mr的partition分区
1、Partitioner 组件通过让 Map 对 Key 进行分区,从而将不同分区的 Key 交由不同的 Reduce 处理。Partition属于map端
2、分区的总数与任务的reduce任务数相同
partitioner定义:
partitioner的作用是将mapper 输出的key/value拆分为分片(shard),每个reducer对应一个分片。
默认情况下,partitioner先计算key的散列值(hash值)。然后通过reducer个数执行取模运算:key.hashCode%(reducer个数)。这样能够随机地将整个key空间平均分发给每个reducer,同时也能确保不同mapper产生的相同key能被分发到同一个reducer。
以下图片截取自Hadoop权威指南(第三版)

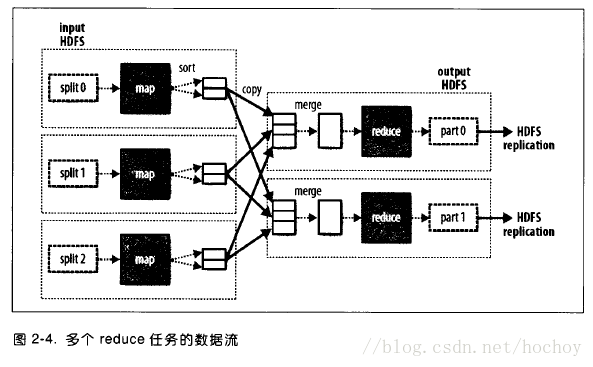

目的:
可以使用自定义Partitioner来达到reducer的负载均衡, 提高效率。
适用范围:
需要非常注意的是:必须提前知道有多少个分区。比如自定义Partitioner会返回4个不同int值,而reducer number设置了小于4,那就会报错。所以我们可以通过运行分析任务来确定分区数。
例如,有一堆包含时间戳的数据,但是不知道它能追朔到的时间范围,此时可以运行一个作业来计算出时间范围。
注意:
在自定义partitioner时一定要注意防止数据倾斜。
从以上源码我们可以看到Partitioner 抽象类由getPartition(KEY key, VALUE value, int numPartitions)方法组成,起三个参数分别为:(KEY key, VALUE value, int numPartitions)
一下大概对此方法做简要说明:
1)key、value分别指的是Mapper任务的输出
2)numReduceTasks指的是设置的Reducer任务数量,默认值是1,numReduceTasks指的是设置的Reducer任务数量,默认值是1
以下做一个简单的例子以供参考:
class ThePartitioner extends Partitioner<Text, Text> {
@Override
public int getPartition(Text key, Text value,
int numPartitions) {
Long l = Long.valueOf((key.hashCode() - Integer.MAX_VALUE) % numPartitions);
return Math.abs(Integer.parseInt(l.toString()));
}
}
————————————————
版权声明:本文为CSDN博主「hochoy」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/hochoy/article/details/79633712
mr的partition分区的更多相关文章
- mysql Partition(分区)初探
mysql Partition(分区)初探 表数据量大的时候一般都考虑水平拆分,即所谓的sharding.不过mysql本身具有分区功能,可以实现一定程度 的水平切分. mysql是具有MERG ...
- MySQL partition分区I
http://blog.csdn.net/binger819623/article/details/5280267 一. 分区的概念二. 为什么使用分区?(优点)三. ...
- MYSQL之水平分区----MySQL partition分区I(5.1)
一. 分区的概念 二. 为什么使用分区?(优点) 三. 分区类型 四. 子分区 五. 对分区进行修改(增加.删除.分解.合并) 六 ...
- kafka之partition分区及副本replica升级
修改kafka的partition分区 bin/kafka-topics.sh --zookeeper datacollect-2:2181 --alter --partitions 3 --topi ...
- mysql的partition分区
前言:当一个表里面存储的数据特别多的时候,比如单个.myd数据都已经达到10G了的话,必然导致读取的效率很低,这个时候我们可以采用把数据分到几张表里面来解决问题.方式一:通过业务逻辑根据数据的大小通过 ...
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- Hadoop值Partition分区
分区操作 为什么要分区? 要求将统计结果按照条件输出到不同文件中(分区).比如:将统计结果按 照手机归属地不同省份输出到不同文件中(分区) 默认 partition 分区 /** 源码中:numRed ...
- oracle partition 分区
--范围分区create table person( id int, name varchar2(20), birth date, sex char(2))partition by range (bi ...
- MR案例:分区和排序
现有一学生成绩数据,格式如下:<学号,姓名,学院,成绩> //<id, name, institute, grade>. 需求描述:查询成绩大于等于60分的学生数据,按学院分 ...
随机推荐
- SpringBoot整合MybatisPlus3.X之自定义Mapper(十)
pom.xml <dependencies> <dependency> <groupId>org.springframework.boot</groupId& ...
- 2019.NET Conf,我们在共同期待
(一)回顾一个小社区红过的五分钟 不知不觉,距离中国.net社区组织的.net conf只有不到一周的时间,还记得年初在叶伟民老师,潘淳老师和张善友老师的号召下,我们长沙的十几位开发者自发组织起来,拉 ...
- js 的隐式转换与显式转换
隐式转换 1.undefined与null相等,但不恒等(===) 2.一个是number一个是string时,会尝试将string转换为number 3.隐式转换将boolean转换为numbe ...
- 面向云原生的混沌工程工具-ChaosBlade
作者 | 肖长军(穹谷)阿里云智能事业群技术专家 导读:随着云原生系统的演进,如何保障系统的稳定性受到很大的挑战,混沌工程通过反脆弱思想,对系统注入故障,提前发现系统问题,提升系统的容错能力.Ch ...
- 一个开源组件 bug 引发的分析
这是一个悲伤的故事.某日清晨,距离版本转测还剩一天,切图仔的我正按照计划有条不紊的画页面.当我点击一个下拉弹框组件中分页组件页数过多而出现的向后 5 页省略号时,悲剧开始了,弹框被收回了.情景再现 问 ...
- 第二十六章 system v消息队列(二)
msgsnd int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg); 作用: 把一条消息添加到消息队列中 参数: msqi ...
- 「刷题」Triple
正解是普通型母函数+FFT. 才学了多项式,做了一道比较好的题了. 首先有三个斧子被偷了. 我们考虑构造一种普通型母函数. 就是说一种多项式吧,我的理解. 系数是方案,下标,也就是所谓的元指数代表的是 ...
- Maven配置setting.xml详细说明
<?xml version="1.0" encoding="UTF-8"?> <settings xmlns="http://mav ...
- 使用Typescript重构axios(三十)——添加axios.getUri方法
0. 系列文章 1.使用Typescript重构axios(一)--写在最前面 2.使用Typescript重构axios(二)--项目起手,跑通流程 3.使用Typescript重构axios(三) ...
- Vmware虚拟机的安装
Vmware WorkStation是一款桌面计算机虚拟软件,能够让用户在单一主机上同时运行多个不同的操作系统.每个虚拟操作系统的硬盘分区.数据配置都是独立的,同时又可以将多台虚拟机构建为一个局域网. ...