分布式系统全局唯一ID的生成
分布式系统全局唯一ID的生成
一 、什么是分布式系统唯一ID
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。
如在金融、电商、支付、等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息,数据库的自增ID显然不能满足需求,此时一个能够生成全局唯一ID的系统是非常必要的。
二、分布式系统唯一ID的特点

- 全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
- 趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
- 单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求。
- 信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则。
- 同时除了对ID号码自身的要求,业务还对ID号生成系统的可用性要求极高,想象一下,如果ID生成系统瘫痪,这就会带来一场灾难。
由此总结下一个ID生成系统应该做到如下几点:
平均延迟和TP999延迟都要尽可能低(TP90就是满足百分之九十的网络请求所需要的最低耗时。TP99就是满足百分之九十九的网络请求所需要的最低耗时。同理TP999就是满足千分之九百九十九的网络请求所需要的最低耗时);
可用性5个9(99.999%);
高QPS。
补充:QPS和TPS
QPS:Queries Per Second意思是“每秒查询率”,是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
TPS:是TransactionsPerSecond的缩写,也就是事务数/秒。它是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数
三、分布式系统唯一ID的实现方案

1.UUID
UUID(Universally Unique Identifier)的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,示例:550e8400-e29b-41d4-a716-446655440000,到目前为止业界一共有5种方式生成UUID,详情见IETF发布的UUID规范 A Universally Unique IDentifier (UUID) URN Namespace。
优点:
- 性能非常高:本地生成,没有网络消耗。
缺点:
- 不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
- 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
- ID作为主键时在特定的环境会存在一些问题,比如做DB主键的场景下,UUID就非常不适用
2.数据库生成
以MySQL举例,利用给字段设置auto_increment_increment和auto_increment_offset来保证ID自增,每次业务使用下列SQL读写MySQL得到ID号。

这种方案的优缺点如下:
优点:
- 非常简单,利用现有数据库系统的功能实现,成本小,有DBA专业维护。
- ID号单调自增,可以实现一些对ID有特殊要求的业务。
缺点:
- 强依赖DB,当DB异常时整个系统不可用,属于致命问题。配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证。主从切换时的不一致可能会导致重复发号。
- ID发号性能瓶颈限制在单台MySQL的读写性能。
3.Redis生成ID
当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。
这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
比较适合使用Redis来生成每天从0开始的流水号。比如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key,使用INCR进行累加。
优点:
1)不依赖于数据库,灵活方便,且性能优于数据库。
2)数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
1)如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
2)需要编码和配置的工作量比较大。
4.利用zookeeper(分布式应用程序协调服务)生成唯一ID
zookeeper主要通过其znode数据版本来生成序列号,可以生成32位和64位的数据版本号,客户端可以使用这个版本号来作为唯一的序列号。
很少会使用zookeeper来生成唯一ID。主要是由于需要依赖zookeeper,并且是多步调用API,如果在竞争较大的情况下,需要考虑使用分布式锁。因此,性能在高并发的分布式环境下,也不甚理想。
5.snowflake(雪花算法)方案
这种方案大致来说是一种以划分命名空间(UUID也算,由于比较常见,所以单独分析)来生成ID的一种算法,这种方案把64-bit分别划分成多段,分开来标示机器、时间等,比如在snowflake中的64-bit分别表示如下图(图片来自网络)所示:
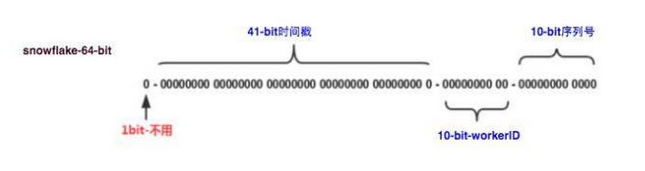
41-bit的时间可以表示(1L<<41)/(1000L360024*365)=69年的时间,10-bit机器可以分别表示1024台机器。如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义。12个自增序列号可以表示2^12个ID,理论上snowflake方案的QPS约为409.6w/s,这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的。
这种方式的优缺点是:
优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
- 可以根据自身业务特性分配bit位,非常灵活。
缺点:
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
分布式系统全局唯一ID的生成的更多相关文章
- 分布式系统全局唯一ID生成
一 什么是分布式系统唯一ID 在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识. 如在金融.电商.支付.等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息, ...
- 分布式系统中唯一 ID 的生成方法
在分布式系统存在多个 Shard 的场景中, 同时在各个 Shard 插入数据时, 怎么给这些数据生成全局的 unique ID? 在单机系统中 (例如一个 MySQL 实例), unique ID ...
- redis 学习笔记3(哨兵模式下分布式锁的实现以及全局唯一id的生成)
redis实现分布式锁和全局唯一id应该是较为常见的应用. 实现基于redis的setNX,以及incr命令.还是比较简单的! 搭建环境以及配置好sping整合,做了下测试,有兴趣的载下来看看,自己做 ...
- 全局唯一iD的生成 雪花算法详解及其他用法
一.介绍 雪花算法的原始版本是scala版,用于生成分布式ID(纯数字,时间顺序),订单编号等. 自增ID:对于数据敏感场景不宜使用,且不适合于分布式场景.GUID:采用无意义字符串,数据量增大时造成 ...
- 分布式全局唯一ID生成策略
为什么分布式系统需要用到ID生成系统 在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识.如在美团点评的金融.支付.餐饮.酒店.猫眼电影等产品的系统中,数据日渐增长,对数据库的分库分表后需要有 ...
- 分布式全局唯一ID的实现
分布式全局唯一ID的实现 前言 上周末考完试,这周正好把工作整理整理,然后也把之前的一些素材,整理一番,也当自己再学习一番. 一方面正好最近看到几篇这方面的文章,另一方面也是正好工作上有所涉及,所以决 ...
- 如何在高并发分布式系统中生成全局唯一Id
月整理出来,有兴趣的园友可以关注下我的博客. 分享原由,最近公司用到,并且在找最合适的方案,希望大家多参与讨论和提出新方案.我和我的小伙伴们也讨论了这个主题,我受益匪浅啊…… 博文示例: 1. ...
- 如何在高并发分布式系统中生成全局唯一Id(转)
http://www.cnblogs.com/heyuquan/p/global-guid-identity-maxId.html 又一个多月没冒泡了,其实最近学了些东西,但是没有安排时间整理成博文, ...
- (转)如何在高并发分布式系统中生成全局唯一Id
又一个多月没冒泡了,其实最近学了些东西,但是没有安排时间整理成博文,后续再奉上.最近还写了一个发邮件的组件以及性能测试请看 <NET开发邮件发送功能的全面教程(含邮件组件源码)> ,还弄了 ...
随机推荐
- Python正则表达式中re.S作用
re.S的作用: 不使用re.S时,则只在每一行内进行匹配,如果存在一行没有,就换下一行重新开始,使用re.S参数以后,正则表达式会将这个字符串看做整体,在整体中进行匹配 对比输出结果: import ...
- kafka相关操作
kafka安装 下载 wget http://apache.gree.com/apache/kafka/1.0.2/kafka_2.11-1.0.2.tgz tar -zxvf kafka_2.11- ...
- 2019.6.11_MySQL进阶二:主键与外键
通过图形界面(UI)创建外键 打开设计表,在对应的栏位填写相应的内容.其中FK_deptno是限制名 # 先给主表建立主键 ALTER TABLE dept ADD PRIMARY KEY(dep ...
- android appium微信等自动化的那些坑儿
1.下载appium自动化安装环境: appium客户端 python语言支持 android studio(包含android sdk和adb) java开发环境 2.微信x5内核调试(网上有详细配 ...
- Deformable Convolutional Networks
1 空洞卷积 1.1 理解空洞卷积 在图像分割领域,图像输入到CNN(典型的网络比如FCN)中,FCN先像传统的CNN那样对图像做卷积再pooling,降低图像尺寸的同时增大感受野,但是由于图像分割预 ...
- LuaFramework 学习
LuaFramework_UGUI_V2 https://github.com/jarjin/LuaFramework_UGUI_V2 using UnityEngine; using LuaInte ...
- 第一行代码 Android (郭霖 著)
https://github.com/guolindev/booksource 第1章 开始启程----你的第一行Android代码 (已看) 第2章 先从看得到的入手----探究活动 (已看) 第3 ...
- 2019 SDN上机第4次作业
1. 解压安装OpenDayLight控制器(本次实验统一使用Beryllium版本) 配置java环境 安装OpenDayLight控制器 2. 启动并安装插件 cd distribution-ka ...
- Paper | Feedback Networks
目录 读后总结 动机 故事 ConvLSTM图像分类网络 损失函数 与Episodic Curriculum Learning的结合 实验方法 发表在2017年CVPR. 读后总结 这篇论文旨在说明: ...
- Angular命令和基础操作
本文档假设你已经熟悉了 HTML,CSS,JavaScript和来自最新标准的一些知识,比如类和模块. 一.Angular命令 命令语法: 大多数命令以及少量选项,会有别名.别名会显示在每个命令的语法 ...