"
"可以添加多达5个停止序列"
))
top_k_component = gr.Slider(
minimum=1,
maximum=40,
value=32,
step=1,
label="Top-K",
info=(
"Top-k 改变了模型为输出选择 token 的方式 "
"Top-k 为 1 意味着所选 token 在模型词汇表中所有 token 中是最可能的(也称为贪心解码)"
"而 top-k 为 3 意味着下一个 token 从最可能的 3 个 token 中选取(使用temperature)"
))
top_p_component = gr.Slider(
minimum=0,
maximum=1,
value=1,
step=0.01,
label="Top-P",
info=(
"Top-p 改变了模型为输出选择 token 的方式 "
"token 从最可能到最不可能选择,直到它们的概率之和等于 top-p 值 "
"如果 token A、B 和 C 的概率分别为 0.3、0.2 和 0.1,top-p 值为 0.5 "
"那么模型将选择 A 或 B 作为下一个 token(使用temperature) "
))
user_inputs = [
text_prompt_component,
chatbot_component
]
bot_inputs = [
image_prompt_component,
temperature_component,
max_output_tokens_component,
stop_sequences_component,
top_k_component,
top_p_component,
chatbot_component
]
with gr.Blocks() as demo:
gr.HTML(TITLE)
gr.HTML(SUBTITLE)
with gr.Column():
with gr.Row():
image_prompt_component.render()
chatbot_component.render()
text_prompt_component.render()
run_button_component.render()
with gr.Accordion("Parameters", open=False):
temperature_component.render()
max_output_tokens_component.render()
stop_sequences_component.render()
with gr.Accordion("Advanced", open=False):
top_k_component.render()
top_p_component.render()
run_button_component.click(
fn=user,
inputs=user_inputs,
outputs=[text_prompt_component, chatbot_component],
queue=False
).then(
fn=bot, inputs=bot_inputs, outputs=[chatbot_component],
)
text_prompt_component.submit(
fn=user,
inputs=user_inputs,
outputs=[text_prompt_component, chatbot_component],
queue=False
).then(
fn=bot, inputs=bot_inputs, outputs=[chatbot_component],
)
demo.queue(max_size=99).launch(auth=("用户名", "密码"),debug=True)
部署到服务器涉及Nginx配置,域名注册、域名解析等等,蛮麻烦的,这里就不展开了。
叫板GPT-4的Gemini,我做了一个聊天网页,可图片输入,附教程的更多相关文章
- 做了一个sublime text插件
做了一个sublime text插件,可以方便地查看C++/python的调用图.插件的演示视频在这里: http://list.youku.com/albumlist/show?id=2820226 ...
- 做为一个前端工程师,是往node方面转,还是往HTML5方面转
文章背景:问题本身来自于知乎,但是我感觉这个问题很典型,有必要把问题在整理一下,重新分享出来. 当看到这个问题之前,我也碰到过很多有同样疑惑的同学,他们都有一个共同的疑问该学php还是nodejs,包 ...
- bootstrap做了一个表格
花了一下午做了一个表格: 大致是这样: 代码如下: <!DOCTYPE html> <html> <head> <meta charset="utf ...
- PHP MVC简单介绍,对PHP当前主流的MVC做了一个总结
东抄西抄,对PHP当前主流的MVC做了一个总结PPT. 希望对初学者有点帮助! PHP MVC初步.ppt
- 用MVVM做了一个保存网页的工具-上篇
前言: 你是否有过收藏了别人博客或文章,当想用的时候却找不到?你是否有过收藏了别人博客或文章,却因为没有网络而打不开网页?OK,下面是我做的一个工具,有兴趣的同学们可以download 玩下,哈哈^. ...
- php大力力 [042节] 今天做了一个删除功能
php大力力 [042节] 今天做了一个删除功能 if(isset($_GET['action'])){ if($_GET['action']=="del"){ $sql = &q ...
- 做了一个简易的git 代码自动部署脚本
做了一个简易的git 代码自动部署脚本 http://my.oschina.net/caomenglong/blog/472665 发表于2个月前(2015-06-30 21:08) 阅读(200 ...
- 用原生javascript做的一个打地鼠的小游戏
学习javascript也有一段时间了,一直以来分享的都是一些概念型的知识,今天有空做了一个打地鼠的小游戏,来跟大家分享一下,大家也可以下载来增加一些生活的乐趣,下面P出代码:首先是HTML部分代码: ...
- 利用SCI做的一个足球答题系统
SCI,异步串行通信接口,内置独立的波特率产生电路和SCI收发器,可以选择发送8或9个数据位(其中一位可以指定为奇或偶校验位). SCI是全双工异步串行通信接口,主要用于MCU与其他计算机或设备之间的 ...
- 高仿“点触验证码”做的一个静态Html例子
先上源码: <html> <head> <title>TouClick - Designed By MrChu</title> <meta htt ...
随机推荐
- ez_sql
打开界面是查询界面 点击不同的查询页面返回的内容不同,然后url的地址发生变化,毫无疑问注入点在id处 这里直接进行测试 单引号无回显 双引号回显id不存在 初步判断为字符型注入且为单引号包裹 因为双 ...
- 零基础快速上手STM32开发(手把手保姆级教程)
零基础快速上手STM32开发(手把手保姆级教程) 1. 前言 作为一名嵌入式工程师,STM32 是必须要学习的一款单片机,同时这款单片机资料足够多,而且比较简单,非常适合初学者入门. STM32 是一 ...
- .NET周刊【11月第4期 2023-11-26】
国内文章 万字长文:从 C# 入门学会 RabbitMQ 消息队列编程 https://www.cnblogs.com/whuanle/p/17837034.html 如题,详细的介绍RabbitMQ ...
- 0x04.信息收集
探针 被动:借助网上的一些接口查询或者网上已经获取到的,查看历史信息. 主动:使用工具,从本地流量出发,探测目标信息,会发送大量流量到对方服务器上. 谷歌语法 懒人语法:https://pentest ...
- 将 .NET Aspire 部署到 Kubernetes 集群
使用Aspirate可以将Aspire程序部署到Kubernetes 集群 工具安装 dotnet tool install -g aspirate --prerelease 注意:Aspirate ...
- Java自定义ClassLoader实现插件类隔离加载
为什么需要类隔离加载 项目开发过程中,需要依赖不同版本的中间件依赖包,以适配不同的中间件服务端 如果这些中间件依赖包版本之间不能向下兼容,高版本依赖无法连接低版本的服务端,相反低版本依赖也无法连接高版 ...
- [ARC105E] Keep Graph Disconnected
题目链接 好题. 如果 \(1\) 和 \(n\) 一直联通,开始即结束. 如果 \(n\mod 4=1\),那么 \(\frac 12x(x+1)+\frac12(n-x)(n-x+1)\) 为偶数 ...
- ssm整合-异常处理器
异常处理器 程序开发过程中不可避免会遇到异常现象 类似于这样的异常 异常出现的种类: 各个层均可能出现异常,当我们出现异常时,处理代码应该写在哪一层? 表现层,因为要把异常网上抛,在表现层进行 ...
- 通过match看rust
最常见的逻辑控制流比如if-else,switch,while等常用编程语言都支持,但恰巧rust语法中没有switch,取而代之的是更加强大适用的match匹配,我们就来看看rust的match有何 ...
- 万界星空科技五金家具企业MES案例介绍
五金家具行业MES解决方案 MES系统如何与家具企业生产相匹配?相较于其它大多数工业软件,MES系统无疑是受企业欢迎的软件之一.MES系统处于制造生产企业信息化的核心领域,有着承上启下的作用.那MES ...