《DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks》研读笔记
《DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks》研读笔记
论文标题:DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks
来源:ICCV 2017
摘要:
尽管手机中的嵌入式照相机的性能在快速地发展,但是它们所受到的物理限制——较小的感光器件,精简的镜头和缺少特定的硬件——制约着手机的相机拍出与DSLR(单反)同样质量的照片。在本工作中,我们展示了一个端对端的深度学习的方法来弥补这一差距,该方法可以通过将原始的手机相片转换为高质量的单反相机拍出来的图片。我们提出通过应用残差卷积神经网络来提升图片的颜色呈现和图像的锐度。由于标准的均方误差并不适合用来衡量图像的感知质量,因此我们引入了一个由内容误差、颜色误差与纹理误差合成的感知误差函数。头两个误差通过分析得出,纹理误差则通过一种对抗式的方式学习得到。我们还展示了DPED,一个大规模的包含采自于三个不同的手机和一个高端反光相机图片的数据集。我们定量和定性的评估表明通过所提出的算法增强后的图片的质量和单反相机拍出的照片的质量是相当的,同时结果还表明该方法还可以被应用任何类型的数码相机中。
论文主要内容:
1、引言
尽管最近几年手机相机中使用的精简的感光单元取得了极大的进步,使得手机的拍照效果获得了巨大的提升。然而,目前手机的拍照效果依然不如单反数码相机的效果好。因为单反相机有着更大的感光单元和大口径光学镜头,这使得照片能够有更好的分辨率、颜色呈现效果。鉴于额外的感光器件帮助调整拍摄参数,也有着更低的噪声。这些物理差异为手机相机的拍照质量造成了极大的阻碍,使其难以获得与单反相机同样的拍摄效果。现有的一些图像自动增强的工具一般都关注的是全局参数的调整,例如:对比度和亮度,忽视了纹理的质量与图像的语义。此外,这些工具一般都使用一些预定义(pre-defined)的规则,而并没有考虑到某一设备的特性。因此,图片处理的主要方式人工通过某种图像修整工具来完成。
1.1 相关研究
图像质量增强和如下的几个子领域有关:
(1)图像超像素(super-resolution);
(2)图像去雾(dehazing);
(3)图像去噪(denoising);
(4)图像上色(colorization);
(5)图像调整:曝光调整、风格调整等。
1.2 贡献
(1)提出了一个新的图像增强算法,该算法基于学习手机设备照片与DSLR所拍摄的照片之间的映射函数。目标模型使用一个端对端的训练方式,因此不需要任何额外的监督或者特征工程;
(2)采集了一个大规模的超过6000照片的数据库,这些照片涵盖了很多场景,并且是同时由三个低端手机相机与DSLR相拍摄得到的;
(3)提供了一个由颜色损失、纹理损失及内容损失所组成的损失函数,保证有效的图像质量估计;
(4)进行了客观的、主观实验,显示了被增强的图片对原始图片的优势,同时也展现了其与单反相机间相当的质量。
2、DPED数据库
该数据库通过对同一场景,分别使用四个取相设备来获得。取相设备中包括三个手机相机和一个单反相机。用来采集图像的设备如下图2所示。一些图片样例子如图3所示。


为了保证对每一场景,四个相机能够同时取相,因此将这些设备都方式在一个三角架上面,通过无限控制系统来远程启动这四个设备。这些图像都是通过各个相机的默认设置来获取的。由于各个取相设备之间的位置和观察角度存在着区别,因此所拍出来的图片并没有很好地配准。因此文章作者还提出使用非线性变换来获得固定分辨率地图片。方法大致为:计算每一对相机图片与单反图片之间的匹配SIFT关键点。然后使用使用RANSAC来估计一个homography。最后对两张图片进行裁切,保留重叠的部分,将单反的图片的尺寸变为手机相片的尺寸。在训练CNN的时候使用的是从图片中抽取的100*100的图片块。这些图片块是使用不重叠的滑动窗口来从相机-单反图片对中抽取的。
、方法
3.1 损失函数
)颜色质量;2)纹理质量;3)内容质量。下面逐一介绍衡量这些质量的损失函数。
)颜色损失
使用经过高斯模糊之后的图片之间的欧时距离来衡量被增强后的图片与目标图片之间的颜色损失。

)纹理损失
基于GAN来直接学习一个合适的衡量纹理质量的标准。
)内容损失
使用VGG-19网络中relu 5_4层所产生的特征图之间的差异来表示图片之间的内容差异。

)总变化误差
使用所生成图片在两个方向上的梯度平均值。

)总误差

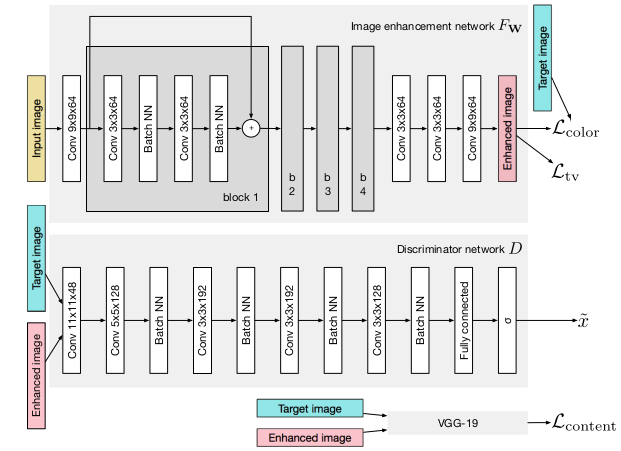
3.2 模型架构
架构如下图,算法代码地址为:http://people.ee.ethz.ch/~ihnatova/index.html。
、实验
通过与一些相关方法和工具之间进行定性与定量的比较来评价算法的效果
4.1 对比方法
比较的方法与工具包括:
Apple Photo Enhancer(APE):自动化图像增强的商业软件;
Dong et. al:超像素方法;
Johnson et. Al:超像素方法;
张图片进行颜色、锐度及总体感觉进行手动调整。
4.2 量化评价
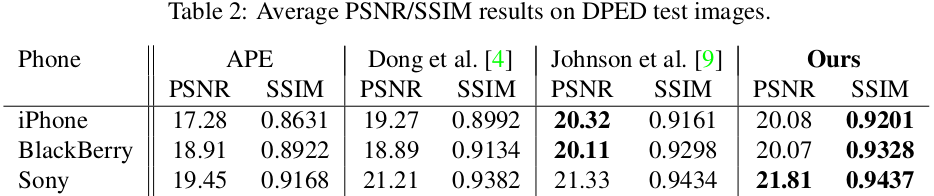
使用PSNR及SSIM作为衡量标准来量化比较APE、Dong et. al及Johnson et. al及文章中所提出算法的表现。计算应用上述四种方法处理后的图片与由单反拍摄的图片之间的PSNR与SSIM。数据如下表所示。
4.3 用户研究
由于本文的目标是将手机拍摄的照片转化为单反的质量。为了衡量总体的质量,我们设计了一个无参照的用户研究。在用户研究中,被试人被要求从所展示的图片中选择看起来最好的一张图片。主要进行的比较实验包括:
)原始底端相机拍摄的图片、单反相机拍摄的图片与由所提出的方法增强过的图片。
个场景的图片个底端相机,因此本次实验一共要进行81次询问。
)只使用iPhone所拍摄的图片,分别与由专家修饰过的图片、由APE自动调整过的图片和由本文所提出方法转换过的图片进行比较。上述两个实验的结果如下:

图中前三个子图表示的是第一个比较试验的结果。第四表示的是第二个比较试验的结果。每一个柱子都代表着实验中某一种图像被选择的比例。
《DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks》研读笔记的更多相关文章
- Very Deep Convolutional Networks for Large-Scale Image Recognition
Very Deep Convolutional Networks for Large-Scale Image Recognition 转载请注明:http://blog.csdn.net/stdcou ...
- 目标检测--Spatial pyramid pooling in deep convolutional networks for visual recognition(PAMI, 2015)
Spatial pyramid pooling in deep convolutional networks for visual recognition 作者: Kaiming He, Xiangy ...
- VGGNet论文翻译-Very Deep Convolutional Networks for Large-Scale Image Recognition
Very Deep Convolutional Networks for Large-Scale Image Recognition Karen Simonyan[‡] & Andrew Zi ...
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition Kaiming He, Xiangyu Zh ...
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
http://www.dengfanxin.cn/?p=403 原文地址 我对物体检测的一篇重要著作SPPNet的论文的主要部分进行了翻译工作.SPPNet的初衷非常明晰,就是希望网络对输入的尺寸更加 ...
- 2014-VGG-《Very deep convolutional networks for large-scale image recognition》翻译
2014-VGG-<Very deep convolutional networks for large-scale image recognition>翻译 原文:http://xues ...
- 深度学习论文翻译解析(九):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
论文标题:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 标题翻译:用于视觉识别的深度卷积神 ...
- 论文笔记:(2019CVPR)PointConv: Deep Convolutional Networks on 3D Point Clouds
目录 摘要 一.前言 1.1直接获取3D数据的传感器 1.2为什么用3D数据 1.3目前遇到的困难 1.4现有的解决方法及存在的问题 二.本文idea 2.1 idea来源 2.2 初始思路 2.3 ...
- [CVPR 2016] Weakly Supervised Deep Detection Networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 } p. ...
随机推荐
- RTP Payload Format for H264 Video
基础传输结构 rtp中对于h264数据的存储分为两层,分别是 VCL: video coding layer 视频编码层 这是h264中block, macro block 以及 slice级别的定义 ...
- tomcat在centos7能启动不显示
首先查看启动日志,日志显示成功启动,java路径也对,没有问题. 日志目录路径为$(tomcat)/logs/catalina.log 查看命令为:tail -300f catalina.log 然后 ...
- poi创建excel文件
package com.mozq.sb.file01.test; import org.apache.poi.hssf.usermodel.*; import org.apache.poi.hssf. ...
- windows下cocos2d-x工程结构讲解
这是我们新建好的工程,稍微解释一下我们开发windows的cocos应用所用到的几个文件夹的作用 Classes文件夹,存放游戏代码中的类的源码,当然我们放在别的地方也可以,只要配置好依赖关系就行了 ...
- ORM和Mybatis
ORM框架 概述 在学习MyBatis之前,先来看看什么是ORM框架. ORM全称Object/Relation Mapping,对象/关系数据库映射,功能为完成对象的编程语言到关系数据库的映射,可以 ...
- SSH框架之Hibernate第一篇
1.2Hibernate的概述: 1.2.1 什么Hibernate? Hibernate(开发源代码的对象关系映射框架)是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它 ...
- PDF转换成DXF文件?PDF转DXF的操作方法
在CAD工作中,经常就需要将绘制完成的图纸文件的格式进行转换,那怎么将PDF文件转换成DXF格式的呢?具体要怎么来进行操作呢?本编教程小编就来教教大家具体操作方法,具体操作如下: 一.工具转换 推荐指 ...
- JS基础语法---Date对象中常见的方法
创建实例对象 var dt = new Date(); //当前的时间---当前的服务器 console.log(dt); var dt = new Date("2017-08-12&quo ...
- How to Check Device UUID or File System UUID. (Doc ID 1505398.1)
How to Check Device UUID or File System UUID. (Doc ID 1505398.1) APPLIES TO: Linux OS - Version Orac ...
- 打包Python文件为exe
pip install pyinstaller 然后就在终端里执行命令 cd 到目标文件的目录下 执行 pyinstaller -F ***.py 即可生成exe