Django+anaconda(spyder)
一、搭建django虚拟环境
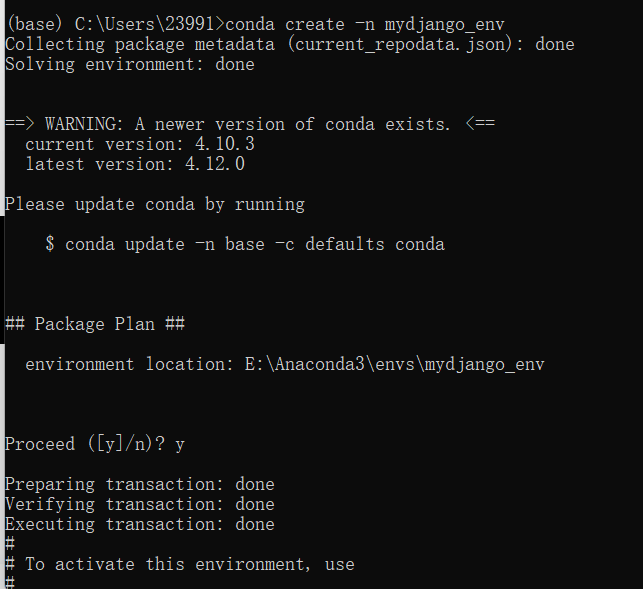
打开anaconda prompt
输入:conda create -n mydjango_env
判断(y/n):y
查看虚拟环境 conda env list
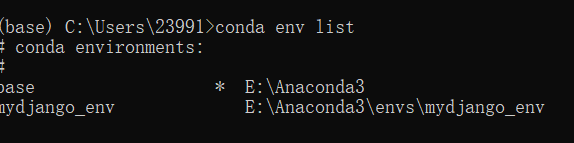
*号表示当前使用的环境
激活创建的虚拟环境 activate mydjango_env

二、安装Django
在新环境激活的状态下安装Django
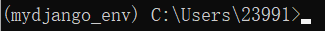
conda install django (这里如果要安装具体版本的话,就conda install django==2.0)

有一个选择y/n的,选y
下面的下载会有些慢,静候
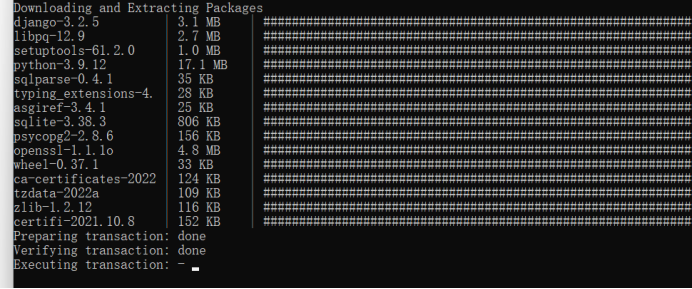
三.创建项目
1)进入需要创建项目的文件目录

2)创建项目 django-admin startproject +项目名

此时Django项目已创建完成,目录下(我的是python1.0)会自动生成项目文件
四、启动服务
进入项目文件夹

输入路径名+python manage.py runserver 8001 (这里可以不用指定端口,默认端口为8000),such as
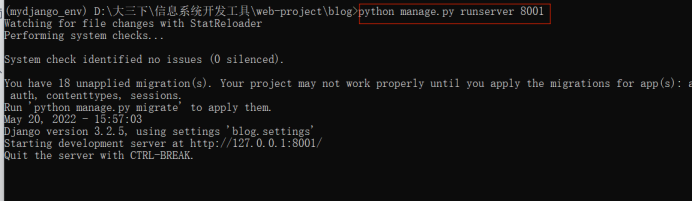
在浏览器中输入 localhost:8001即可访问
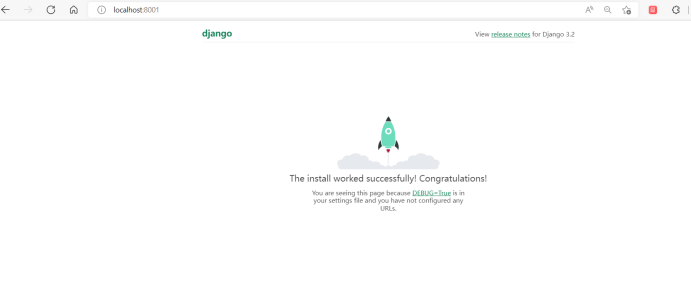
网站创建成功!
五、新建APP
新建一个应用,名为learn

得到如下结果
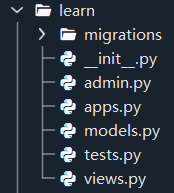
把新定义的APP加到settings.py中的install_apps中(如果不加的话,Django就不能自动找到APP中的模板文件,即app-name/templates/下的文件,和静态文件,即app-name/static/中的文件),这里修改blog/blog/settings.py文件(打开Spyder修改哦~)
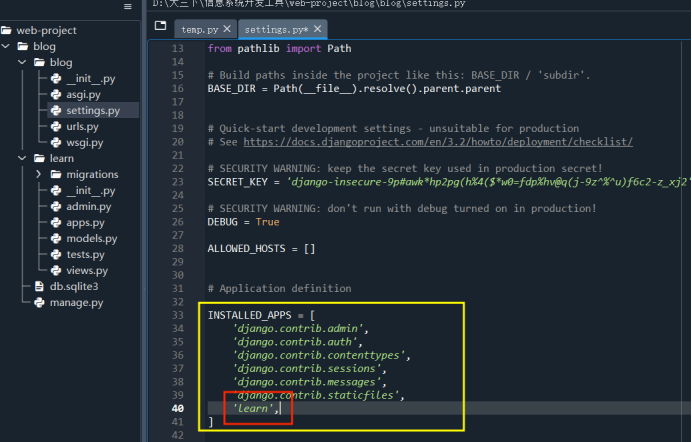
保存!保存!保存!(好习惯养成第一步)
以后的操作请保持网站处于运行状态!
六、定义视图函数
(1)打开learn目录中的views.py,修改其中的源代码
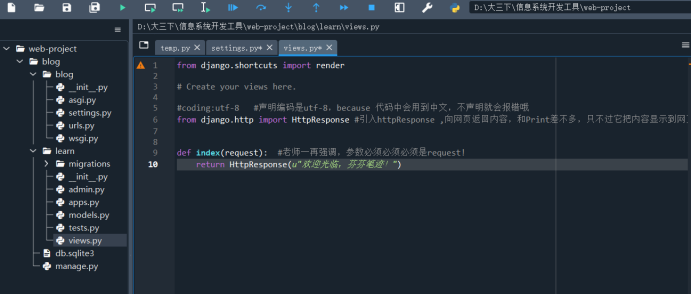
附代码:
#coding:utf-8 #声明编码是utf-8,because 代码中会用到中文,不声明就会报错哦
from django.http import HttpResponse #引入httpResponse ,向网页返回内容,和Print差不多,只不过它把内容显示到网页
def index(request): #老师一再强调,参数必须必须必须是request!
return HttpResponse(u"欢迎光临,芬芬笔迹!")
保存!保存!保存!(好习惯养成第二步)
继续吭哧吭哧敲代码。。。。。
(2)打开blog/blog/urls.py,改一改,修一修
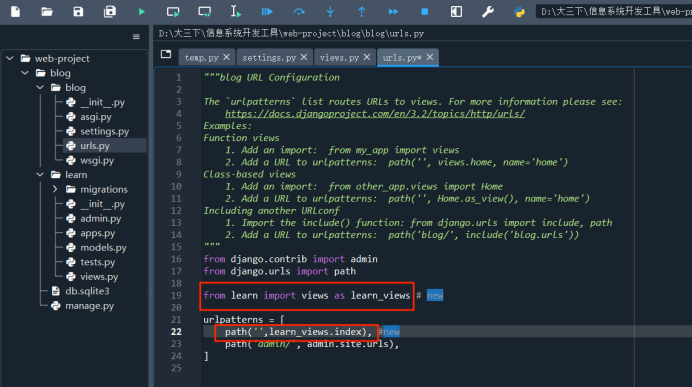
需要添加的代码:
from learn import views as learn_views
path('',learn_views.index),
保存!保存!保存!(好习惯养成第三步)
下面是见证奇迹的时刻~
(3)回到prompt
运行python manage.py runserver
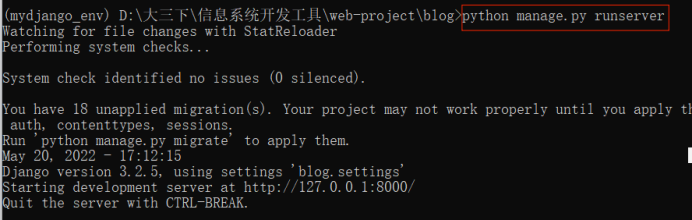
再看看浏览器发生的变化
我这里端口变成了8000,是因为我重启了一遍,所以,执行以上操作的时候,不要关闭网站,prompt端口可以多打开几个。
Django+anaconda(spyder)的更多相关文章
- anaconda spyder异常如何重新启动
电脑有一次断电,重新启动后anaconda的spyder就打不开了 重新启动spyder方法: 在anaconda安装目录的Scripts文件夹下,shift+右键在此窗口打开命令行,运行spyder ...
- 在 Ubuntu16.04上安装anaconda+Spyder+TensorFlow(支持GPU)
TensorFlow 官方文档中文版 http://www.tensorfly.cn/tfdoc/get_started/introduction.html https://zhyack.github ...
- Anaconda(Spyder)使用Tensorflow
按照上篇文安装成功后,每次使用TensorFlow的时候需要激活conda环境. 在正常情况下,是Anaconda的bin路径在环境变量中,但激活conda-tensorflow环境后,环境变量中存储 ...
- Anaconda spyder 设置tab键为2个空格
tool -> Preference->
- Anaconda Spyder 常用快捷键
Ctrl+1 注释.取消注释 Ctrl+4/5 块注释 / 取消块注释 Ctrl+D 删除一行 Ctrl+L 转到行 Ctrl+G/左键 查找函数定义 F9 运行选中代码 F12 断点 / 取消断点 ...
- Anaconda的CondaHTTPError问题
在Anaconda+Spyder配置Opencv的过程中遇到了缺乏cv2的问题,当时我在cmd的窗口(管理员身份)中输入了如下命令 conda install --channel https://co ...
- Python网络爬虫与信息提取(一)
学习 北京理工大学 嵩天 课程笔记 课程体系结构: 1.Requests框架:自动爬取HTML页面与自动网络请求提交 2.robots.txt:网络爬虫排除标准 3.BeautifulSoup框架:解 ...
- 用python玩微信(聊天机器人,好友信息统计)
1.用 Python 实现微信好友性别及位置信息统计 这里使用的python3+wxpy库+Anaconda(Spyder)开发.如果你想对wxpy有更深的了解请查看:wxpy: 用 Python 玩 ...
- 初识Matplotlib-01
初识数据分析 大数据是一个含义广泛的术语,是指数据集,如此庞大而复杂的,他们需要专门设计的硬件和软件工具进行处理.该数据集通常是万亿或EB的大小.这些数据集收集自各种各样的来源:传感器,气候信息,公开 ...
- 【学习笔记】PYTHON网络爬虫与信息提取(北理工 嵩天)
学习目的:掌握定向网络数据爬取和网页解析的基本能力the Website is the API- 1 python ide 文本ide:IDLE,Sublime Text集成ide:Pychar ...
随机推荐
- 2020-12-07:go中,slice的底层数据结构是什么?
福哥答案2020-12-07: 源码位于runtime/slice.go文件中的slice结构体. type slice struct { array unsafe.Pointer len int c ...
- 2022-02-03:有一队人(两人或以上)想要在一个地方碰面,他们希望能够最小化他们的总行走距离。 给你一个 2D 网格,其中各个格子内的值要么是 0,要么是
2022-02-03:最佳的碰头地点. 有一队人(两人或以上)想要在一个地方碰面,他们希望能够最小化他们的总行走距离. 给你一个 2D 网格,其中各个格子内的值要么是 0,要么是 1. 1 表示某个人 ...
- pandas 数据处理 一些常用操作
读取csv文件,打印列名称: import pandas as pd # data = pd.read_csv("guba_fc_result_20230413.csv") dat ...
- API架构的选择,RESTful、GraphQL还是gRPC
hi,我是熵减,见字如面. 在现代的软件工程中,微服务或在客户端与服务端之间的信息传递的方式,比较常见的有三种架构设计的风格:RESTful.GraphQL和gRPC. 每一种模式,都有其特点和合适的 ...
- APP中RN页面渲染流程-ReactNative源码分析
在APP启动后,RN框架开始启动.等RN框架启动后,就开始进行RN页面渲染了. RN页面原生侧页面渲染的主要逻辑实现是在RCTUIManager和RCTShadowView完成的. 通过看UIMana ...
- C++别名的使用
c++中的别名使用,类似引用,在别名中,"&"的意思不再是取地址,而是建立一个指针,直接指向数据.这是一个小例子: #include <iostream> us ...
- Hive执行计划之hive依赖及权限查询和常见使用场景
目录 概述 1.explain dependency的查询与使用 2.借助explain dependency解决一些常见问题 2.1.识别看似等价的SQL代码实际上是不等价的: 2.2 通过expl ...
- 插件化工程R文件瘦身技术方案 | 京东云技术团队
随着业务的发展及版本迭代,客户端工程中不断增加新的业务逻辑.引入新的资源,随之而来的问题就是安装包体积变大,前期各个业务模块通过无用资源删减.大图压缩或转上云.AB实验业务逻辑下线或其他手段在降低包体 ...
- IAR学习笔记:将app和boot合并
一.前言 最近用到了IAR编译调试软件,但是生成的app.bin和boot.bin是独立分开的,看了下IAR官方note和其他大佬的解释,找到了俩合并的方法: 参考: https://www.iar. ...
- Cronjob 定时任务
Job: 负责处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束. CronJob: 则就是在Job上加上了时间调度. 我们用Job这个资源对象来创建一个任务,我们定一个Job来 ...