Spark 中的机器学习库及示例
MLlib 是 Spark 的机器学习库,旨在简化机器学习的工程实践工作,并方便扩展到更大规模。MLlib 由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道 API。具体来说,主要包括以下几方面的内容:
- 机器学习算法:常用的学习算法,如分类、回归、聚类和协同过滤;
- 特征化工具:特征提取、转化、降维和特征选择等工具;
- 管道:由于构建、评估和调整机器学习管道的工具;
- 持久性:保存和加载算法,模型和管道;
- 实用工具:线性代数,统计和数据处理等工具。
DataFrame-based API
从 Spark 2.0 开始,RDD-based API 已经进入维护模式,不再增加新的功能,并期望在 Spark 3.0 中移除。而 DataFrame-based API 成为 Spark 中的机器学习的主要 API。主要原因有以下几点:
DataFrames 提供比 RDDs 更加用户友好的 API,好处包括支持多种 Spark 数据源,SQL/DataFrame 查询,Tungsten 和 Catalyst 优化以及跨语言的统一 API;
DataFrame-based API 为 MLlib 提供了统一的跨多种 ML 算法和多种语言的 API;
DataFrames 有助于实用的 ML 管道,特别是功能转换。
使用 ML Pipeline API 可以很方便的把数据处理,特征转换,正则化,以及多个机器学习算法联合起来,构建一个单一完整的机器学习流水线。这种方式给我们提供了更灵活的方法,更符合机器学习过程的特点,也更容易从其他语言迁移。
机器学习工具
示例(逻辑回归)
逻辑回归是预测分类结果的常用方法。广义线性模型的一个特例是预测结果的概率。在 spark.ml 中,逻辑回归可以用 binomial logistic regression 来预测二元结果,或者使用 multinomial logistic regression 来预测多类结果。使用 family 参数在这两个算法之间进行选择,或者保持不设置,Spark 将推断出正确的变量。
from pyspark.ml.classification import LogisticRegression
# Load training data
training = spark.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt")
lr = LogisticRegression(maxIter=10, regParam=0.3, elasticNetParam=0.8)
# Fit the model
lrModel = lr.fit(training)
# Print the coefficients and intercept for logistic regression
print("Coefficients:" + str(lrModel.coefficients))
print("Intercept:" + str(lrModel.intercept))
# We can also use the multinomial family for binary classification
mlr = LogisticRegression(maxIter=10, regParam=0.3, elasticNetParam=0.8, family="multinomial")
# Fit the model
mlrModel = mlr.fit(training)
# Print the coefficients and intercepts for logistic regression with multinomial family
print("Multinomial coefficients:" + str(mlrModel.coefficientMatrix))
print("Multinomial intercepts:" + str(mlrModel.interceptVector))
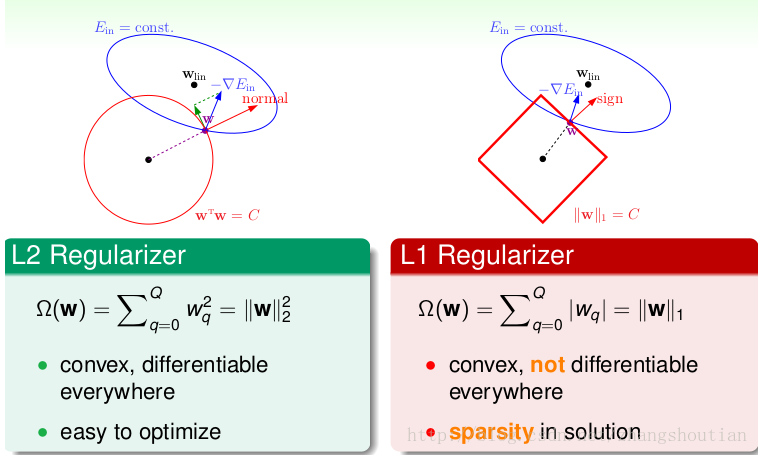
其中,libsvm 为一种数据格式,具体形式可以参考:libsvm。regParam 定义了正则化项的权重参数,elasticNetParam 表示选择的正则化项。假设定义的正则化项如下:
\]
则 regParam 参数正是对应了参数 \(\lambda\),而 elasticNetParam 则是对应了参数 \(\alpha\),则有如下情况:
- 当 \(\alpha=0\) 时,惩罚项为 L2 正则,默认情况;
- 当 \(\alpha=1\) 时,惩罚项为 L1 正则;
- 当 \(0<\alpha<1\) 时,惩罚项为 L1 正则和 L2 正则的混合;
L1 和 L2 正则的主要目的是解决模型的过拟合问题,具体的形式为:
Spark 中的机器学习库及示例的更多相关文章
- Spark中ml和mllib的区别
转载自:https://vimsky.com/article/3403.html Spark中ml和mllib的主要区别和联系如下: ml和mllib都是Spark中的机器学习库,目前常用的机器学习功 ...
- Spark MLBase分布式机器学习系统入门:以MLlib实现Kmeans聚类算法
1.什么是MLBaseMLBase是Spark生态圈的一部分,专注于机器学习,包含三个组件:MLlib.MLI.ML Optimizer. ML Optimizer: This layer aims ...
- 掌握Spark机器学习库-05-spark中矩阵与向量的使用
1)介绍 矩阵: Matrix,看做二维表,基本运算(+,-,*,T) 向量: Vectors,方向和大小,基本运算,范数 2)spark中向量的使用(主要使用breeze.linalg) 3)spa ...
- 《Spark 官方文档》机器学习库(MLlib)指南
spark-2.0.2 机器学习库(MLlib)指南 MLlib是Spark的机器学习(ML)库.旨在简化机器学习的工程实践工作,并方便扩展到更大规模.MLlib由一些通用的学习算法和工具组成,包括分 ...
- Spark入门实战系列--8.Spark MLlib(下)--机器学习库SparkMLlib实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .MLlib实例 1.1 聚类实例 1.1.1 算法说明 聚类(Cluster analys ...
- Spark MLlib(下)--机器学习库SparkMLlib实战
1.MLlib实例 1.1 聚类实例 1.1.1 算法说明 聚类(Cluster analysis)有时也被翻译为簇类,其核心任务是:将一组目标object划分为若干个簇,每个簇之间的object尽可 ...
- 掌握Spark机器学习库(课程目录)
第1章 初识机器学习 在本章中将带领大家概要了解什么是机器学习.机器学习在当前有哪些典型应用.机器学习的核心思想.常用的框架有哪些,该如何进行选型等相关问题. 1-1 导学 1-2 机器学习概述 1- ...
- Python中使用第三方库xlrd来写入Excel文件示例
Python中使用第三方库xlrd来写入Excel文件示例 这一篇文章就来介绍下,如何来写Excel,写Excel我们需要使用第三方库xlwt,和xlrd一样,xlrd表示read xls,xlwt表 ...
- Spark中分布式使用HanLP(1.7.0)分词示例
HanLP分词,如README中所说,如果没有特殊需求,可以通过maven配置,如果要添加自定义词典,需要下载“依赖jar包和用户字典". 分享某大神的示例经验: 是直接"java ...
随机推荐
- delphi 获取大于2G的物理内存大小
一般情况下,我们是用GlobalMemoryStatus 来获取物理内存大小的 但该API在物理内存大小超过2G的时候,返回值均为2GB.因此,没有办法获取真实的物理内存大小,所以需要对此进行改进. ...
- Android零基础入门第61节:滚动视图ScrollView
原文:Android零基础入门第61节:滚动视图ScrollView 前面几期学习了ProgressBar系列组件.ViewAnimator系列组件.Picker系列组件和时间日期系列组件,接下来几期 ...
- 深度网络中的Tricks
数据增强(Data augmentation) 预处理(Pre-processing) 初始化(Initializations) 训练中的Tricks 激活函数(Activation function ...
- HDFS的几点改进
HDFS(Hadoop Distributed File System)是一个运行在商用机器上面的分布式文件系统,其设计思想来自于google著名的Google File System论文. HDFS ...
- 为什么需要使用Git客户端?(使用msysgit)
Git 是 Linux Torvalds 为了帮助管理 Linux® 内核开发而开发的一个开放源码的版本控制软件.正如所提供的文档中说的一样,“Git 是一个快速.可扩展的分布式版本控制系统,它具有极 ...
- 为什么有如此多的C++测试框架 - from Google Testing Blog
Why Are There So Many C++ Testing Frameworks? by Zhanyong Wan (Software Engineer) 最近貌似有很多人正在开发他们自己的C ...
- OSGEarth环境搭建
1.下载OsgEaarth2.8源码 https://codeload.github.com/gwaldron/osgearth/legacy.zip/osgearth-2.8 2.下载perl 编译 ...
- 5个现在就该使用的数组Array方法: indexOf/filter/forEach/map/reduce详解(转)
ECMAScript5标准发布于2009年12月3日,它带来了一些新的,改善现有的Array数组操作的方法.然而,这些新奇的数组方法并没有真正流行起来的,因为当时市场上缺乏支持ES5的浏览器. ...
- Laravel --- Laravel 5.3 队列使用方法
一.设置存储方式 在config/queue.php中查看队列驱动,在.env 设置[QUEUE_DRIVER] 主要介绍数据库驱动 二.数据库驱动 1.修改.env CACHE_DRIVER=fil ...
- Java虚拟机详解(一)------简介
本系列博客我们将以当前默认的主流虚拟机HotSpot 为例,详细介绍 Java虚拟机.以 JDK1.7 为主,同时介绍与 JDK1.8 的不同之处,通过Oracle官网以及各种文献进行整理,并加以验证 ...