DAX 第六篇:统计函数
统计函数用于创建聚合,对数据进行统计分析。在使用统计函数时,必须考虑到数据模型,表之间关系,数据重复等因素,一般都会搭配过滤函数实现数据的提取和分析。
统计量一般是:均值、求和、计数、最大值、最小值、求中位数、求分位数、方差和标准差等。
一,求均值
均值分为几何均值和算术均值,几何平均数是n个变量值连乘积的n次方根:
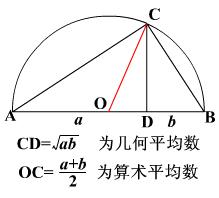
常用下面两个函数计算列值的算术平均值,AVERAGE函数用于对表中的数值型的列计算均值,并且只能用于基础表,参数的格式是table[decimal_column]:
AVERAGE(<column>)
AVERAGEX(<table>,<expression>)
而AVERAGEX函数功能更为强大,参数table可以是基础表,也可以是返回表值的函数;参数 expression 是关于列的表达式,函数计算表达式的均值:
=AVERAGEX(InternetSales, InternetSales[Freight]+ InternetSales[TaxAmt])
对于几何均值,有下面两个函数来计算:
GEOMEAN(<column>)
GEOMEANX(<table>, <expression>)
二,求和
通过以下两个函数来计算加和,SUM函数只能用于数值型的列,并且只能用于基础表,参数的格式是table[decimal_column]:
SUM(<column>)
SUMX(<table>, <expression>)
SUMX函数从表中计算每一个行的加和,参数table可以是基础表,也可以是返回表值的函数;参数 expression 是关于列的表达式,只有数值会被加和,忽略空值,date,逻辑值或文本值:
示例,第一个参数是过滤器返回的表值,计算[Freight]的加和:
=SUMX(FILTER(InternetSales, InternetSales[SalesTerritoryID]=5),[Freight])
可以把SUMX函数,转换为CALCULATE函数:
=CALCULATE( SUM(InternetSales[Freight]), FILTER(InternetSales, InternetSales[SalesTerritoryID]=5))
三,计数
常用的计数函数有8个,函数的语法如下:
COUNT(<column>)
COUNTA(<column>)
DISTINCTCOUNT(<column>)
DISTINCTCOUNTNOBLANK (<column>)
COUNTBLANK(<column>)
COUNTROWS(<table>)
COUNTX(<table>,<expression>)
COUNTAX(<table>,<expression>)
这8个函数都用于计数,根据函数的名称,大致分为5类:
- 函数名称中的 A 是指适用于Any 数据类型,不带A的函数只能用于数值、日期和字符串,不支持逻辑类型;不统计Blank值;
- 函数名称带后缀X的函数适用于基础表和返回表值的表达式,不带X的函数只能用于基础表;不统计Blank值;
- 统计Blank值
- 统计总行数
- 唯一值计数
下面的6个函数用于基础表,根据列值和列的类型进行计数:
- COUNT :统计列值不为Blank的行的数量,列值的类型可以是:数值、日期和字符串,不支持逻辑类型,Blank值会被忽略。
- COUNTA :统计列值不为Blank的行的数量,列值的类型可以是:数值、日期、字符串和逻辑类型,Blank值会被忽略。
- COUNTBLANK :统计列值是Blank的行的数量,列值的类型可以是任意类型,该函数只统计包含Blank值的行的数量。
- COUNTROWS :统计表的总行数
- DISTINCTCOUNT :统计列值不重复的数量,列值的类型可以是任意类型,包含BLANK,在该函数中BLANK的值是相同的。
- DISTINCTCOUNTNOBLANK :统计列值不为Blank,且不重复的数量,列值的类型可以是任意类型
下面的2个函数用于基础表,或返回表的表达式中:
- COUNTX :统计列值不为Blank的行的数量,列值的类型可以是:数值、日期和字符串,不支持逻辑类型,Blank值会被忽略。
- COUNTAX :统计列值不为Empty(Blank)的行的数量,列值的类型可以是:数值、日期、字符串和逻辑类型,Blank值会被忽略。
注意:在COUNTAX函数中,如果列中包含表达式,而表达式的结果是空值,在这种情况下,COUNTAX函数把包含公式的列值作为非空(nonblank)看待,计数值会增加。如果COUNTAX函数的列中不包含表达式,当列值为Blank时,COUNTAX函数会忽略Blank值,计数值不会增加。
四,求最大值和最小值
通过以下6个函数来计算列值的最大值和最小值,在进行比较时,Blank(或Empty Cell)会被忽略掉。
MAX(<column>)
MAXA(<column>)
MAXX(<table>,<expression>)
MIN(<column>)
MINA(<column>)
MINX(<table>, < expression>)
1,列值比较
根据函数中是否带后缀A,把函数分为两类:
- 带后缀A的统称为最值 - A函数,有MAXA和MINA共2个;
- 不带后缀A的统称为常规最值函数,有MAX、MAXX、MIN和MINX 共4个。
这两类函数在功能上有微小的区别:
- 常规最值函数:不支持逻辑值的比较,但是支持数值、日期和文本的比较,忽略Blank;如果所有的列值都是Blank/Empty,导致列中没有可用的值,那么常规最值函数最终返回Blank。
- 最值 - A函数:不支持文本的比较,但是支持数值、日期和逻辑值的比较,忽略Blank;如果所有的列值都是Blank/Empty,导致列中没有可用的值,那么最值 - A函数最终返回0。
注意:在比较逻辑值时,TRUE被视为1,FALSE被视为0。
2,比较两个值
在比较两个值时,如果参数为Blank,那么Blank被视为0:
MIN(<expression1>, <expression2>)
MAX(<expression1>, <expression2>)
五,中位数
中位数和分位数都是针对数值型进行统计的,Blank、日期、逻辑值和文本会被忽略。
MEDIAN(<column>)
MEDIANX(<table>, <expression>)
六,分位数
k表示期望的百分位值,其中INC是指inclusive(包含),EXC是指exclusive(不包含)。后缀带EXC的函数,参数k的取值范围是0-1,不包含0和1;后缀带INC的函数,参数k的取值范围是0-1,包含0和1。
PERCENTILE.EXC(<column>, <k>)
PERCENTILE.INC(<column>, <k>)
PERCENTILEX.EXC(<table>, <expression>, k)
PERCENTILEX.INC(<table>, <expression>, k)
当指定百分位数的值介于数组中的两个值之间时,这4个函数都会进行插值。 如果无法插入指定的k百分位数,则返回错误。
- 对于 INC函数,如果k不是1 /(n - 1)的倍数,则这4个函数将进行插值以确定第k个百分位数的值。
- 对于 EXC函数,如果k不是1 /(n + 1)的倍数,则这4个函数将进行插值以确定第k个百分位数的值。
PERCENTILE.INC
计算原理是:对于数组中的每个值,都会按照从小到大的顺序给定一个百分位(基于n-1),假如数组有n个数值,这n个百分位分别是:0/(n-1)、1/(n-1)、2/(n-1)……n-1/(n-1),当k值与这些百分位相同时,即k是1/(n-1)的倍数,直接返回数组中对应的数值,如果k不是 1/(n-1) 的倍数,则 PERCENTILE.INC 使用插值法来确定第k个百分点的值。
PERCENTILE.EXC
计算原理是:对于数组中的每个值,都会按照从小到大的顺序给定一个百分位(基于n+1),假如数组有n个数值,这n个百分位分别是:1/(n+1)、2/(n+1)、3/(n+1)……n/(n+1),当k值与这些百分位相同时,即k是1/(n+1)的倍数,直接返回数组中对应的数值,如果k不是 1/(n+1) 的倍数,则 PERCENTILE.EXC 使用插值法来确定第k个百分点的值。
引用简书上《 分位数计算,分析Excel中函数实现原理》的一个例子,作者是过桥0811 :
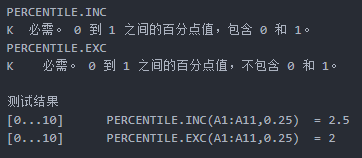

Python代码实现:
import math
def percentile_inc(array,k):
if len(array) == 0:
return "数组不能为空"
if k > 1 or k < 0:
return "系数需为 0 到 1 之间的百分点值,包含 0 和 1"
array_sort = sorted(array)
address = (len(array_sort) - 1) * k + 1
if address == len(array_sort):
return array_sort[len(array_sort) - 1]
i = int(math.modf(address)[1]) #取出整数部分
j = math.modf(address)[0] #取出小数部分
value = array_sort[i-1] + (array_sort[i] - array_sort[i-1]) * j
#print("数组为:" + str(array), "系数为:" + str(k),"百分位数为:" + str(value))
return value
def percentile_exc(array,k):
if len(array) == 0:
return "数组不能为空"
if k >= 1 or k <= 0:
return "系数需为 0 到 1 之间的百分点值,不包含 0 和 1 "
array_sort = sorted(array)
address = (len(array_sort) + 1) * k
if address < 1:
return "因系数过小,不能通过插入值来确定指定的百分点的值"
i = int(math.modf(address)[1]) #取出整数部分
j = math.modf(address)[0] #取出小数部分
value = array_sort[i-1] + (array_sort[i] - array_sort[i-1]) * j
#print("数组为:" + str(array), "系数为:" + str(k),"百分位数为:" + str(value))
return value
print(percentile_inc([10,9,8,7,6,5,4,3,2,1,0],0))
print(percentile_inc([10,9,8,7,6,5,4,3,2,1,0],0.01))
print(percentile_inc([10,9,8,7,6,5,4,3,2,1,0],0.25))
print(percentile_inc([10,9,8,7,6,5,4,3,2,1,0],1))
print(percentile_inc([1,3,2,4],0.3)) # 官网测试数据
print(percentile_exc([10,9,8,7,6,5,4,3,2,1,0],0))
print(percentile_exc([10,9,8,7,6,5,4,3,2,1,0],0.01))
print(percentile_exc([10,9,8,7,6,5,4,3,2,1,0],0.09))
print(percentile_exc([10,9,8,7,6,5,4,3,2,1,0],0.25))
print(percentile_exc([1,2,3,6,6,6,7,8,9],0.25)) # 官网测试数据
七,求方差和标准方差
标准差是方差的算术平方根,反映一个数据集的离散程度。DAX通过以下8个函数计算方差和标准方差,这些函数只适用于数值型列,并且会忽略Blank值:
VAR.S(<columnName>)
VAR.P(<columnName>)
VARX.S(<table>, <expression>)
VARX.P(<table>, <expression>)STDEV.S(<ColumnName>)
STDEV.P(<ColumnName>)
STDEVX.S(<table>, <expression>)
STDEVX.P(<table>, <expression>)
根据函数后缀的不同,可以把函数分为两类:后缀为P表示返回整个总体的方差或标准差,后缀为S表示返回样本总体的方差或标准差。
对于方差来说,整个总体和样本总体的计算公式是不同的:
- 整个总体的方差计算公式是:∑(x - x̃)²/n
- 样本总体的方差计算公式是:∑(x - x̃)²/(n-1)
注释: x̃ 是 数据的均值,n是数据的数量
参考文档:
DAX 第六篇:统计函数的更多相关文章
- 解剖SQLSERVER 第十六篇 OrcaMDF RawDatabase --MDF文件的瑞士军刀(译)
解剖SQLSERVER 第十六篇 OrcaMDF RawDatabase --MDF文件的瑞士军刀(译) http://improve.dk/orcamdf-rawdatabase-a-swiss-a ...
- 解剖SQLSERVER 第六篇 对OrcaMDF的系统测试里避免regressions(译)
解剖SQLSERVER 第六篇 对OrcaMDF的系统测试里避免regressions (译) http://improve.dk/avoiding-regressions-in-orcamdf-b ...
- Python之路【第十六篇】:Django【基础篇】
Python之路[第十六篇]:Django[基础篇] Python的WEB框架有Django.Tornado.Flask 等多种,Django相较与其他WEB框架其优势为:大而全,框架本身集成了O ...
- 第六篇 :微信公众平台开发实战Java版之如何自定义微信公众号菜单
我们来了解一下 自定义菜单创建接口: http请求方式:POST(请使用https协议) https://api.weixin.qq.com/cgi-bin/menu/create?access_to ...
- RabbitMQ学习总结 第六篇:Topic类型的exchange
目录 RabbitMQ学习总结 第一篇:理论篇 RabbitMQ学习总结 第二篇:快速入门HelloWorld RabbitMQ学习总结 第三篇:工作队列Work Queue RabbitMQ学习总结 ...
- 第六篇 Replication:合并复制-发布
本篇文章是SQL Server Replication系列的第六篇,详细内容请参考原文. 合并复制,类似于事务复制,包括一个发布服务器,一个分发服务器和一个或多个订阅服务器.每一个发布服务器上可以定义 ...
- 第六篇 Integration Services:初级工作流管理
本篇文章是Integration Services系列的第六篇,详细内容请参考原文. 简介在前几篇文章中,我们关注使用增量加载方式加载数据.在本篇文章,我们将关注使用优先约束管理SSIS控制流中的工作 ...
- 第六篇 SQL Server安全执行上下文和代码签名
本篇文章是SQL Server安全系列的第六篇,详细内容请参考原文. SQL Server决定主体是否有必要的执行代码权限的根本途径是其执行上下文规则.这一切都可能复杂一个主体有执行代码的权限,但是却 ...
- 第六篇 SQL Server代理深入作业步骤工作流
本篇文章是SQL Server代理系列的第六篇,详细内容请参考原文. 正如这一系列的前几篇所述,SQL Server代理作业是由一系列的作业步骤组成,每个步骤由一个独立的类型去执行.每个作业步骤在技术 ...
随机推荐
- WebBrowser中获得脚本中的变量值
//项目中添加Micrsoft.mshtml引用 --c:/temp/temp.htm-- <html> <script language="JavaScript" ...
- Oracle 裁掉北京研发团队,相应职位撤回美国(收购了NetSuite,LogFire,Dyn)
根据中国日报报道,2017年1月14日上午9点09分,甲骨文北京研发团队的同事收到了来自BU老大的一封邮件.邮件上提及,由于市场变化,甲骨文开始整合各研发中心资源公司在云计算方向发力,文末单独提出了甲 ...
- Android和IOS启动第三方地图APP
最近客户新提了需求,地址字段要能通过第三方的地图进行定位,于是对Android和IOS端进行了调整. 以下是调用地图部分的代码. android可按照包名来判断app是否存在: 方法: /* * ch ...
- Qt之界面数据存储与获取(userData)
http://blog.csdn.net/u011012932/article/details/52413012#comments
- Delphi各种从文件里读取内容的方法
Hi I am having a problem running a function to read a text file the problem seems to be that my anti ...
- C#基础原理拾遗——引用类型的值传递和引用传递
以前写博客不深动,只搭个架子,像做笔记,没有自己的思考,也没什么人来看.这个毛病得改,就从这一篇开始- 最近准备面试,深感基础之重要,奈何我不是计算机科班出身,基础方面有些捉襟见肘.短期怎么补?做面实 ...
- 如何在 cmd 命令行中查看、修改、删除与添加环境变量
Windows 和 linux 区别 一.查看所有环境变量的名称和值:Linux下:exportWindows下:set二.根据名称查该环境变量的值:Linux下:echo $环境变量名比如:echo ...
- Adobe cs6 全系列软件绿色破解版-一键安装
下载地址: 链接:https://pan.baidu.com/s/1THssmSS-SnyNc2DW7Wr8cA 提取码:y3tq 软件介绍 作为全球领先的多媒体设计软件供应商,Adobe Syste ...
- 本地线程-ThreadLocal
线程本地存储是一个自动化机制,可以为使用相同变量的每个不同的线程都创建不同的存储.简单来说,就是对于某个变量,针对不同的线程存储不同的值. 实例: import java.util.Random; i ...
- isinstance()函数判断数据类型
判断是否是字符串 a = b = " print(isinstance(a,str)) print(isinstance(b,str)) False True 判断是否是列表 a = [,, ...