008.MongoDB分片群集概念及原理
一 MongoDB分片介绍
1.1 分片
1.2 为什么使用分片
- 复制所有的写入操作到主节点
- 延迟的敏感数据会在主节点查询
- 单个副本集限制在12个节点
- 当请求量巨大时会出现内存不足。
- 本地磁盘不足
- 垂直扩展价格昂贵
1.3 分片的优势
- 使用分片减少了每个分片需要处理的请求数:通过水平扩展,群集可以提高自己的存储容量。比如,当插入一条数据时,应用只需要访问存储这条数据的分片。
- 使用分片减少了每个分片存储的数据:分片的优势在于提供类似线性增长的架构,提高数据可用性,提高大型数据库查询服务器的性能。当MongoDB单点数据库服务器存储成为瓶颈、单点数据库服务器的性能成为瓶颈或需要部署大型应用以充分利用内存时,可以使用分片技术。
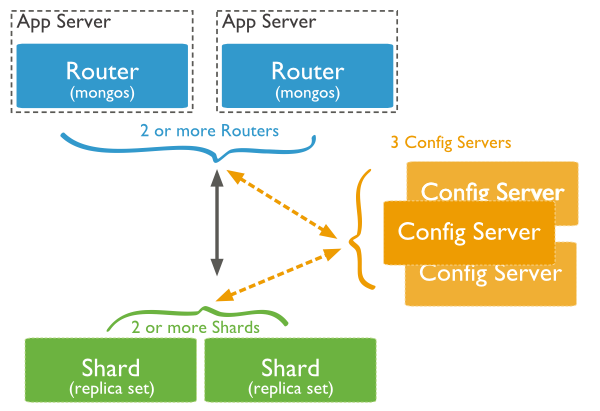
二 MongoDB分片架构
2.1 主要组件

2.2 shard key
2.3 分片集和非分片集
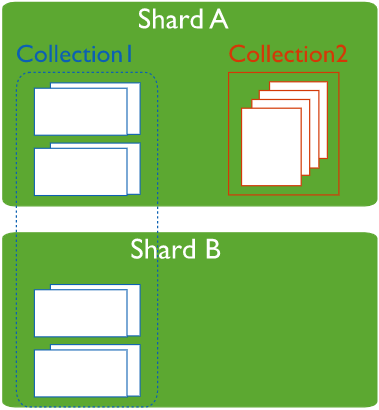
2.4 分片集连接
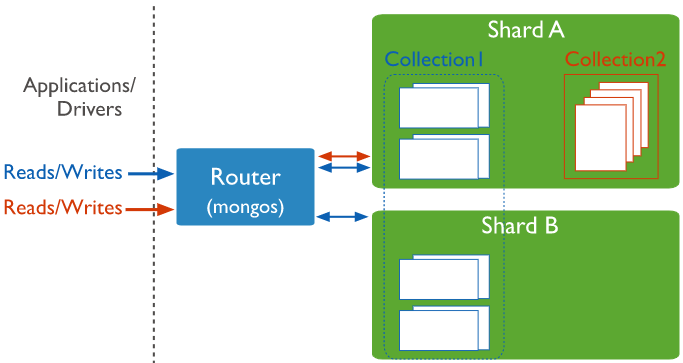
三 分片策略
3.1 基于范围划分
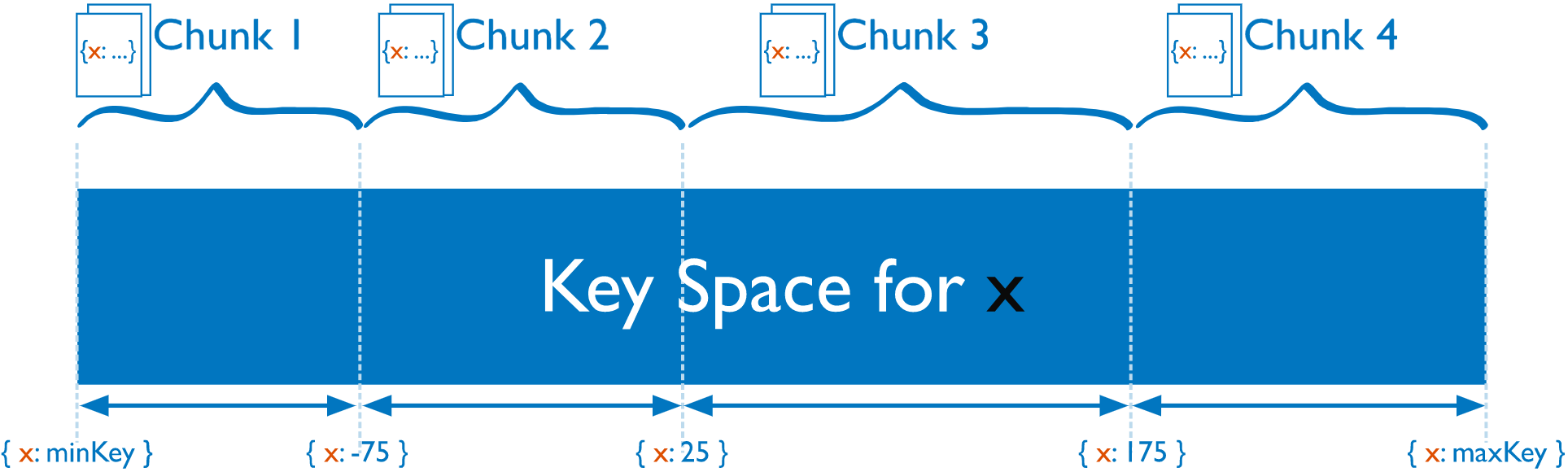
3.2 基于散列划分
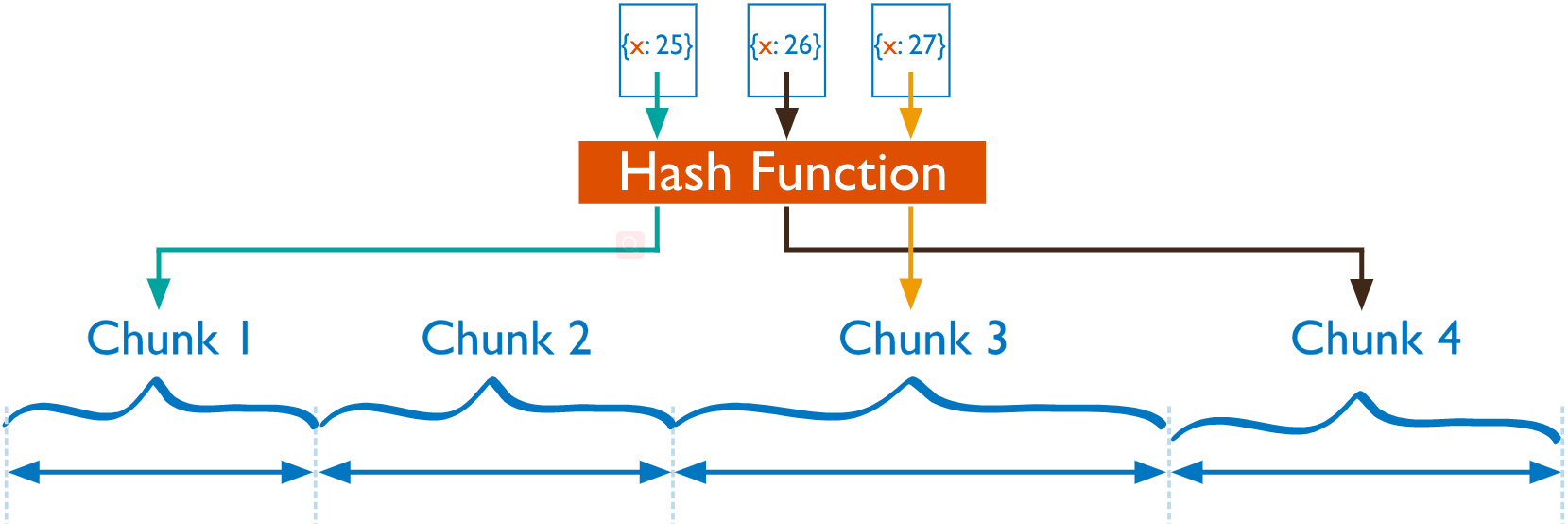
3.3 自定义标签划分
四 数据均衡
4.1 拆分
4.2 平衡
4.3 从集群中增加和删除分片
008.MongoDB分片群集概念及原理的更多相关文章
- MongoDB分片群集的部署(用心描述,详细易懂)!!
概念: MongoDB分片是使用多个服务器存储数据的方法,以支持巨大的数据存储和对数据进行存储 优势: 1.减少了每个分片需啊哟处理的请求数,群集可以提高自己的存储容量和吞吐量 2.减少了每个分片存储 ...
- 【MangoDB分片】配置mongodb分片群集(sharding cluster)
配置mongodb分片群集(sharding cluster) Sharding cluster介绍 这是一种可以水平扩展的模式,在数据量很大时特给力,实际大规模应用一般会采用这种架构去构建monod ...
- 009.MongoDB分片群集部署
一 前期准备 1.1 组件说明 MongoDB分片群集包含以下组件: shard:每个分片是分片数据的子集.从MongoDB 3.6开始,必须将分片部署为副本集. mongos:mongos充当查询路 ...
- mongodb 分片群集(sharding cluster)
实际环境架构 分别在3台机器运行一个mongod实例(称为mongod shard11,mongod shard12,mongod shard13)组织replica set1,作为cluster的s ...
- Mongodb分片集群技术+用户验证
随着数据量持续增多,后续迟早会出现一台机器硬件瓶颈问题的.而mongodb主打的就是海量数据架构,“分片”就用这个来解决这个问题. 从图中可以看到有四个组件:mongos.config server. ...
- MongoDB 分片集群
每日一句 Medalist don't grow on trees, you have to nurture them with love, with hard work, with dedicati ...
- MongoDB分片集群-Sharded Cluster
分片概念 分片(sharding)是一种跨多台机器分布数据的方法, MongoDB使用分片来支持具有非常大的数据集和高吞吐量操作的部署. 换句话说:分片(sharding)是指将数据拆分,将其分散存在 ...
- MySQL Cluster 与 MongoDB 复制群集分片设计及原理
分布式数据库计算涉及到分布式事务.数据分布.数据收敛计算等等要求 分布式数据库能实现高安全.高性能.高可用等特征,当然也带来了高成本(固定成本及运营成本),我们通过MongoDB及MySQL Clus ...
- MongoDB 分片的原理、搭建、应用
一.概念: 分片(sharding)是指将数据库拆分,将其分散在不同的机器上的过程.将数据分散到不同的机器上,不需要功能强大的服务器就可以存储更多的数据和处理更大的负载.基本思想就是将集合切成小块,这 ...
随机推荐
- 可编程实验板EPM1270T144C5蜂鸣器音调频率选择
always@(tone) begin case(tone) 'd1 : time_end=10'd1911 ;//L1 'd2 : time_end=10'd1702 ;//L2 'd3 : tim ...
- js实现弹出框跟随鼠标移动
又是新的一天网上冲浪,在bing的搜索页面下看到这样一个效果: 即弹出框随着鼠标的移动而移动.思路大概为: 调用onmousemove函数,将鼠标的当前位置赋予弹出框即可 //html <div ...
- ElementUI table 点击编辑按钮进行编辑实现示例
<!DOCTYPE html> <html > <head> <meta charset="UTF-8"> <meta nam ...
- 1.编译spring源码
本文是作者原创,版权归作者所有.若要转载,请注明出处 下载spring源码,本文用的是版本如下: springframework 5.1.x, IDE工具idea 2019.2.3 JAVA ...
- 2.Python 赋值与内存
定义变量和赋值其实就是系统处理内存的过程和问题,这篇文章分别从申请和释放内存两部分讨论 一.申请内存 python定义一个变量时,会为变量的对象申请一个内存,该变量会存储指向该对象内存中的地址 这 ...
- js知识点面试题
网上看到的一个题,在这里存一下 此为题目function Foo() { getName = function () { alert (1); }; return this; } Foo.getNam ...
- 11G-使用跨平台增量备份减少可移动表空间的停机时间 XTTS (Doc ID 1389592.1)
11G - Reduce Transportable Tablespace Downtime using Cross Platform Incremental Backup (Doc ID 13895 ...
- c++ 的namespace及注意事项
前文 下文中的出现的"当前域"为"当前作用域"的简写 namepsace在c++中是用来避免不同模块下相同名字冲突的一种关键字,本文粗略的介绍了一下namesp ...
- 运行java可执行jar包
导出与导入:如果要用别的项目的类, 把对方类export出成jar包(多个类的集合),然后复制到自己项目路径下然后添加至构建路径,jar包右键buildpath/addtobuildpath.expo ...
- THUWC2019酱油记
Day -1 坐了一上午动车来到帝都,晚上去了趟THU还有奥林匹克公园. 反正也是来打酱油的,颓废怎么能少呢.