[C13] 应用实例:图片文字识别(Application Example: Photo OCR)
应用实例:图片文字识别(Application Example: Photo OCR)
问题描述和流程图(Problem Description and Pipeline)
图像文字识别应用所作的事是,从一张给定的图片中识别文字。这比从一份扫描文档中识别文字要复杂的多。

为了完成这样的工作,需要采取如下步骤:
文字侦测(Text detection)——将图片上的文字与其他环境对象分离开来
字符切分(Character segmentation)——将文字分割成一个个单一的字符
字符分类(Character classification)——确定每一个字符是什么
可以用任务流程图来表达这个问题,每一项任务可以由一个单独的小队来负责解决:

滑动窗口(Sliding Windows)
滑动窗口是一项用来从图像中抽取对象的技术。假使我们需要在一张图片中识别行人,首先要做的是用许多固定尺寸的图片来训练一个能够准确识别行人的模型。然后我们用之前训练识别行人的模型时所采用的图片尺寸在我们要进行行人识别的图片上进行剪裁,然后将剪裁得到的切片交给模型,让模型判断是否为行人,然后在图片上滑动剪裁区域重新进行剪裁,将新剪裁的切片也交给模型进行判断,如此循环直至将图片全部检测完。
一旦完成后,我们按比例放大剪裁的区域,再以新的尺寸对图片进行剪裁,将新剪裁的切片按比例缩小至模型所采纳的尺寸,交给模型进行判断,如此循环。

滑动窗口技术也被用于文字识别,首先训练模型能够区分字符与非字符,然后,运用滑动窗口技术识别字符,一旦完成了字符的识别,我们将识别得出的区域进行一些扩展,然后将重叠的区域进行合并。接着我们以宽高比作为过滤条件,过滤掉高度比宽度更大的区域(认为单词的长度通常比高度要大)。下图中绿色的区域是经过这些步骤后被认为是文字的区域,而红色的区域是被忽略的。

以上便是文字侦测阶段。
下一步是训练一个模型来完成将文字分割成一个个字符的任务,需要的训练集由单个字符的图片和两个相连字符之间的图片来训练模型。
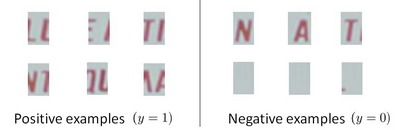

模型训练完后,我们仍然是使用滑动窗口技术来进行字符识别。
以上便是字符切分阶段。
最后一个阶段是字符分类阶段,利用神经网络、支持向量机或者逻辑回归算法训练一个分类器即可。
获取大量数据和人工数据(Getting Lots of Data and Artificial Data)
如果我们的模型是低方差的,那么获得更多的数据用于训练模型,是能够有更好的效果的。问题在于,我们怎样获得数据,数据不总是可以直接获得的,我们有可能需要人工地创造一些数据。
以我们的文字识别应用为例,我们可以字体网站下载各种字体,然后利用这些不同的字体配上各种不同的随机背景图片创造出一些用于训练的实例,这让我们能够获得一个无限大的训练集。这是从零开始创造实例。
另一种方法是,利用已有的数据,然后对其进行修改,例如将已有的字符图片进行一些扭曲、旋转、模糊处理。只要我们认为实际数据有可能和经过这样处理后的数据类似,我们便可以用这样的方法来创造大量的数据。
有关获得更多数据的几种方法:
人工数据合成
手动收集、标记数据
众包
上限分析:接下来做什么?(Ceiling Analysis / What Part of the Pipeline to Work on Next)
在机器学习的应用中,我们通常需要通过几个步骤才能进行最终的预测,我们如何能够知道哪一部分最值得我们花时间和精力去改善呢?这个问题可以通过上限分析来回答。
回到我们的文字识别应用中,我们的流程图如下:

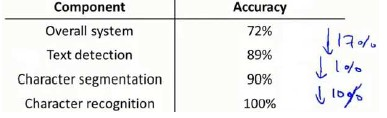
流程图中每一部分的输出都是下一部分的输入,上限分析中,我们选取一部分,手工提供100%正确的输出结果,然后看应用的整体效果提升了多少。假使我们的例子中总体效果为72%的正确率。
如果我们令文字侦测部分输出的结果100%正确,发现系统的总体效果从72%提高到了89%。这意味着我们很可能会希望投入时间精力来提高我们的文字侦测部分。
接着我们手动选择数据,让字符切分输出的结果100%正确,发现系统的总体效果只提升了1%,这意味着,我们的字符切分部分可能已经足够好了。
最后我们手工选择数据,让字符分类输出的结果100%正确,系统的总体效果又提升了10%,这意味着我们可能也会应该投入更多的时间和精力来提高应用的总体表现。
[C13] 应用实例:图片文字识别(Application Example: Photo OCR)的更多相关文章
- 斯坦福第十八课:应用实例:图片文字识别(Application Example: Photo OCR)
18.1 问题描述和流程图 18.2 滑动窗口 18.3 获取大量数据和人工数据 18.4 上限分析:哪部分管道的接下去做 18.1 问题描述和流程图
- 吴恩达机器学习笔记61-应用实例:图片文字识别(Application Example: Photo OCR)【完结】
最后一章内容,主要是OCR的实例,很多都是和经验或者实际应用有关:看完了,总之,善始善终,继续加油!! 一.图像识别(店名识别)的步骤: 图像文字识别应用所作的事是,从一张给定的图片中识别文字.这比从 ...
- Ng第十八课:应用实例:图片文字识别(Application Example: Photo OCR)
18.1 问题描述和流程图 18.2 滑动窗口 18.3 获取大量数据和人工数据 18.4 上限分析:哪部分管道的接下去做 18.1 问题描述和流程图 图像文字识别应用所作的事是,从一张给定 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 18—Photo OCR 应用实例:图片文字识别
Lecture 18—Photo OCR 应用实例:图片文字识别 18.1 问题描述和流程图 Problem Description and Pipeline 图像文字识别需要如下步骤: 1.文字侦测 ...
- 【图片识别】java 图片文字识别 ocr (转)
http://www.cnblogs.com/inkflower/p/6642264.html 最近在开发的时候需要识别图片中的一些文字,网上找了相关资料之后,发现google有一个离线的工具,以下为 ...
- java 图片文字识别 ocr
最近在开发的时候需要识别图片中的一些文字,网上找了相关资料之后,发现google有一个离线的工具,以下为java使用的demo 在此之前,使用这个工具需要在本地安装OCR工具: 下面一个是一定要安装的 ...
- python3 图片文字识别
最近用到了图片文字识别这个功能,从网上搜查了一下,决定利用百度的文字识别接口.通过测试发现文字识别率还可以.下面就测试过程简要说明一下 1.注册用户 链接:https://login.bce.baid ...
- 小试Office OneNote 2010的图片文字识别功能(OCR)
原文:小试Office OneNote 2010的图片文字识别功能(OCR) 自Office 2003以来,OneNote就成为了我电脑中必不可少的软件,它集各种创新功能于一身,可方便的记录下各种类型 ...
- 一篇文章搞定百度OCR图片文字识别API
一篇文章搞定百度OCR图片文字识别API https://www.jianshu.com/p/7905d3b12104
随机推荐
- python模块下载备份
https://pypi.org/ https://pypi.doubanio.com/simple/
- Shadow Map(单方向)
很早就想看阴影映射,一直拖到了现在,今天终于看了单方向的阴影映射,然后搭了个场景看了一下效果(每次搭场景感觉有点麻烦). 阴影映射的大体过程: // 1. 首选渲染深度贴图 glViewport(, ...
- JVM-10-JAVA 四种引用类型
JAVA 四中引用类型 1. 强引用 在 Java 中最常见的就是强引用,把一个对象赋给一个引用变量,这个引用变量就是一个强引用. 当一个对象被强引用变量引用时,它处于可达状态,不可能被垃圾回 ...
- KVM使用总结
目录 一.虚拟化介绍 二.通过kvm安装centos7系统 三.常用操作 虚拟机列表 开关机 导出虚拟机 重命名 挂起&恢复 查看某个虚拟机对应的端口 kvm开机启动 console登陆(失败 ...
- nginx学习(二):nginx显示默认首页解析过程
本篇文章分析下nginx 显示默认首页的过程 如下图所示 查看config文件: # 如果忘记nginx 安装目录.使用下面命令查看 [root@XXX]# whereis nginx nginx: ...
- WindowsOS下Nginx+PHP环境配置
Nginx 配置虚拟主机 在conf目录中的nginx.conf中最后一行前面加上 include vhost/*.conf; 在conf目录中添加一个文件夹vhost(此文件夹用来保存Nginx虚拟 ...
- Java并发编程:Java中的锁和线程同步机制
锁的基础知识 锁的类型 锁从宏观上分类,只分为两种:悲观锁与乐观锁. 乐观锁 乐观锁是一种乐观思想,即认为读多写少,遇到并发写的可能性低,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新 ...
- angularjs中ng-class常用写法,三元表达式、评估表达式与对象写法
壹 ❀ 引 ng-class可以说在angularjs样式开发中使用频率特别高了,这不我想利用ng-class的三元运算符的写法来定义一个样式,结果怎么都想不起来正确写法,恼羞成怒还是整理一遍吧,那 ...
- 安装torch
一.实验环境 1.Windows7x64_SP1 2.anaconda3.7 + python3.7(anaconda集成,不需单独安装) 二.问题描述 1.使用如下命令进行安装: pip3 inst ...
- python接口自动化8-unittest框架使用
前言 unittest:Python单元测试框架,基于Erich Gamma的JUnit和Kent Beck的sSmalltalk测试框架. 一.unittest框架基本使用 unittest需要注意 ...