mr的partition分区
1、Partitioner 组件通过让 Map 对 Key 进行分区,从而将不同分区的 Key 交由不同的 Reduce 处理。Partition属于map端
2、分区的总数与任务的reduce任务数相同
partitioner定义:
partitioner的作用是将mapper 输出的key/value拆分为分片(shard),每个reducer对应一个分片。
默认情况下,partitioner先计算key的散列值(hash值)。然后通过reducer个数执行取模运算:key.hashCode%(reducer个数)。这样能够随机地将整个key空间平均分发给每个reducer,同时也能确保不同mapper产生的相同key能被分发到同一个reducer。
以下图片截取自Hadoop权威指南(第三版)

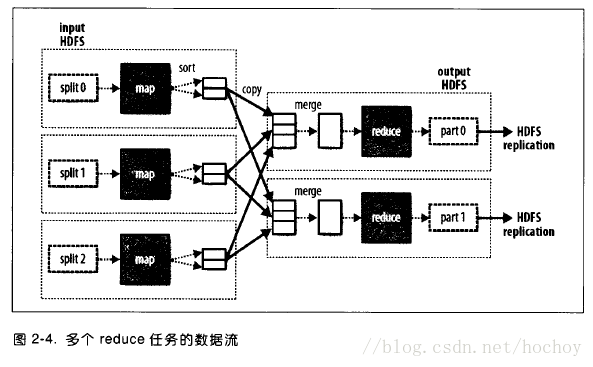

目的:
可以使用自定义Partitioner来达到reducer的负载均衡, 提高效率。
适用范围:
需要非常注意的是:必须提前知道有多少个分区。比如自定义Partitioner会返回4个不同int值,而reducer number设置了小于4,那就会报错。所以我们可以通过运行分析任务来确定分区数。
例如,有一堆包含时间戳的数据,但是不知道它能追朔到的时间范围,此时可以运行一个作业来计算出时间范围。
注意:
在自定义partitioner时一定要注意防止数据倾斜。
从以上源码我们可以看到Partitioner 抽象类由getPartition(KEY key, VALUE value, int numPartitions)方法组成,起三个参数分别为:(KEY key, VALUE value, int numPartitions)
一下大概对此方法做简要说明:
1)key、value分别指的是Mapper任务的输出
2)numReduceTasks指的是设置的Reducer任务数量,默认值是1,numReduceTasks指的是设置的Reducer任务数量,默认值是1
以下做一个简单的例子以供参考:
class ThePartitioner extends Partitioner<Text, Text> {
@Override
public int getPartition(Text key, Text value,
int numPartitions) {
Long l = Long.valueOf((key.hashCode() - Integer.MAX_VALUE) % numPartitions);
return Math.abs(Integer.parseInt(l.toString()));
}
}
————————————————
版权声明:本文为CSDN博主「hochoy」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/hochoy/article/details/79633712
mr的partition分区的更多相关文章
- mysql Partition(分区)初探
mysql Partition(分区)初探 表数据量大的时候一般都考虑水平拆分,即所谓的sharding.不过mysql本身具有分区功能,可以实现一定程度 的水平切分. mysql是具有MERG ...
- MySQL partition分区I
http://blog.csdn.net/binger819623/article/details/5280267 一. 分区的概念二. 为什么使用分区?(优点)三. ...
- MYSQL之水平分区----MySQL partition分区I(5.1)
一. 分区的概念 二. 为什么使用分区?(优点) 三. 分区类型 四. 子分区 五. 对分区进行修改(增加.删除.分解.合并) 六 ...
- kafka之partition分区及副本replica升级
修改kafka的partition分区 bin/kafka-topics.sh --zookeeper datacollect-2:2181 --alter --partitions 3 --topi ...
- mysql的partition分区
前言:当一个表里面存储的数据特别多的时候,比如单个.myd数据都已经达到10G了的话,必然导致读取的效率很低,这个时候我们可以采用把数据分到几张表里面来解决问题.方式一:通过业务逻辑根据数据的大小通过 ...
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- Hadoop值Partition分区
分区操作 为什么要分区? 要求将统计结果按照条件输出到不同文件中(分区).比如:将统计结果按 照手机归属地不同省份输出到不同文件中(分区) 默认 partition 分区 /** 源码中:numRed ...
- oracle partition 分区
--范围分区create table person( id int, name varchar2(20), birth date, sex char(2))partition by range (bi ...
- MR案例:分区和排序
现有一学生成绩数据,格式如下:<学号,姓名,学院,成绩> //<id, name, institute, grade>. 需求描述:查询成绩大于等于60分的学生数据,按学院分 ...
随机推荐
- 【Auto.js images.matchTemplate() 函数的特点】
Auto.js images.matchTemplate() 函数的特点 官方文档:https://hyb1996.github.io/AutoJs-Docs/#/images?id=imagesm ...
- $POJ2942\ Knights\ of\ the\ Round\ Table$ 图论
正解:图论 解题报告: 传送门! 一道,综合性比较强的题(我是萌新刚学$OI$我只是想练下$tarjan$,,,$QAQ$ 考虑先建个补图,然后现在就变成只有相互连边的点不能做邻居.所以如果有$K$个 ...
- InfluxDB常见疑问与解答 - 数据写入时如何在表级别指定保留策略
网友Siguoei:我想让一个库中不同的measurment能够指定不同的保存策略.而不是写入时使用数据库的默认保留策略. Answer:这个特性InfluxDB支持的,写入时序数据时,在行协议前加上 ...
- 货物移动BAPI:BAPI_GOODSMVT_CREATE报错提示“不能执行功能模块 MB_CREATE_GOODS_MOVEMENT”的原因
在开发过程中,我们调用BAPI:BAPI_GOODSMVT_CREATE进行货物移动生成物料凭证时,出现了报错提示:“不能执行功能模块 MB_CREATE_GOODS_MOVEMENT”,如下图所示: ...
- SAP Web Service简介与配置方法
[版权声明]本文为博主原创文章,转载请在明显位置注明出处. 一. SAP Web Service简介 二. SAP Web Service配置准备工作 1. 通过RZ10配置服务器名称和其他参数 2. ...
- 转:nginx和php-fpm的两种通信方式
原文地址:https://segmentfault.com/q/1010000004854045 Nginx和PHP-FPM的进程间通信有两种方式,一种是TCP,一种是UNIX Domain Sock ...
- 《Effective Java》 读书笔记(一) 使用静态构造方法代替传统构造函数
对象的创建与销毁 ITEM1 使用静态工厂方法代替构造函数 传统的新建一个对象的方法是通过构造函数: Foo foo =new Foo(); 一个类也可以提供一个静态方法产生一个对象: Boolean ...
- Oracle Dorp 表数据恢复
利用Oracle 数据回闪机制进行恢复,当一个表被drop掉,表会被放入recyclebin回收站,可通过回收站做表的闪回.表上的索引.约束等同样会被恢复不支持sys/system用户表空间对象,可通 ...
- introduce new products
Today's the day. I'm giving you the heads up. Our company is rolling up its new line of cell phones. ...
- 为什么我加了索引,SQL执行还是这么慢(一)?
在MySQL中,有一些语句即使逻辑相同,执行起来的性能差异确实极大的. 先抛出一个结论:如果想使用索引树搜索功能,就不能使用数据库函数来处理索引字段值,而是在不改变索引字段值的同时,自己通过SQL语句 ...