Django+anaconda(spyder)
一、搭建django虚拟环境
打开anaconda prompt
输入:conda create -n mydjango_env
判断(y/n):y
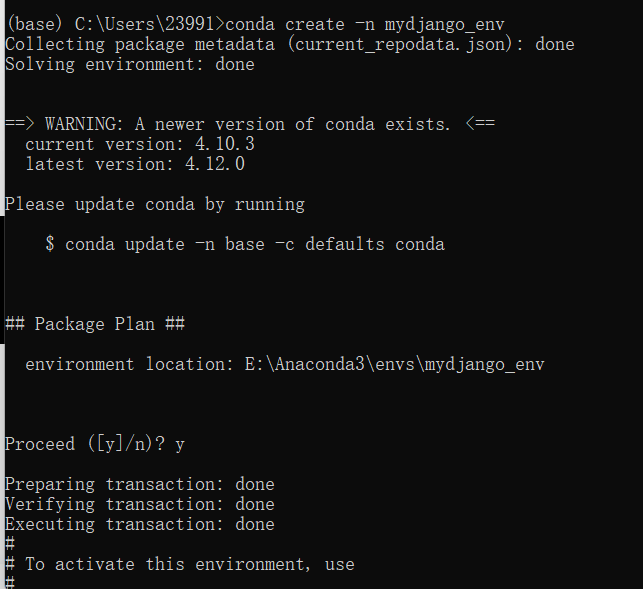
查看虚拟环境 conda env list
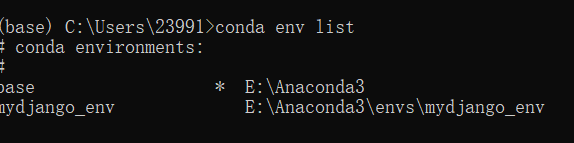
*号表示当前使用的环境
激活创建的虚拟环境 activate mydjango_env

二、安装Django
在新环境激活的状态下安装Django
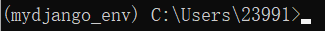
conda install django (这里如果要安装具体版本的话,就conda install django==2.0)

有一个选择y/n的,选y
下面的下载会有些慢,静候
三.创建项目
1)进入需要创建项目的文件目录

2)创建项目 django-admin startproject +项目名

此时Django项目已创建完成,目录下(我的是python1.0)会自动生成项目文件
四、启动服务
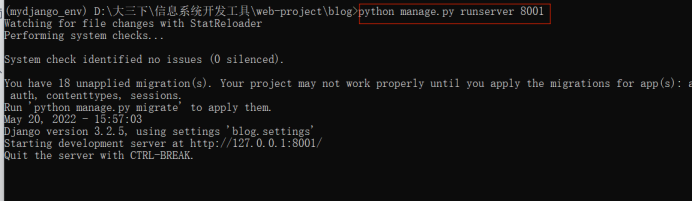
进入项目文件夹

输入路径名+python manage.py runserver 8001 (这里可以不用指定端口,默认端口为8000),such as
在浏览器中输入 localhost:8001即可访问
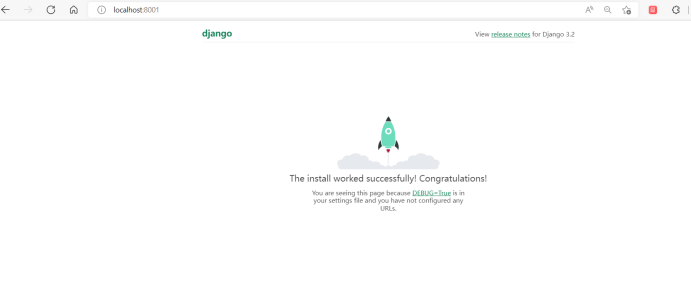
网站创建成功!
五、新建APP
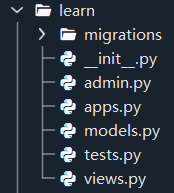
新建一个应用,名为learn

得到如下结果
把新定义的APP加到settings.py中的install_apps中(如果不加的话,Django就不能自动找到APP中的模板文件,即app-name/templates/下的文件,和静态文件,即app-name/static/中的文件),这里修改blog/blog/settings.py文件(打开Spyder修改哦~)
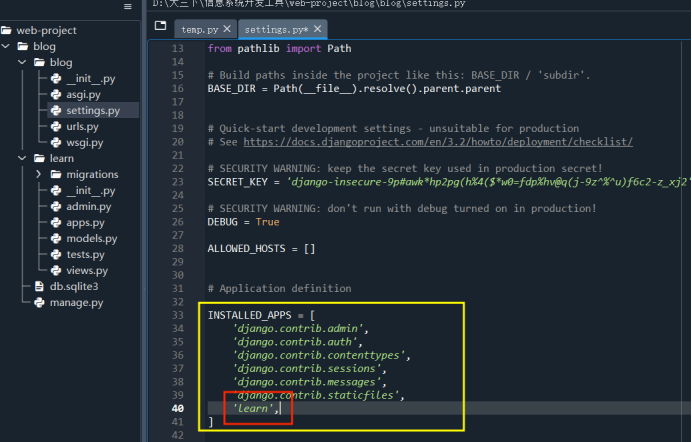
保存!保存!保存!(好习惯养成第一步)
以后的操作请保持网站处于运行状态!
六、定义视图函数
(1)打开learn目录中的views.py,修改其中的源代码
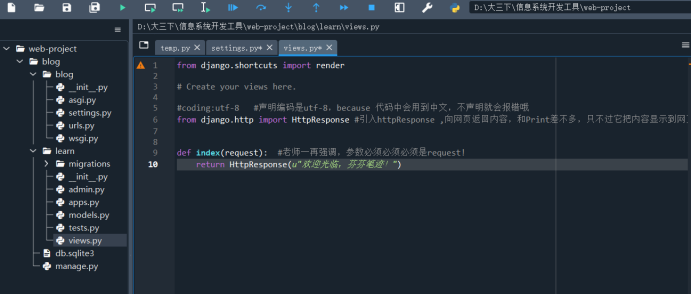
附代码:
#coding:utf-8 #声明编码是utf-8,because 代码中会用到中文,不声明就会报错哦
from django.http import HttpResponse #引入httpResponse ,向网页返回内容,和Print差不多,只不过它把内容显示到网页
def index(request): #老师一再强调,参数必须必须必须是request!
return HttpResponse(u"欢迎光临,芬芬笔迹!")
保存!保存!保存!(好习惯养成第二步)
继续吭哧吭哧敲代码。。。。。
(2)打开blog/blog/urls.py,改一改,修一修
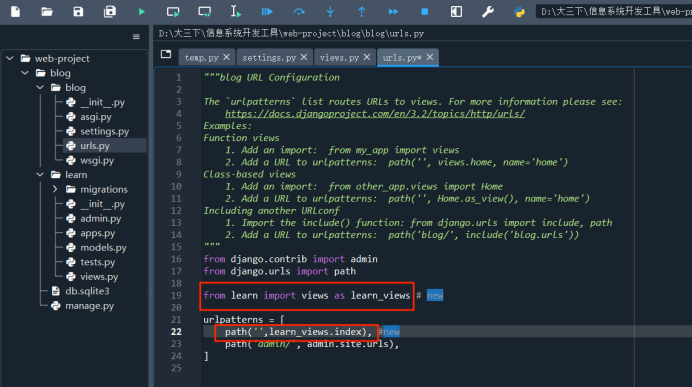
需要添加的代码:
from learn import views as learn_views
path('',learn_views.index),
保存!保存!保存!(好习惯养成第三步)
下面是见证奇迹的时刻~
(3)回到prompt
运行python manage.py runserver
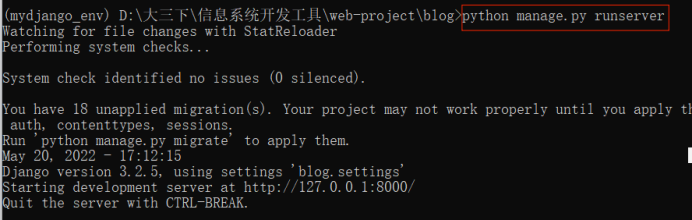
再看看浏览器发生的变化
我这里端口变成了8000,是因为我重启了一遍,所以,执行以上操作的时候,不要关闭网站,prompt端口可以多打开几个。
Django+anaconda(spyder)的更多相关文章
- anaconda spyder异常如何重新启动
电脑有一次断电,重新启动后anaconda的spyder就打不开了 重新启动spyder方法: 在anaconda安装目录的Scripts文件夹下,shift+右键在此窗口打开命令行,运行spyder ...
- 在 Ubuntu16.04上安装anaconda+Spyder+TensorFlow(支持GPU)
TensorFlow 官方文档中文版 http://www.tensorfly.cn/tfdoc/get_started/introduction.html https://zhyack.github ...
- Anaconda(Spyder)使用Tensorflow
按照上篇文安装成功后,每次使用TensorFlow的时候需要激活conda环境. 在正常情况下,是Anaconda的bin路径在环境变量中,但激活conda-tensorflow环境后,环境变量中存储 ...
- Anaconda spyder 设置tab键为2个空格
tool -> Preference->
- Anaconda Spyder 常用快捷键
Ctrl+1 注释.取消注释 Ctrl+4/5 块注释 / 取消块注释 Ctrl+D 删除一行 Ctrl+L 转到行 Ctrl+G/左键 查找函数定义 F9 运行选中代码 F12 断点 / 取消断点 ...
- Anaconda的CondaHTTPError问题
在Anaconda+Spyder配置Opencv的过程中遇到了缺乏cv2的问题,当时我在cmd的窗口(管理员身份)中输入了如下命令 conda install --channel https://co ...
- Python网络爬虫与信息提取(一)
学习 北京理工大学 嵩天 课程笔记 课程体系结构: 1.Requests框架:自动爬取HTML页面与自动网络请求提交 2.robots.txt:网络爬虫排除标准 3.BeautifulSoup框架:解 ...
- 用python玩微信(聊天机器人,好友信息统计)
1.用 Python 实现微信好友性别及位置信息统计 这里使用的python3+wxpy库+Anaconda(Spyder)开发.如果你想对wxpy有更深的了解请查看:wxpy: 用 Python 玩 ...
- 初识Matplotlib-01
初识数据分析 大数据是一个含义广泛的术语,是指数据集,如此庞大而复杂的,他们需要专门设计的硬件和软件工具进行处理.该数据集通常是万亿或EB的大小.这些数据集收集自各种各样的来源:传感器,气候信息,公开 ...
- 【学习笔记】PYTHON网络爬虫与信息提取(北理工 嵩天)
学习目的:掌握定向网络数据爬取和网页解析的基本能力the Website is the API- 1 python ide 文本ide:IDLE,Sublime Text集成ide:Pychar ...
随机推荐
- 2022-05-08:给你一个下标从 0 开始的字符串数组 words 。每个字符串都只包含 小写英文字母 。words 中任意一个子串中,每个字母都至多只出现一次。 如果通过以下操作之一,我们可以
2022-05-08:给你一个下标从 0 开始的字符串数组 words .每个字符串都只包含 小写英文字母 .words 中任意一个子串中,每个字母都至多只出现一次. 如果通过以下操作之一,我们可以从 ...
- XAF中XPO与EFCore的探讨
前言 首先抛出一个问题,在XAF项目中,我们现在可不可以选择EFCore?每个人可能都有自己的答案,这也没有什么标准答案.下面是我的个人看法,在刚接触XAF时,如何选择ORM,我也是犹豫了许久,最终选 ...
- Cobalt Strike 连接启动教程,制作图片🐎(2)
扫描有两种方式:arp 和 icmp 查看进程列表 攻击----生成后门-----Payload 可以生成各类语言免杀牧马---(输出:选择C或者python或者php) go.咕.com 生成c语言 ...
- odoo开发教程十七:controller
一:controller简述 odoo里面的controller相似于springMVC,也是根据url来控制请求,把请求处理映射到具体某个方法上的. 类比于springmvc中,根据请求,在请求处理 ...
- How to fix the problem that Raspberry Pi cannot use the root user for SSH login All In One
How to fix the problem that Raspberry Pi cannot use the root user for SSH login All In One 如何修复树莓派无法 ...
- 新版本,ggplot2 v3.3.0 新特性来袭
ggplot2 迎来了新的版本,官方宣布了一些新的特性.下面一起看看吧. 1. 轴代码重写 这有利于解决轴标签重叠的情况. 2. 新的 scale bin,它可以像使用 color, fill 一样使 ...
- 10.5. 版本控制(如Git)
版本控制系统(Version Control System,VCS)是软件开发过程中用于管理源代码的工具.它可以帮助你跟踪代码的变更历史,方便回滚到之前的版本,以及协同多人共同开发.Git是当前最流行 ...
- 【Python&目标识别】labelimg报错IndexError: list index out of range
博主在使用labelimg选取深度学习样本时,命令行报错IndexError: list index out of range,几经周折终于解决了,所以跟大家分享一下. ...
- PQ常用模板
//json请求 Json.Document(Web.Contents("",[Headers=[#"cookie"=tk,#"Content-Typ ...
- Electron桌面应用开发基础
Electron桌面应用开发 Electron技术架构 地址:快速入门 | Electron Chromium 支持最新特性的浏览器 Node.js Javascript运行时,可实现文件读写 Nat ...