《最新出炉》系列初窥篇-Python+Playwright自动化测试-37-如何截图-上篇
1.简介
这个系列的文章也讲解和分享了差不多三分之一吧,突然有小伙伴或者童鞋们问道playwright有没有截图的方法。答案当然是:肯定有的。宏哥回过头来看看确实这个非常基础的知识点还没有讲解和分享。那么在这个契机下就把它插队分享和讲解一下。Playwright提供了一个截屏的API:page.screenshot。使用该API,只需要指定截图的图片的保存路径及文件名即可。如果仅指定文件名,默认保存在当前目录。
2.截图语法
截图介绍官方API的文档地址:https://playwright.dev/python/docs/screenshots
2.1截图参数
screenshot方法可以进行截图,参数如下:
timeout:以毫秒为单位的超时时间,0为禁用超时
path:设置截图的路径
type:图片类型,默认jpg
quality:像素,不适用于jpg
omit_background: 隐藏默认白色背景,并允许捕获具有透明度的屏幕截图。不适用于“jpeg”图像。
full_page:如果为true,则获取完整可滚动页面的屏幕截图,而不是当前可见的视口。默认为
`假`。
clip:指定结果图像剪裁的对象clip={'x': 10 , 'y': 10, 'width': 10, 'height': 10}
3.快速截图(截取当前屏幕)
playwright除了可以截取当前屏幕,还可以截长图,也可以对某个元素截图,是不是炒鸡方便。这是捕获屏幕截图并将其保存到文件中的快速截图(如果仅仅截取当前屏幕(浏览器)上能看到的部分)语法如下:
page.screenshot(path="screenshot.png")
3.1实战示例
# coding=utf-8 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-11-23
@author: 北京-宏哥
公众号:北京宏哥
Project: 《最新出炉》系列初窥篇-Python+Playwright自动化测试-36-如何截图
''' # 3.导入模块
from playwright.sync_api import Playwright, sync_playwright, expect def run(playwright: Playwright) -> None: browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.baidu.com/")
page.screenshot(path='a.png') # 截图
print(page.title())
page.wait_for_timeout(1000)
context.close()
browser.close() with sync_playwright() as playwright:
run(playwright)
3.2运行代码
1.运行代码,右键Run'Test',就可以看到截图和控制台输出,如下图所示:
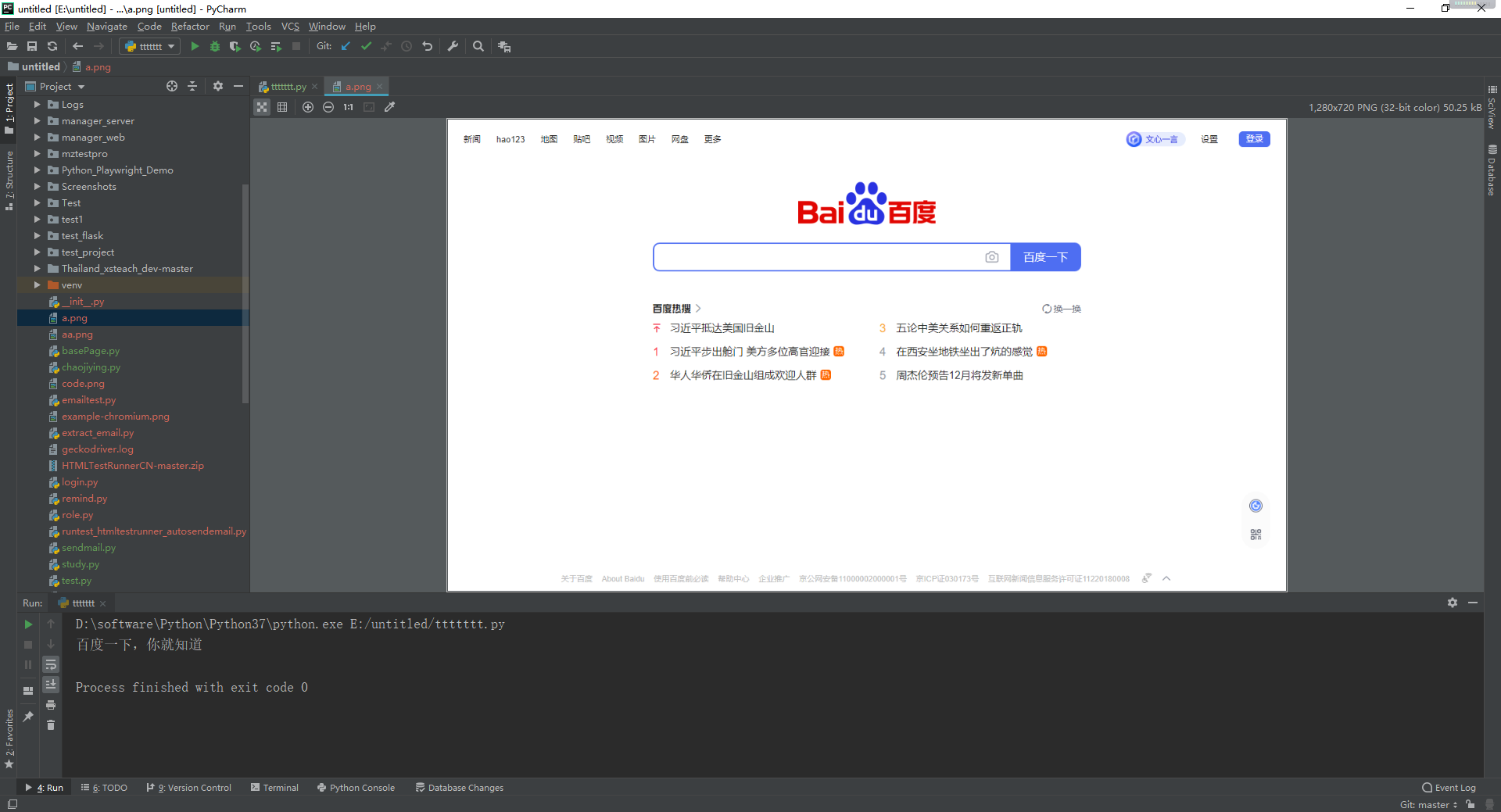
2.运行代码后电脑端的浏览器的动作。如下图所示:

4.整页截图(截取整个页面)
有时候,页面可能会比较长,一个屏幕无法全部展示出来。如果想截取整个页面,怎么办呢?设置full_page=True 参数 screenshot 是一个完整的可滚动页面的屏幕截图,就好像你有一个非常高的屏幕并且页面可以完全容纳它。
playwright屏幕截图语法如下:
page.screenshot(path="screenshot.png", full_page=True)
4.1实战示例
# coding=utf-8 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-11-23
@author: 北京-宏哥
公众号:北京宏哥
Project: 《最新出炉》系列初窥篇-Python+Playwright自动化测试-36-如何截图
''' # 3.导入模块
from playwright.sync_api import Playwright, sync_playwright, expect def run(playwright: Playwright) -> None: browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.baidu.com/")
page.screenshot(path="screenshot.png", full_page=True) # 截图
print(page.title())
page.wait_for_timeout(1000)
context.close()
browser.close() with sync_playwright() as playwright:
run(playwright)
4.2运行代码
1.运行代码,右键Run'Test',就可以看到截图和控制台输出,如下图所示:
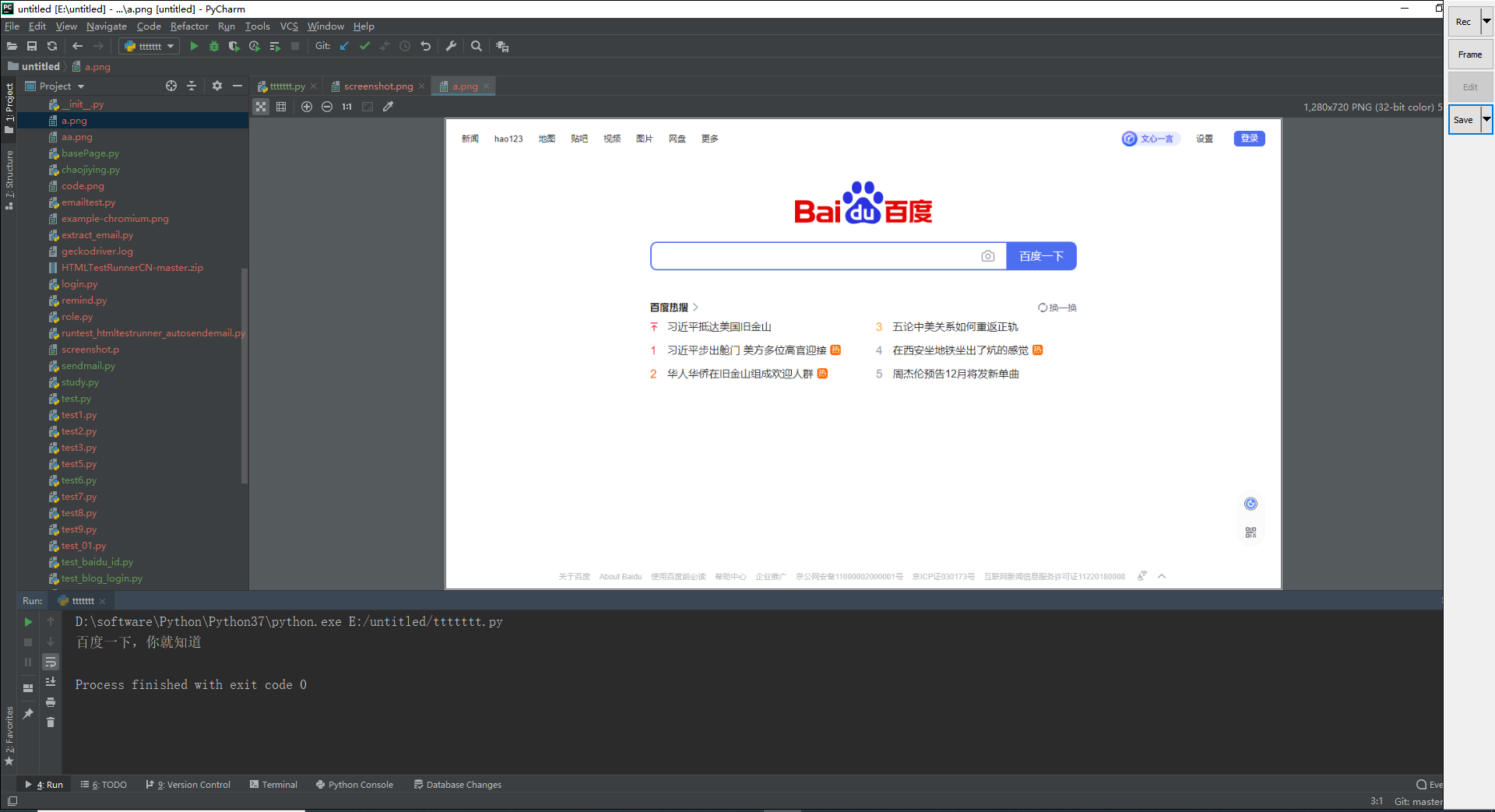
2.运行代码后电脑端的浏览器的动作。如下图所示:

5.小结
好了,今天时间不早了,关于playwright的截图就先介绍讲解到这里,下一篇继续介绍截图的其他操作方法。感谢您耐心的阅读!!!
《最新出炉》系列初窥篇-Python+Playwright自动化测试-37-如何截图-上篇的更多相关文章
- python web自动化测试中失败截图方法汇总
在使用web自动化测试中,用例失败则自动截图的网上也有,但实际能落地的却没看到,现总结在在实际应用中失败截图的几种方法: 一.使用unittest框架截图方法: 1.在tearDown中写入截图的 ...
- Flutter 即学即用系列博客——04 Flutter UI 初窥
前面三篇可以算是一个小小的里程碑. 主要是介绍了 Flutter 环境的搭建.如何创建 Flutter 项目以及如何在旧有 Android 项目引入 Flutter. 这一篇我们来学习下 Flutte ...
- Spark系列-初体验(数据准备篇)
Spark系列-初体验(数据准备篇) Spark系列-核心概念 在Spark体验开始前需要准备环境和数据,环境的准备可以自己按照Spark官方文档安装.笔者选择使用CDH集群安装,可以参考笔者之前的文 ...
- Python系列之入门篇——HDFS
Python系列之入门篇--HDFS 简介 HDFS (Hadoop Distributed File System) Hadoop分布式文件系统,具有高容错性,适合部署在廉价的机器上.Python ...
- Python系列之入门篇——MYSQL
Python系列之入门篇--MYSQL 简介 python提供了两种mysql api, 一是MySQL-python(不支持python3),二是PyMYSQL(支持python2和python3) ...
- python爬虫 scrapy2_初窥Scrapy
sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campai ...
- WWDC15 Session笔记 - Xcode 7 UI 测试初窥
https://onevcat.com/2015/09/ui-testing/ WWDC15 Session笔记 - Xcode 7 UI 测试初窥 Unit Test 在 iOS 开发中已经有足够多 ...
- Scrapy001-框架初窥
Scrapy001-框架初窥 @(Spider)[POSTS] 1.Scrapy简介 Scrapy是一个应用于抓取.提取.处理.存储等网站数据的框架(类似Django). 应用: 数据挖掘 信息处理 ...
- 初窥Kaggle竞赛
初窥Kaggle竞赛 原文地址: https://www.dataquest.io/mission/74/getting-started-with-kaggle 1: Kaggle竞赛 我们接下来将要 ...
- scrapy2_初窥Scrapy
递归知识:oop,xpath,jsp,items,pipline等专业网络知识,初级水平并不是很scrapy,可以从简单模块自己写. 初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数 ...
随机推荐
- Caused by: java.lang.ClassNotFoundException: javax.servlet.Filter
Caused by: java.lang.NoClassDefFoundError: javax/servlet/Filter at java.lang.Class.getDeclaredMethod ...
- Kubernetes(K8S) 镜像拉取策略 imagePullPolicy
镜像仓库,镜像已更新,版本没更新, K8S 拉取后,还是早的服务,原因:imagePullPolicy 镜像拉取策略 默认为本地有了就不拉取,需要修改 [root@k8smaster ~]# kube ...
- 愉快的了解Charles
charles是PC端常用的网络封包截取工具,在做移动开发时,我们为了调试与服务器端的网络通讯协议,常常需要截取网络封包来分析.除了在做移动开发中调式端口外,charles也可以用于分析第三方应用的通 ...
- 【HZERO】宏函数
宏函数配置
- 「Codeforces 1131D」Gourmet Choice
Description 美食家 Apple 先生是一家美食杂志的主编.他会用一个正整数来评价每一道菜. 美食家在第一天品尝第 $n$ 道菜,第二天品尝了 $m$ 道菜.他制作了一张 $n\times ...
- AtCoder Beginner Contest 180 个人题解(快乐DP场)
补题链接:Here A - box 输出 \(N - A + B\) B - Various distances 按题意输出 3 种距离即可 #include <bits/stdc++.h> ...
- 图扑虚拟现实解决方案,实现 VR 数智机房
前言 如今,虚拟现实技术作为连接虚拟世界和现实世界的桥梁,正加速各领域应用形成新场景.新模式.新业态. 效果展示 图扑软件基于自研可视化引擎 HT for Web 搭建的 VR 数据中心机房,是将数据 ...
- asp.net core之实时应用
本文将介绍ASP.NET Core SignalR,这是一个强大的实时通信库,用于构建实时.双向通信应用程序.我们将探讨SignalR的基本概念.架构和工作原理,并提供一些示例代码来帮助读者更好地理解 ...
- AHB-SRAMC Design-03
SRAMC SRAM CORE 8块memory进行广播信号,例化8片memory
- [转帖]windows10彻底关闭Windows Defender的4种方法
https://zhuanlan.zhihu.com/p/495107049 Windows Defender是windows10系统自带的杀毒软件.默认情况下它处于打开的状态.大多数第三方的杀毒软件 ...