SQL Server SQL性能优化之--数据库在“简单”参数化模式下,自动参数化SQL带来的问题
数据库参数化的模式
数据库的参数化有两种方式,简单(simple)和强制(forced),默认的参数化默认是“简单”,
简单模式下,如果每次发过来的SQL,除非完全一样,否则就重编译它(特殊情况会自动参数化,正是本文想说的重点)
强制模式就是将adhoc SQL强制参数化,避免每次运行的时候因为参数值的不同而重编译,这里不详细说明。
这首先要感谢“潇湘隐者”大神的提示,
当时也是遇到一个实际问题,
发现执行计划对数据行的预估,怎么都不对,有观察到无论怎么改变参数,SQL语句执行前都没有重编译,疑惑了好一会,
这个问题正是简单参数化模式下,对某些SQL自动参数化造成执行计划重用引起的,也是本文想表达的重点。
这个问题之前就写过,当时也只是看书上理论上这么说的,没有想到其带来的影响
该参数是一个数据级别的选项,设置情况可以参考下图
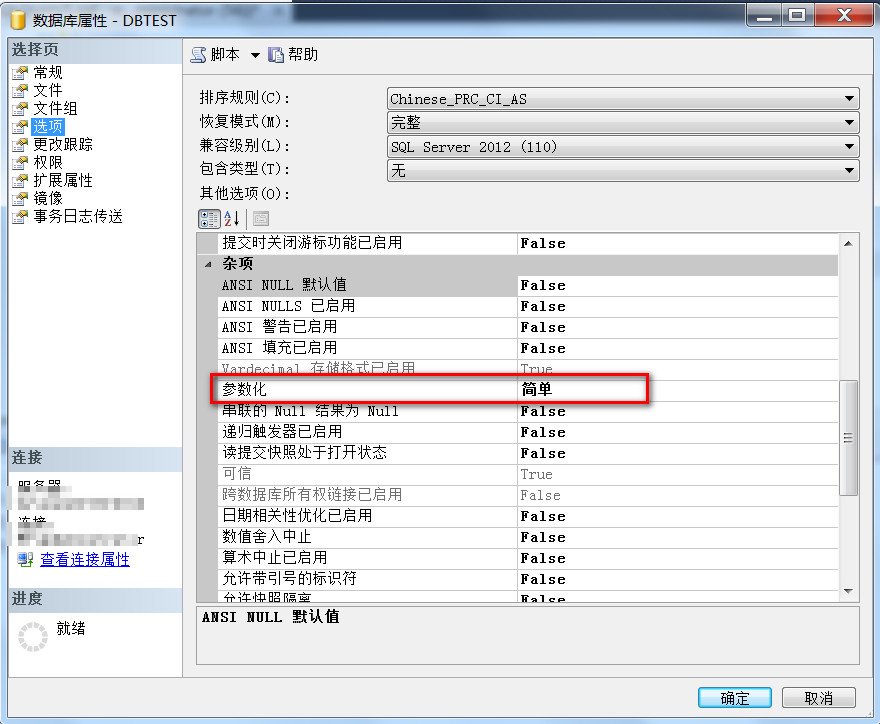
什么情况下会自动参数化
简单参数化模式下,对于有且只有一种执行方式的Adhoc SQL语句,SQL Server会自动参数化它,从而达到重用执行计划的目的。
究竟哪些类型的SQL会被自动参数化,后面会举例说明。
自动参数化会存在哪些问题
在简单模式下,SQL对于某些SQL会自动参数化他,避免每次都重编译。
SQL Server 自动参数化SQL语句的行为,能够避免一些重编译,原本也是出于“好意”,但是这种“好意”往往不一定总是给我们带来好处。
举例说明什么情况下会自动参数化
先造一个简单的测试环境
create table TestAuotParameter
(
id int not null,
col2 )
)
GO
begin
insert into TestAuotParameter values (@i, NEWID())
end
GO
create unique index idx_id on TestAuotParameter(id)
GO
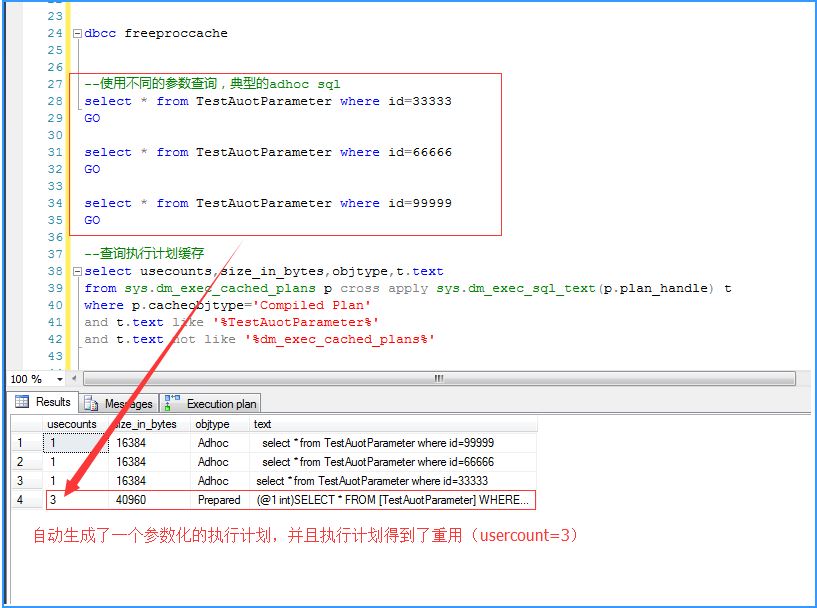
之所以自动参数化了SQL语句,就是因为select * from TestAuotParameter where id=33333 (66666,99999)这句SQL语句,
在当前的数据量下和唯一索引的特点,决定了有且只有一种高效的执行方式(也就是索引查找)
这里说有且只有一种方式是表中数据量相对较多,又因为idx_id这个索引是unique的。如果不是unique的,那么情况就不同了
下面来解释什么是有且只有一种高效的执行计划
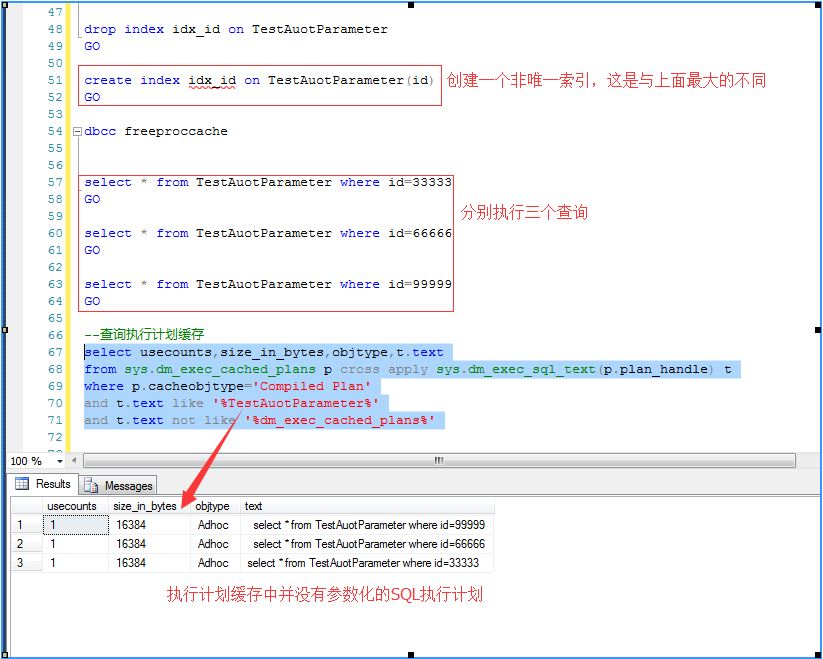
如下截图:同样的测试,我删除id上的唯一索引,创建为非唯一索引,再做同样的测试,就会发现执行同样的SQL并没有被自动参数化
这里解释一下原因,索引类型怎么跟执行计划缓存扯上了?
对于非唯一索引,有可能作做引查找是高效的,有可能做全表扫描是高效的(比如某个ID的数据分布的特别多)
此时执行计划有可能是多样的,不仅仅只有一种方式,所以就不会自动参数化SQL
自动参数化存在的问题
自动参数化好处并不用多说,因为可以重用缓存的执行计划,避免了每次参数值不一样就重编译的问题
说到执行计划重用,不得不说的一个话题就是parameter sniff,嘴皮子都磨破的问题了
没错,自动参数化因为不同参数会重用第一次编译生成的执行计划,很有可能造成parameter sniff问题,以及parameter sniff衍生出来的其他问题
同样用一个例子来做演示,该问题是最近在观察执行计划统计信息(statistics)预估问题时遇到的一个问题,让我困惑了好一会,
这里再次感谢潇湘隐者。
该问题同样也是因为自动参数化了SQL语句,造成执行计划重用,从而造成一个极其简单的SQL执行效率在某些情况下较低的情况,
为什么自动化参数的原因跟上述类似,都是有且只有一种执行方式(索引查找)的情况下,不同参数执行计划重用造成对数据行的错误预估。
测试之前清空一下缓存执行计划,观察不同查询条件下的实际执行计划对数据行的预估
如下查询条件:
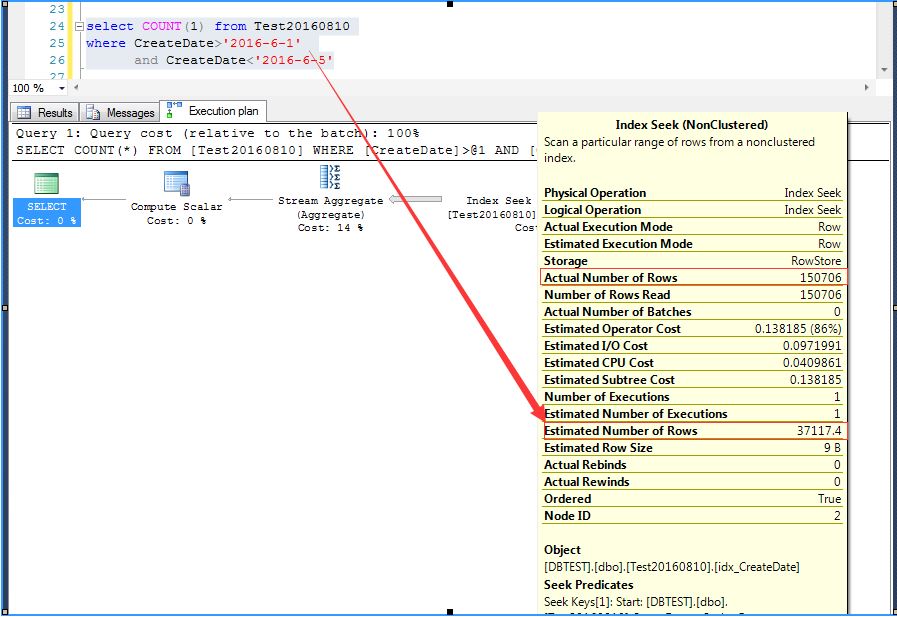
1,初始查询条件为:CreateDate>'2016-6-1' and CreateDate<'2016-6-2',观察执行计划,实际行数是37903,预估行数为37117,预估还算准确
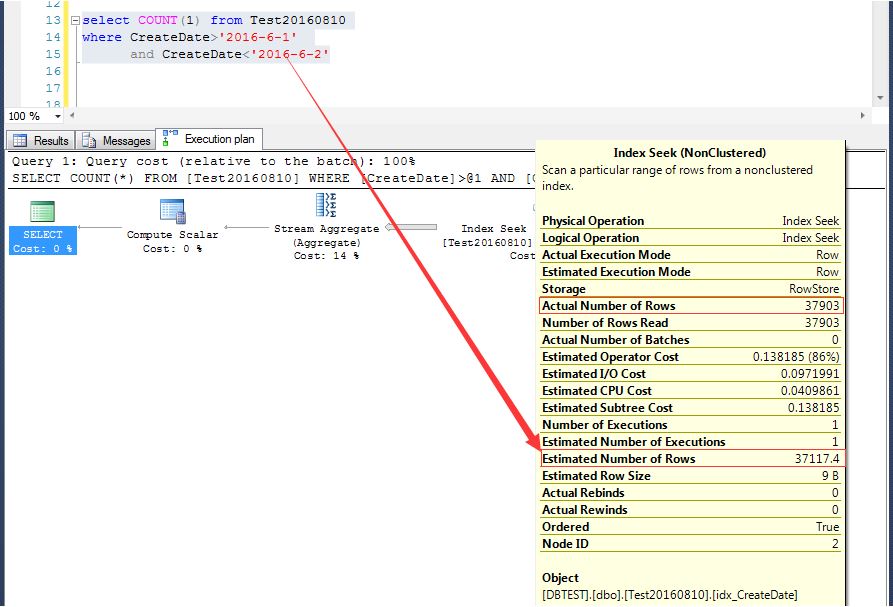
2,将查询条件更新为:CreateDate>'2016-6-1' and CreateDate<'2016-6-5',观察执行计划,实际行数为150706,预估行数不变,还是37117
3,将查询条件更新为:CreateDate>'2016-6-1' and CreateDate<'2016-6-9',观察执行计划,实际行数为302114,预估行数不变,还是37117
,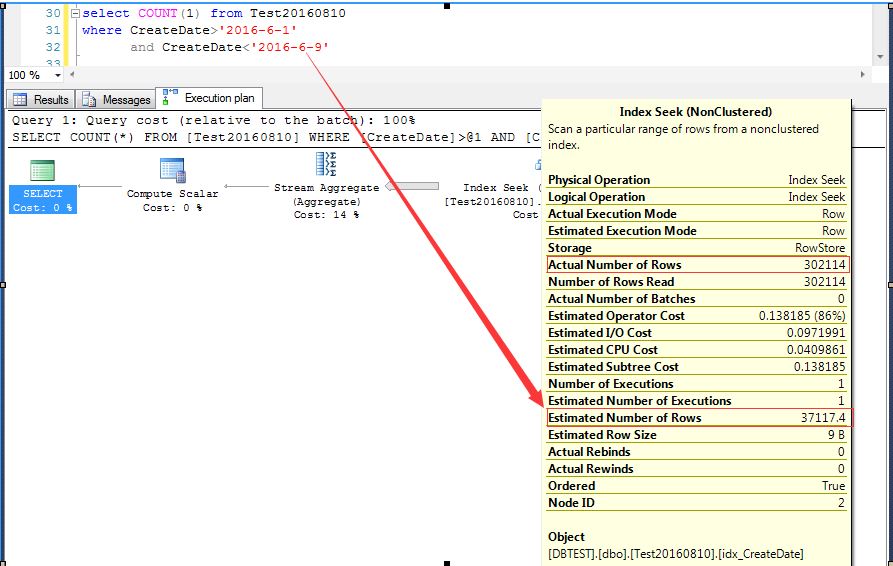
发现没有,因为查询时间段有变化,实际行数也有变化,但是不管实际行数多少,预估行数总是为第一次执行预估的行数。
这肯定不对吧?随便带入什么条件,预估行数都是37117,当时一下子蒙了,怎么每次执行SQL对数据行的预估都是一样的?
其实这个问题跟一开始举例的一样,都是SQL语句被自动参数化了,因此造成了执行计划重用,
执行计划重用,导致错误地预估实际查询的数据行数。
如何解决自动参数化造成错误地重用执行计划的问题
很多问题找到了真正的原因,解决起来往往并不难,这个问题的原因是执行计划重用造成的,那么我们只需要解决执行计划重用的问题即可
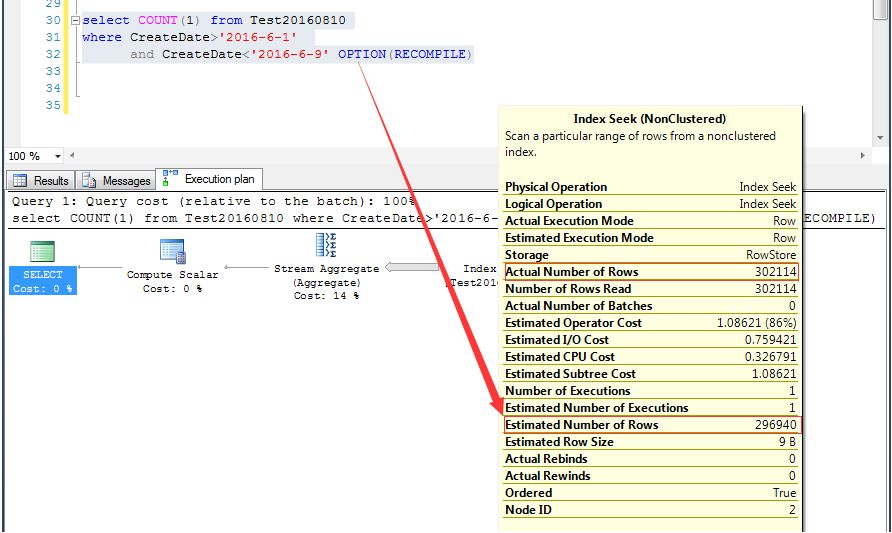
也就是不让他重用执行计划,只需要在SQL语句中加一个提示即可,
也即:select COUNT(1) from Test20160810 where CreateDate>'2016-6-1' and CreateDate<'2016-6-9' OPTION(RECOMPILE)
原因就在于加上OPTION(RECOMPILE)这个查询提示之后,不缓存SQL的执行计划缓存,没有了执行计划缓存,也就没得重用了
比如这个查询,在查询语句中加入OPTION(RECOMPILE)查询提示,让其执行之前重编译SQL语句,他就可以正确地预估数据行了。
总结
本文通过一个实际案例说明了什么是简单参数模式下的自动化参数,自动化参数会带来哪些问题,以及如何解决,
问题本身非常简单,如果不注意还是会偶尔还是会出现困惑的。
题外话
有一点感受非常深,就是说,越来越多的实际问题,都要有理论知识作支撑,
但往往理论上说的情况并没有频繁出现或者即使出现了也没有引起注意,有时间就忽略了一些理论上的知识。
对于遇到的问题,如果真的要想弄清楚,还是要有一些理论知识做铺垫的。很多时候,往往是遇到问题之后,回忆起来曾经好似乎看过这一方面的理论知识。
这也是我们需要坚持看书,了解一些理论知识的原因。
SQL Server SQL性能优化之--数据库在“简单”参数化模式下,自动参数化SQL带来的问题的更多相关文章
- 浅谈SQL Server中的事务日志(三)----在简单恢复模式下日志的角色
简介 在简单恢复模式下,日志文件的作用仅仅是保证了SQL Server事务的ACID属性.并不承担具体的恢复数据的角色.正如”简单”这个词的字面意思一样,数据的备份和恢复仅仅是依赖于手动备份和恢复.在 ...
- SQL SERVER 查询性能优化——分析事务与锁(五)
SQL SERVER 查询性能优化——分析事务与锁(一) SQL SERVER 查询性能优化——分析事务与锁(二) SQL SERVER 查询性能优化——分析事务与锁(三) 上接SQL SERVER ...
- SQL Server 查询性能优化 相关文章
来自: SQL Server 查询性能优化——堆表.碎片与索引(一) SQL Server 查询性能优化——堆表.碎片与索引(二) SQL Server 查询性能优化——覆盖索引(一) SQL Ser ...
- Sql Server查询性能优化之走出索引的误区
据了解绝大多数开发人员对于索引的理解都是一知半解,局限于大多数日常工作没有机会.也什么没有必要去关心.了解索引,实在哪天某个查询太慢了找到查询条件建个索引就ok,哪天又有个查询慢了,再建立个索引就是, ...
- SQL Server查询性能优化——堆表、碎片与索引(二)
本文是对 SQL Server查询性能优化——堆表.碎片与索引(一)的一些总结. 第一:先对 SQL Server查询性能优化——堆表.碎片与索引(一)中的例一的SET STATISTICS IO之 ...
- SQL Server查询性能优化——覆盖索引(二)
在SQL Server 查询性能优化——覆盖索引(一)中讲了覆盖索引的一些理论. 本文将具体讲一下使用不同索引对查询性能的影响. 下面通过实例,来查看不同的索引结构,如聚集索引.非聚集索引.组合索引等 ...
- SET STATISTICS IO和SET STATISTICS TIME 在SQL Server查询性能优化中的作用
近段时间以来,一直在探究SQL Server查询性能的问题,当然也漫无目的的查找了很多资料,也从网上的大神们的文章中学到了很多,在这里,向各位大神致敬.正是受大神们无私奉献精神的影响,所以小弟也作为回 ...
- 浅谈SQL Server中的事务日志(四)----在完整恢复模式下日志的角色
简介 生产环境下的数据是如果可以写在资产负债表上的话,我想这个资产所占的数额一定不会小.而墨菲定律(事情如果有变坏的可能,无论这种可能性有多小,它总会发生)仿佛是给DBA量身定做的.在上篇文章介绍的简 ...
- SQL Server DBA性能优化
虽然查询速度慢的原因很多,但是如果通过一定的优化,也可以使查询问题得到一定程度的解决. 查询速度慢的原因很多,常见如下几种:1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷)2. ...
随机推荐
- 后台post get请求
/// <summary> /// 执行HTTP POST请求. /// </summary> /// <param name="url">请求 ...
- 控制TextField的内容长度
参考如下代码(下例是控制设置交易密码,控制6位): - (void)viewWillAppear:(BOOL)animated { [super viewWillAppear:animated]; [ ...
- IPC操作时IPC_CREAT和IPC_EXCL选项的说明
IPC(包括消息队列,共享内存,信号量)的xxxget()创建操作时,可以指定IPC_CREAT和IPC_EXCL选项.以共享内存为例:当只有IPC_CREAT选项打开时,不管是否已存在该块共享内存, ...
- 【实战Java高并发程序设计 2】无锁的对象引用:AtomicReference
AtomicReference和AtomicInteger非常类似,不同之处就在于AtomicInteger是对整数的封装,而AtomicReference则对应普通的对象引用.也就是它可以保证你在修 ...
- windows和linux中搭建python集成开发环境IDE——如何设置多个python环境
本系列分为两篇: 1.[转]windows和linux中搭建python集成开发环境IDE 2.[转]linux和windows下安装python集成开发环境及其python包 3.windows和l ...
- 你的应用是如何被替换的,App劫持病毒剖析
一.App劫持病毒介绍 App劫持是指执行流程被重定向,又可分为Activity劫持.安装劫持.流量劫持.函数执行劫持等.本文将对近期利用Acticity劫持和安装劫持的病毒进行分析. 二.Activ ...
- 剑指Offer面试题:29.丑数
一.题目:丑数 题目:我们把只包含因子2.3和5的数称作丑数(Ugly Number).求按从小到大的顺序的第1500个丑数.例如6.8都是丑数,但14不是,因为它包含因子7.习惯上我们把1当做第一个 ...
- Please Call Me NIO
与其他语言相比,Java的IO功能显得异常复杂,各种流操作,通过程序员多次封装才可以达到操作文件的目的.自从jdk1.4之后,java提供了一个新的api完成IO操作,人称New IO(NIO),使用 ...
- [备忘]Redis运行出现Client sent AUTH, but no password is set
原因:程序提供了密码,但是redis.conf中并没有设置密码. 附加问题:如果redis.conf中设置了密码,有可能会导致服务无法启动,报5013错误.可能是访问权限的问题.
- 入手Invicta 8926 OB潜水自动机械腕表
前个月前就想入手一款手表了,之前在关注和学习.询问他人选哪样的表好,前些天还在看精工Seiko机械表系列,今凌晨有朋友给我推荐这款Invicta 8926系列手表,我一看便喜欢了. 在网上也是搜索了很 ...