基于Docker Desktop搭建Kafka集群并使用Java编程开发
一、引言
前段时间因课业要求使用Docker Desktop 部署Kafka集群并编写生产者消费者程序,折磨了我好几天,在查找大量资料后终于是把整个集群搭建完成了。现在我想要分享其中搭建的历程,希望能为大家解决问题。
二、Docker集群构建
安装环境:
Windows 10
2.1 启用或关闭windows功能中勾选适用于linux的子系统,重启机器

启用或关闭windows功能
2.2 windows power shell 中检查wsl的更新:
wsl --update
2.3 Docker官网下载Docker Desktop Installer
(下载链接:https://docs.docker.com/desktop/install/windows-install/)
2.4 Docker 安装
在power shell中下载存放Docker Desktop Installer.exe 路径下执行以下命令: (如果直接点击exe安装它会给你默认会安装到C盘)
"Docker Desktop Installer.exe" install --installation-dir=<path>
注意: <path>替换为你需要安装Docker Desktop的路径
Docker Desktop启动界面
2.5 Docker相关配置
设置Docker 的镜像存储位置
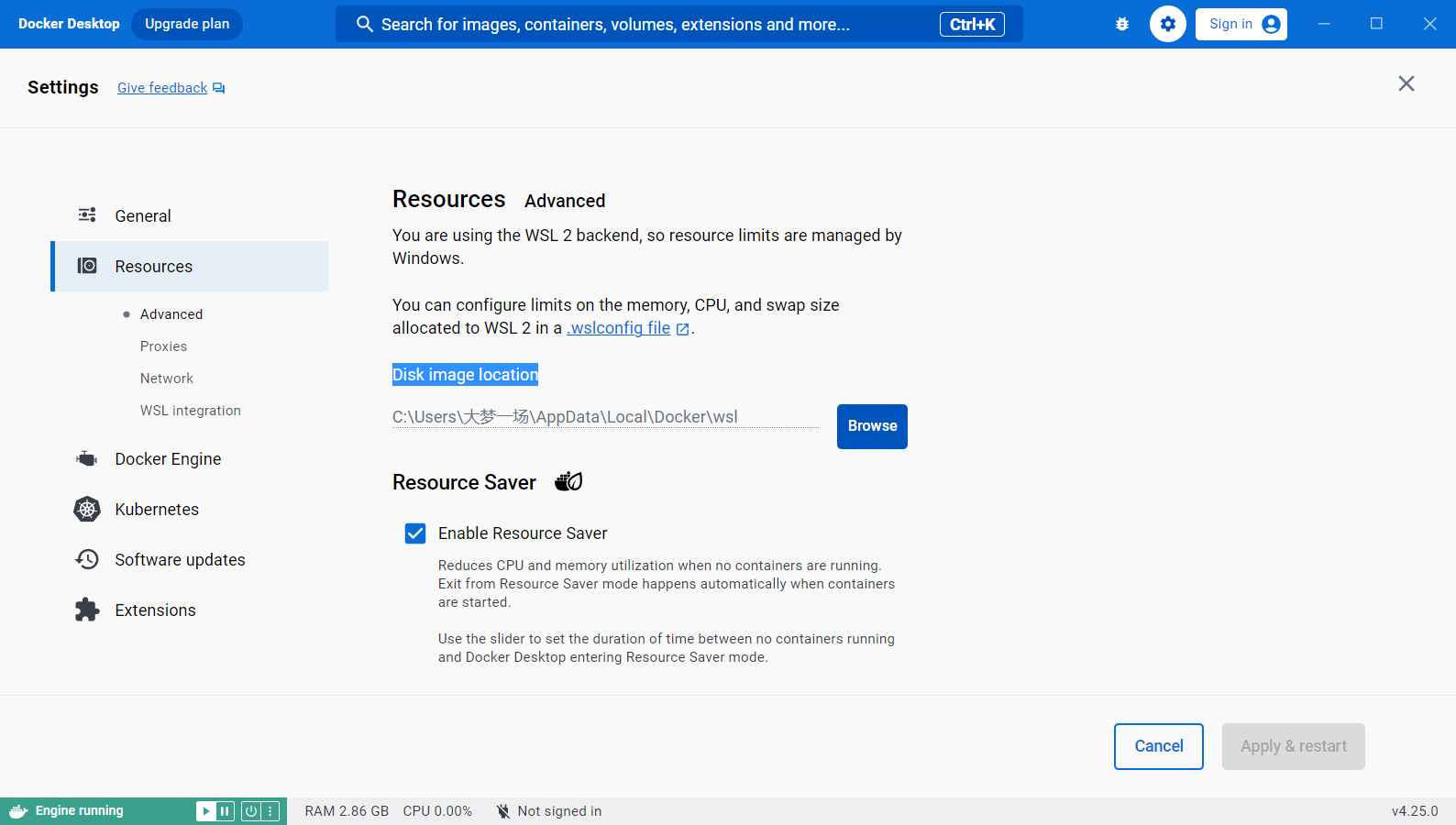 Docker 的镜像存储位置
Docker 的镜像存储位置
路径:Settings/Resources/Advanced
设置Dock 镜像源
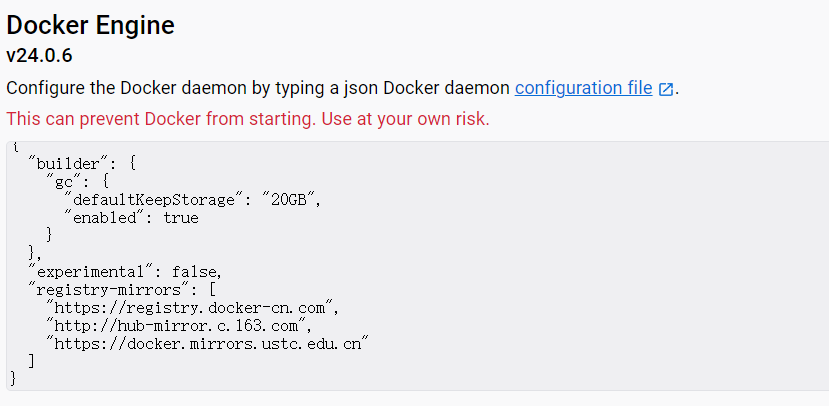 Docker Desktop镜像仓库
Docker Desktop镜像仓库
"registry-mirrors": [
"https://registry.docker-cn.com",
"http://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn"
]
路径:Settings/Docker Engine
三、Kafka集群构建
3.1 创建docker 网络 (在不指定参数的情况下创建的是bridge网络)
docker network create zk-net
查看创建的docker 网络
docker network ls
3.2 编写kafka 与 zookeeper的yml文件
kafka.yml文件的编写
version: "3" networks:
zk-net:
external:
name: zk-net services:
zoo1:
image: 'zookeeper:3.8.2'
container_name: zoo1
hostname: zoo1
environment:
ZOO_MY_ID: 1
ZOO_SERVERS: server.1=0.0.0.0:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181
ALLOW_ANONYMOUS_LOGIN: "yes"
networks:
- zk-net
ports: #端口映射
- 2181:2181
- 8081:8080
volumes: #挂载文件
- /E/Kcluster/zookeeper/zoo1/data:/data
- /E/Kcluster/zookeeper/zoo1/datalog:/datalog
zoo2:
image: 'zookeeper:3.8.2'
container_name: zoo2
hostname: zoo2
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=0.0.0.0:2888:3888;2181 server.3=zoo3:2888:3888;2181
ALLOW_ANONYMOUS_LOGIN: "yes"
networks:
- zk-net
ports:
- 2182:2181
- 8082:8080
volumes:
- /E/Kcluster/zookeeper/zoo2/data:/data
- /E/Kcluster/zookeeper/zoo2/datalog:/datalog
zoo3:
image: 'zookeeper:3.8.2'
container_name: zoo3
hostname: zoo3
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=0.0.0.0:2888:3888;2181
ALLOW_ANONYMOUS_LOGIN: "yes"
networks:
- zk-net
ports:
- 2183:2181
- 8083:8080
volumes:
- /E/Kcluster/zookeeper/zoo3/data:/data
- /E/Kcluster/zookeeper/zoo3/datalog:/datalog
kafka01:
image: 'bitnami/kafka:2.7.0'
restart: always
container_name: kafka01
hostname: kafka01
ports:
- '9093:9093'
environment:
- ALLOW_NONE_AUTHENTICATION=yes
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_BROKER_ID=1
- KAFKA_CFG_LISTENERS=PLAINTEXT://0.0.0.0:9093
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka01:9093
- KAFKA_CFG_ZOOKEEPER_CONNECT=zoo1:2181,zoo2:2181,zoo3:2181
volumes:
- /E/Kcluster/kafka/kafka1:/bitnami/kafka
networks:
- zk-net
kafka02:
image: 'bitnami/kafka:2.7.0'
restart: always
container_name: kafka02
hostname: kafka02
ports:
- '9094:9094'
environment:
- ALLOW_NONE_AUTHENTICATION=yes
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_BROKER_ID=2
- KAFKA_CFG_LISTENERS=PLAINTEXT://0.0.0.0:9094
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka02:9094
- KAFKA_CFG_ZOOKEEPER_CONNECT=zoo1:2181,zoo2:2181,zoo3:2181
volumes:
- /E/Kcluster/kafka/kafka2:/bitnami/kafka
networks:
- zk-net
kafka03:
image: 'bitnami/kafka:2.7.0'
restart: always
container_name: kafka03
hostname: kafka03
ports:
- '9095:9095'
environment:
- ALLOW_NONE_AUTHENTICATION=yes
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_BROKER_ID=3
- KAFKA_CFG_LISTENERS=PLAINTEXT://0.0.0.0:9095
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka03:9095 #kafka真正bind的地址
- KAFKA_CFG_ZOOKEEPER_CONNECT=zoo1:2181,zoo2:2181,zoo3:2181 #暴露给外部的listeners,如果没有设置,会用listeners
volumes:
- /E/Kcluster/kafka/kafka3:/bitnami/kafka
networks:
- zk-net
需要注意的是,后续的Java API 的使用依赖于 KAFKA_CFG_ADVERTISED_LISTENERS
如果你使用的是 KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka03:9095 这种格式 需要在 C:\Windows\System32\drivers\etc 路径下修改host文件加入
127.0.0.1 kafka01
127.0.0.1 kafka02
127.0.0.1 kafka03
如果使用IP地址则不需要
3.3 拉取Kafka搭建需要的镜像,这里我选择zookeeper 和 kafka 镜像版本为:
zookeeper:3.8.2
bitnami/kafka:2.7.0
键入命令拉取镜像:
docker pull zookeeper:3.8.2
docker pull bitnami/kafka:2.7.0
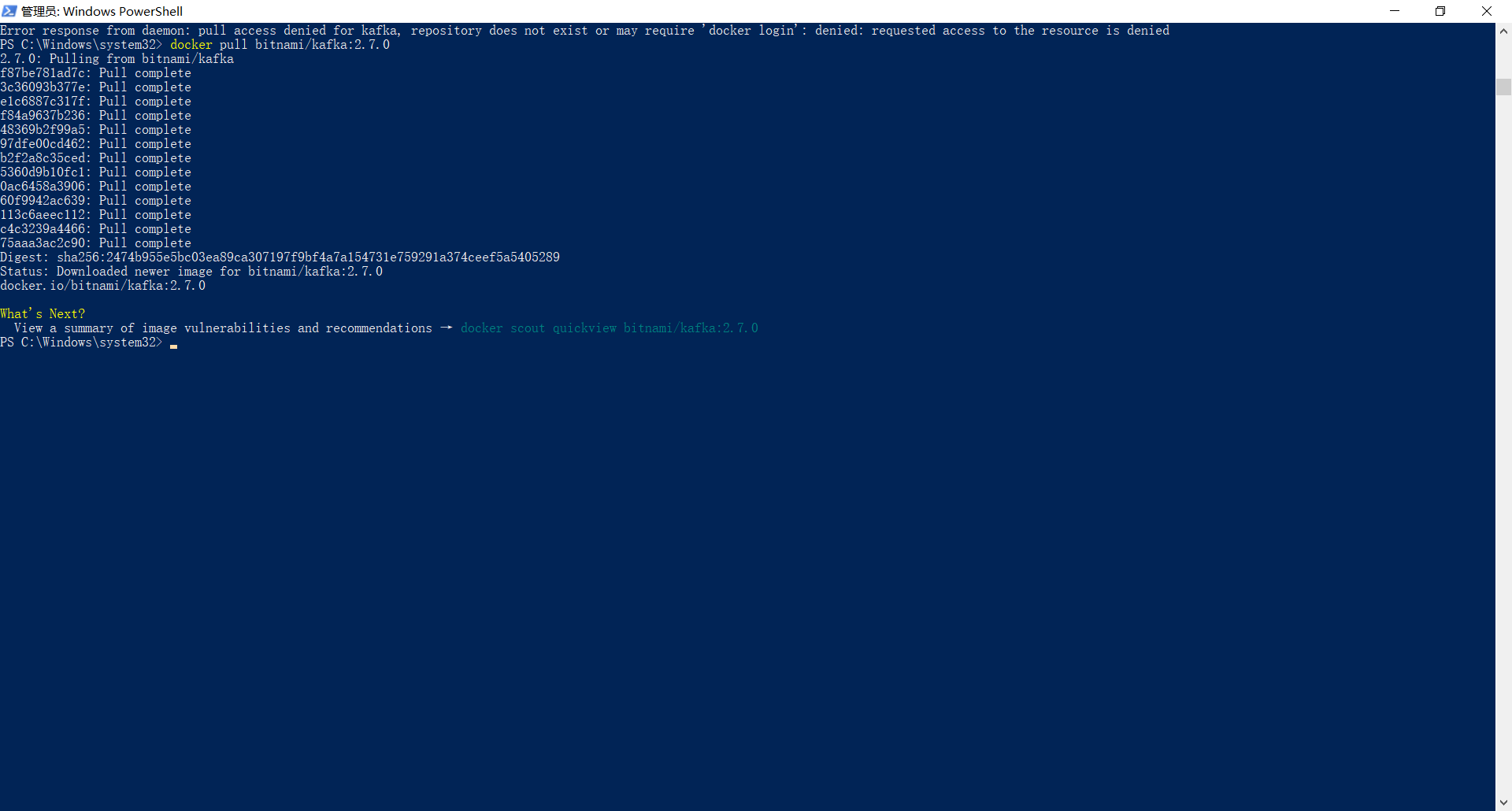
kafka镜像拉取
3.4 使用docker-compose 构建集群
在power shell中执行以下命令:
docker-compose -f E:\Kcluster\docker-compose_kafka.yml up -d

docker-compose 构建集群
图中可以看到kafka集群已经被创建起来了:

kafka集群 展示
启动集群:
docker-compose -f E:\Kcluster\docker-compose_kafka.yml start
停止集群:
docker-compose -f E:\Kcluster\docker-compose_kafka.yml stop
删除集群:
docker-compose -f E:\Kcluster\docker-compose_kafka.yml down
四、Kafka Java API
4.1 相关环境的配置
新建一个maven 项目 在xml中配置如下:
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
</dependencies>
拉取依赖
4.2 编写生产者代码
新建类:KafkaTest.class
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; public class KafkaTest {
public static void main(String[] args) {
Properties props = new Properties();
//参数设置
//1.指定Kafaka集群的ip地址和端口号
props.put("bootstrap.servers", "kafka01:9093,kafka02:9094,kafka03:9095");
//2.等待所有副本节点的应答
props.put("acks", "all");
//3.消息发送最大尝试次数
props.put("retries", 1);
//4.指定一批消息处理次数
props.put("batch.size", 16384);
//5.指定请求延时
props.put("linger.ms", 1);
//6.指定缓存区内存大小
props.put("buffer.memory", 33554432);
//7.设置key序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//8.设置value序列化
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 9、生产数据
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
for (int i = 0; i < 50; i++) {
producer.send(new ProducerRecord<String, String>("mytopic", Integer.toString(i), "hello kafka-" + i));
System.out.println(i);
}
producer.close();
} }
注意,props.put("bootstrap.servers", "kafka01:9093,kafka02:9094,kafka03:9095");
如果是按上述yml配置,不需修改。如果你使用ip地址 替换kafka01,kafka02,kafka03 则使用IP地址:端口号
具体原因可见:
Kafka学习理解-listeners配置 - 孙行者、 - 博客园 (cnblogs.com)
docker 部署kafka,listeners配置 - 我的天啊~ - 博客园 (cnblogs.com)
4.3 编写消费者代码
新建类:ConsumerDemo.class
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer; import java.time.Duration;
import java.util.Collections;
import java.util.Objects;
import java.util.Properties; public class ConsumerDemo{ public static void main(String[] args) {
Properties properties=new Properties(); properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"kafka01:9093,kafka02:9094,kafka03:9095"); properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); //配置消费者组(必须)
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"group1"); properties.put("enable.auto.commit", "true");
// 自动提交offset,每1s提交一次
properties.put("auto.commit.interval.ms", "1000");
properties.put("auto.offset.reset","earliest ");
properties.put("client.id", "zy_client_id");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
// 订阅test1 topic
consumer.subscribe(Collections.singletonList("mytopic")); while(true) {
// 从服务器开始拉取数据
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
if(Objects.isNull(records)){
continue;
}
for(ConsumerRecord<String,String> record : records){
System.out.printf("topic=%s,offset=%d,key=%s,value=%s%n", record.topic(), record.offset(), record.key(), record.value());
} }
} }
运行结果如下:
生产者:
消费者:
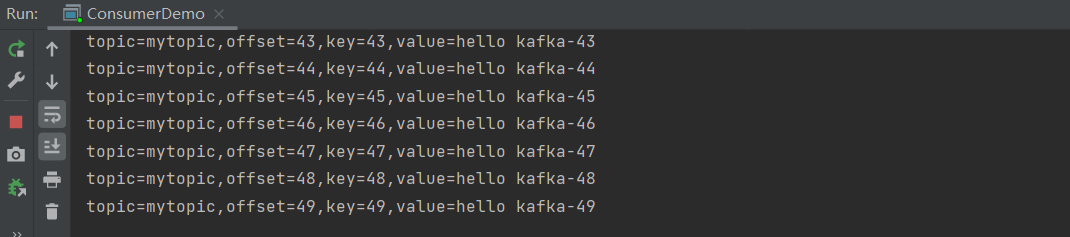
至此整个集群的构建与测试结束。
基于Docker Desktop搭建Kafka集群并使用Java编程开发的更多相关文章
- 用 Docker 快速搭建 Kafka 集群
开源Linux 一个执着于技术的公众号 版本 •JDK 14•Zookeeper•Kafka 安装 Zookeeper 和 Kafka Kafka 依赖 Zookeeper,所以我们需要在安装 Kaf ...
- 基于docker快速搭建hbase集群
一.概述 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文"Bigtable:一个结构化数据的分布式存储系统".就像Bigt ...
- Docker实战之Kafka集群
1. 概述 Apache Kafka 是一个快速.可扩展的.高吞吐.可容错的分布式发布订阅消息系统.其具有高吞吐量.内置分区.支持数据副本和容错的特性,适合在大规模消息处理场景中使用. 笔者之前在物联 ...
- 什么是kafka以及如何搭建kafka集群?
一.Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据. Kafka场景比喻 接下来我大概比喻下Kafka的使用场景 消息中间件:生产者和消费者 妈妈:生产 ...
- 庐山真面目之十微服务架构 Net Core 基于 Docker 容器部署 Nginx 集群
庐山真面目之十微服务架构 Net Core 基于 Docker 容器部署 Nginx 集群 一.简介 前面的两篇文章,我们已经介绍了Net Core项目基于Docker容器部署在Linux服 ...
- docker-compose 搭建kafka集群
docker-compose搭建kafka集群 下载镜像 1.wurstmeister/zookeeper 2.wurstmeister/kafka 3.sheepkiller/kafka-manag ...
- 如何基于Jupyter notebook搭建Spark集群开发环境
摘要:本文介绍如何基于Jupyter notebook搭建Spark集群开发环境. 本文分享自华为云社区<基于Jupyter Notebook 搭建Spark集群开发环境>,作者:apr鹏 ...
- 大数据平台搭建-kafka集群的搭建
本系列文章主要阐述大数据计算平台相关框架的搭建,包括如下内容: 基础环境安装 zookeeper集群的搭建 kafka集群的搭建 hadoop/hbase集群的搭建 spark集群的搭建 flink集 ...
- centos7搭建kafka集群-第二篇
好了,本篇开始部署kafka集群 Zookeeper集群搭建 注:Kafka集群是把状态保存在Zookeeper中的,首先要搭建Zookeeper集群(也可以用kafka自带的ZK,但不推荐) 1.软 ...
- Kafka学习之(六)搭建kafka集群
想要搭建kafka集群,必须具备zookeeper集群,关于zookeeper集群的搭建,在Kafka学习之(五)搭建kafka集群之Zookeeper集群搭建博客有说明.需要具备两台以上装有zook ...
随机推荐
- LeetCode952三部曲之三:再次优化(122ms -> 96ms,超51% -> 超91%)
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本文是<LeetCode952三部曲之 ...
- Go 语言内置类型全解析:从布尔到字符串的全维度探究
关注微信公众号[TechLeadCloud],分享互联网架构.云服务技术的全维度知识.作者拥有10+年互联网服务架构.AI产品研发经验.团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证 ...
- Python爬虫IP代理池的建立和使用
写在前面建立Python爬虫IP代理池可以提高爬虫的稳定性和效率,可以有效避免IP被封锁或限制访问等问题. 下面是建立Python爬虫IP代理池的详细步骤和代码实现: 1. 获取代理IP我们可以从一些 ...
- Redis系列之——主从复制原理与优化、缓存的使用和优化
@ 目录 一 什么是主从复制 1.1 原理 1.2 主库是否要开启持久化 1.3 辅助配置(主从数据一致性配置) 二 复制的 配置 2.1 slave 命令 2.2 配置文件 四 故障处理 五 复制常 ...
- 编译python为可执行文件遇到的问题:使用python-oracledb连接oracle数据库时出现错误:DPY-3010
错误原文: DPY-3010: connections to this database server version are not supported by python-oracledb in ...
- oj练习题程序编程题
打印图形Description按要求输出由*组成的图案Input无需输入Output输出下面由"组成的图案卡 11 print('*') print("***") pri ...
- vue2.0组件之间传递数据
vue2.0组件之间传递数据 一,父向子 当父组件向子组件传数据的时候用这种方法比较简单.步骤为: 1,在子组件中声明props 2,在父组件中使用子组件时传入数据 二,组件之间 在组件之间如果两个组 ...
- 一些对dp突然的理解
突然想到了一些理解,感觉有些模糊,怕忘记,就赶紧记下来就是对于状态的设计 用01背包举例子吧,我们设计状态的时候一定是要保证所有可能在最后优秀的子状态在前面的时候是能够保留下来的也就是我们的状态设计要 ...
- [glibc] 带着问题看源码 —— exit 如何调用 atexit 处理器
前言 之前在写 apue 系列的时候,曾经对系统接口的很多行为产生过好奇,当时就想研究下对应的源码,但是苦于 linux 源码过于庞杂,千头万绪不知从何开启,就一直拖了下来. 最近在查一个问题时无意间 ...
- 18.1 Socket 原生套接字抓包
原生套接字抓包的实现原理依赖于Windows系统中提供的ioctlsocket函数,该函数可将指定的网卡设置为混杂模式,网卡混杂模式(Promiscuous Mode)是常用于计算机网络抓包的一种模式 ...