跟着大彬读源码 - Redis 8 - 对象编码之字典
字典,是一种用于保存键值对的抽象数据结构。由于 C 语言没有内置字典这种数据结构,因此 Redis 构建了自己的字典实现。
在 Redis 中,就是使用字典来实现数据库底层的。对数据库的 CURD 操作也是构建在对字典的操作之上。
除了用来表示数据库之外,字典还是哈希键的底层实现之一。当一个哈希键包含的键值对比较多,又或者键值对中的元素都是比较长的字符串时,Redis 就会适应字典作为哈希键的底层实现。
1 字典的实现
Redis 的字典使用哈希表作为底层实现。一个哈希表里面可以有多个哈希表节点,而每个哈希表节点就保存了字典中的一个键值对。
1.1 哈希表
Redis 字典所使用的哈希表结构:
typedef struct dictht {
dictEntry **table; // 哈希表数组
unsigned long size; // 哈希表大小
unsigned long sizemask; // 哈希表大小掩码,用来计算索引
unsigned long used; // 哈希表现有节点的数量
} dictht;
- table 属性是一个数组。数组中的每个元素都是一个指向 dictEntry 结构的指针,每个 dictEntry 结构保存着一个键值对。
- size 属性记录了哈希表的大小,也即是 table 数组的大小。
- used 属性记录了哈希表目前已有节点(键值对)的数量。
- sizemask 属性的值总数等于 size-1,这个属性和哈希值一起决定一个键应该被放到 table 数组中哪个索引上。
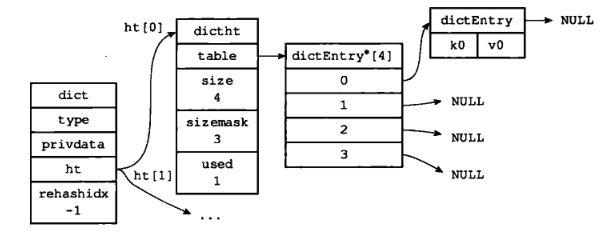
图 1 展示了一个大小为 4 的空哈希表。
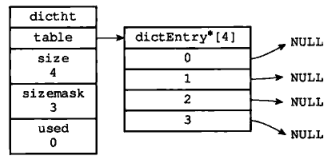
1.2 哈希表节点
哈希表节点使用 dictEntry 结构表示,每个 dictEntry 结构中都保存着一个键值对:
typedef struct dictEntry {
void *key; // 键
union {
void *val; // 值类型之指针
uint64_t u64; // 值类型之无符号整型
int64_t s64; // 值类型之有符号整型
double d; // 值类型之浮点型
} v; // 值
struct dictEntry *next; // 指向下个哈希表节点,形成链表
} dictEntry;
- key 属性保存着键,而 v 属性则保存着值。
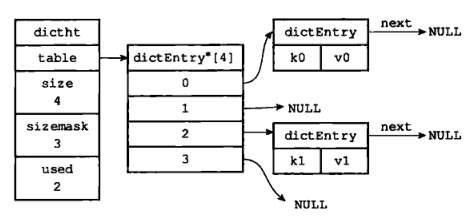
- next 属性是指向另一个哈希表节点的指针。这个指针可以将多个哈希值相同的键值对连接在一起,以此来解决键冲突的问题。
图 2 展示了通过 next 指针,将两个索引相同的键 k1 和 k0 连接在一起的情况。
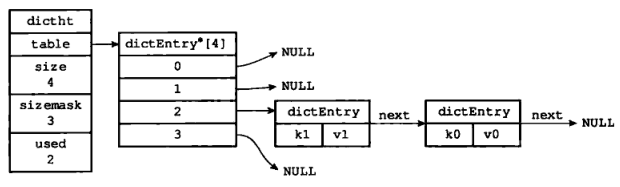
1.3 字典
字典的结构:
typedef struct dict {
dictType *type; // 类型特定函数
void *privdata; // 私有数据
dictht ht[2]; // 哈希表(两个)
long rehashidx; // 记录 rehash 进度的标志。值为 -1 表示 rehash 未进行
int iterators; // 当前正在迭代的迭代器数
} dict;
dictType 的结构如下:
typedef struct dictType {
// 计算哈希值的函数
unsigned int (*hashFunction)(const void *key);
// 复制键的函数
void *(*keyDup)(void *privdata, const void *key);
// 复制值的函数
void *(*valDup)(void *privdata, const void *obj);
// 对比键的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 销毁键的函数
void (*keyDestructor)(void *privdata, void *key);
// 销毁值的函数
void (*valDestructor)(void *privdata, void *obj);
} dictType;
type 属性和 privdata 属性是针对不同类型的键值对,为创建多态字典而设置的。其中:
- type 属性是一个指向 dictType 结构的指针,每个 dictType 结构保存了一簇用于操作特定类型键值对的函数。Redis 会为用途不用的字典设置不同的类型特定函数。
- privdata 属性保存了需要传给那些类型特定函数的可选参数。
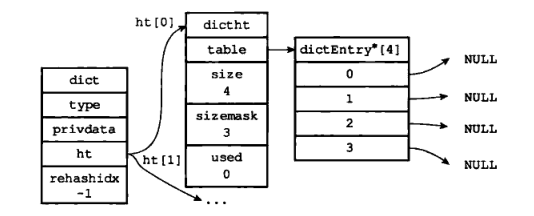
而 ht 属性是一个包含两个哈希表的数组。一般情况下,字典只使用 ht[0],只有在对 ht[0] 进行 rehash 时才会使用 ht[1]。
rehashidx 属性,它记录了 rehash 目前的进度,如果当前没有进行 rehash,它的值为 -1。至于什么是 rehash,别急,后面会详细说明。
图 3 是没有进行 rehash 的字典:
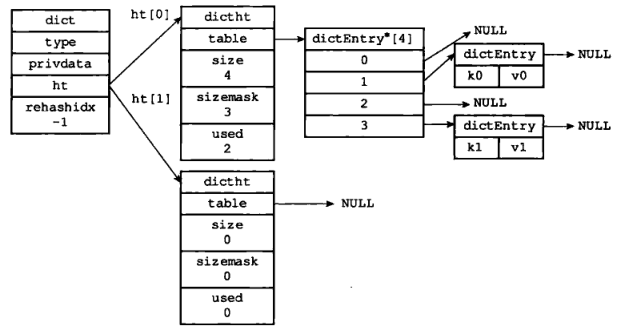
2 插入算法
当在字典中添加一个新的键值对时,Redis 会先根据键值对的键计算出哈希值和索引值,然后再根据索引值,将包含新键值对的哈希表节点放到哈希表数组指定的索引上。具体算法如下:
# 使用字典设置的哈希函数,计算 key 的哈希值
hash = dict->type->hashFunction(key);
# 使用哈希表的 sizemask 属性和哈希值,计算出索引值
# 根据不同情况,使用 ht[0] 或 ht[1]
index = hash & dict[x].sizemask;
如图 4,如果把键值对 [k0, v0] 添加到字典中,插入顺序如下:
hash = dict-type->hashFunction(k0);
index = hash & dict->ht[0].sizemask; # 8 & 3 = 0
计算得出,[k0, v0] 键值对应该被放在哈希表数组索引为 0 的位置上,如图 5:
2.1 键冲突
当有两个或以上数量的键被分配到了哈希表数组的同一个索引上面时,我们认为这些键发生了建冲突。
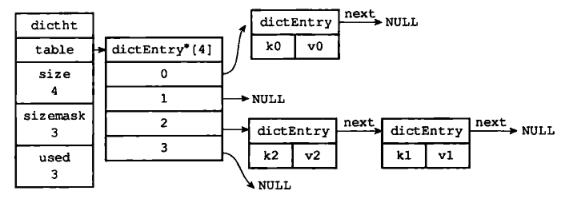
Redis 的哈希表使用链地址法来解决建冲突。每个哈希表节点都有一个 next 指针,多个哈希表节点可以用 next 指针构成一个单向链表,被分配到同一个索引的多个节点用 next 指针链接成一个单向链表。
举个栗子,假设我们要把 [k2, v2] 键值对添加到图 6 所示的哈希表中,并且计算得出 k2 的索引值为 2,和 k1 冲突,因此,这里就用 next 指针将 k2 和 k1 所在的节点连接起来,如图 7。
3 rehash 与 渐进式 rehash
随着对字典的操作,哈希表报错的键值对会逐渐增多或者减少,为了让哈希表的负载因子维持在一个合理的范围之内,当哈希表报错的键值对数量太多或者太少时,程序需要对哈希表进行相应的扩容或收缩。这个扩容或收缩的过程,我们称之为 rehash。
对于负载因子,可以通过以下公式计算得出:
# 负载因子 = 哈希表已保存节点数量 / 哈希表大小
load_factor = ht[0].used / ht[0].size;
3.1 哈希表的扩容与收缩
扩容
对于哈希表的扩容,源码如下:
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
当以下条件被满足时,程序会自动开始对哈希表执行扩展操作:
- 服务器当前没有进行 rehash;
- 哈希表已保存节点数量大于哈希表大小;
- dict_can_resize 参数为 1,或者负载因子大于设定的比率(默认为 5);
收缩
哈希表的收缩,源码如下:
int htNeedsResize(dict *dict) {
long long size, used;
size = dictSlots(dict); // ht[2] 两个哈希表的大小之和
used = dictSize(dict); // ht[2] 两个哈希表已保存节点数量之和
# DICT_HT_INITIAL_SIZE 默认为 4,HASHTABLE_MIN_FILL 默认为 10。
return (size > DICT_HT_INITIAL_SIZE &&
(used*100/size < HASHTABLE_MIN_FILL));
}
void tryResizeHashTables(int dbid) {
if (htNeedsResize(server.db[dbid].dict))
dictResize(server.db[dbid].dict);
if (htNeedsResize(server.db[dbid].expires))
dictResize(server.db[dbid].expires);
}
当 ht[] 哈希表的大小之和大于 DICT_HT_INITIAL_SIZE(默认 4),且已保存节点数量与总大小之比小于 4,HASHTABLE_MIN_FILL(默认 10,也就是 10%),会对哈希表进行收缩操作。
3.2 rehash
扩容和收缩哈希表都是通过执行 rehash 操作来完成,哈希表执行 rehash 的步骤如下:
- 为字典的 ht[1] 哈希表分配空间,这个哈希表的空间大小取决于要执行的操作,以及 ht[0] 当前包含的键值对数量。
- 如果执行的是扩容操作,那么 ht[1] 的大小为**第一个大于等于 ht[0].usedx2 的 2^n。
- 如果执行的是收缩操作,那么 ht[1] 的大小为第一个大于等于 ht[0].used 的 2^n。
- 将保存在 ht[0] 中的所有键值对 rehash 到 ht[1] 上面:rehash 指的是重新计算键的哈希值和索引值,然后将键值对都迁移到 ht[1] 哈希表的指定位置上。
- 当 ht[0] 包含的所有键值对都迁移到 ht[1] 后,此时 ht[0] 变成空表,释放 ht[0],将 ht[1] 设置为 ht[0],并在 ht[1] 新创建一个空白哈希表,为下一次 rehash 做准备。
示例:
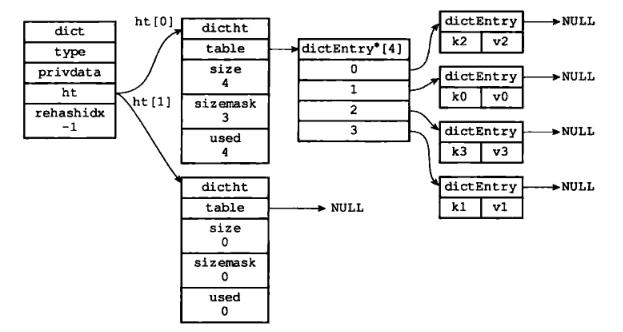
假设程序要对图 8 所示字典的 ht[0] 进行扩展操作,那么程序将执行以下步骤:
1)ht[0].used 当前的值为 4,那么 4*2 = 8,而 2^3 恰好是第一个大于等于 8 的,2 的 n 次方。所以程序会将 ht[1] 哈希表的大小设置为 8。图 9 是 ht[1] 在分配空间之后的字典。

2)将 ht[0] 包含的四个键值对都 rehash 到 ht[1],如图 10。

3)释放 ht[0],并将 ht[1] 设置为 ht[0],然后为 ht[1] 分配一个空白哈希表。如图 11:
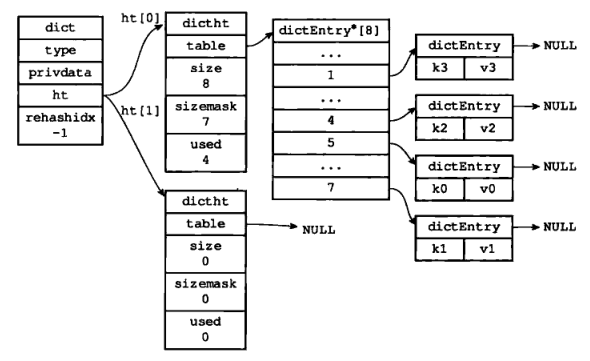
至此,对哈希表的扩容操作执行完毕,程序成功将哈希表的大小从原来的 4 改为了 8。
3.3 渐进式 rehash
对于 Redis 的 rehash 而言,并不是一次性、集中式的完成,而是分多次、渐进式地完成,所以也叫渐进式 rehash。
之所以采用渐进式的方式,其实也很好理解。当哈希表里保存了大量的键值对,要一次性的将所有键值对全部 rehash 到 ht[1] 里,很可能会导致服务器在一段时间内只能进行 rehash,不能对外提供服务。
因此,为了避免 rehash 对服务器性能造成影响,Redis 分多次、渐进式的将 ht[0] 里面的键值对 rehash 到 ht[1]。
渐进式 rehash 就用到了索引计数器变量 rehashidx,详细步骤如下:
- 为 ht[1] 分配空间,让字典同时持有 ht[0] 和 ht[1] 两个哈希表。
- 在字段中维持一个索引计数器变量 rehashidx,并将它的值设置为 0,表示开始 rehash。
- 在 rehash 期间,每次对字典执行 CURD 操作时,程序除了执行指定的操作外,还会将 ht[0] 哈希表在 rehashidx 索引上的所有键值对移动到 ht[1],当 rehash 完成后,程序将 rehashidx 的值加一。
- 随着不断操作字典,最终在某个时间点上,ht[0] 的所有键值对都会被 rehash 到 ht[1],这时程序将 rehashidx 属性的值设为 -1,表示 rehash 已完成。
渐进式 rehash 才有分而治之的方式,将 rehash 键值对所需要的计算工作均摊到对字典的 CURD 操作上,从而避免了集中式 rehash 带来的问题。
此外,字典在进行 rehash 时,删除、查找、更新等操作会在两个哈希表上进行。例如,在字典张查找一个键,程序会现在 ht[0] 里面进行查找,如果没找到,再去 ht[1] 上查找。
要注意的是,新增的键值对一律只保存在 ht[1] 里,不在对 ht[0] 进行任何添加操作,保证了 ht[0] 包含的键值对数量只减不增,随着 rehash 操作最终变成空表。
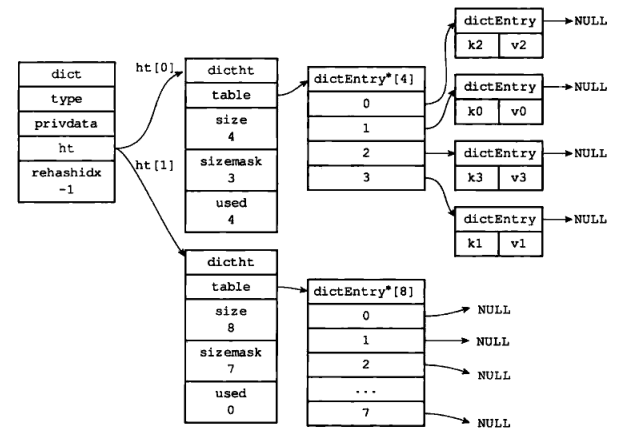
图 12 至 图 17 展示了一次完整的渐进式 rehash 过程:
1)未进行 rehash 的字典
2) rehash 索引 0 上的键值对
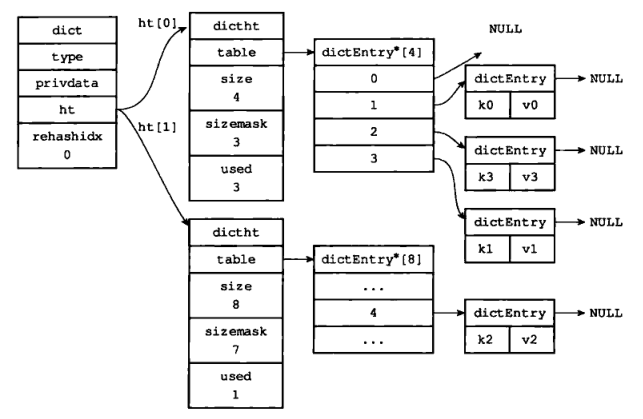
3)rehash 索引 1 上的键值对
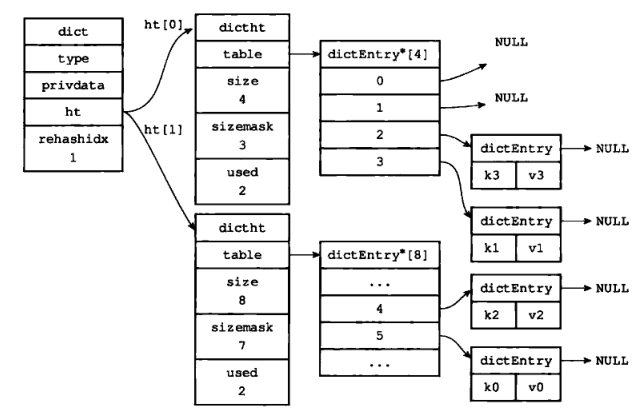
4)rehash 索引 2 上的键值对
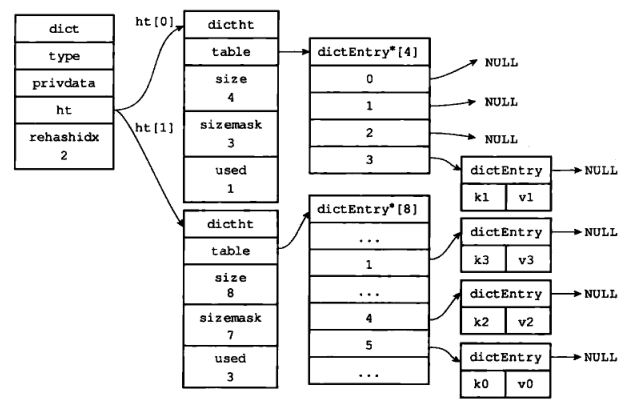
5)rehash 索引 3 上的键值对
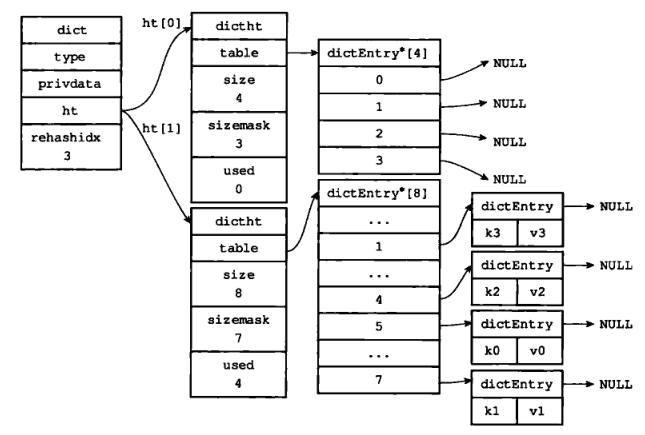
6)rehash 执行完毕
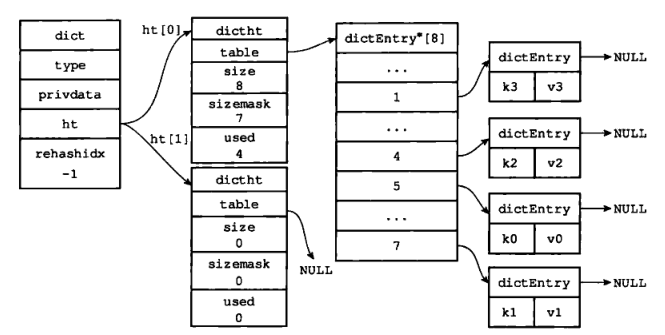
总结
- 字段被广泛用于实现 Redis 的各种功能,其中包括数据库和哈希键。
- Redis 中的字典使用哈希表作为底层实现,每个字典带有两个哈希表,一个平时使用,一个仅在 rehash 时使用。
- 哈希表使用链地址法来解决键冲突,被分配到同一个索引上的多个键值对会连接成一个单向链表。
- 在对哈希表进行扩容或收缩操作时,使用渐进式完成 rehash。
跟着大彬读源码 - Redis 8 - 对象编码之字典的更多相关文章
- 跟着大彬读源码 - Redis 7 - 对象编码之简单动态字符串
Redis 没有直接使用 C 语言传统的字符串表示(以空字符串结尾的字符数组),而是构建了一种名为简单动态字符串(simple dynamic string)的抽象类型,并将 SDS 用作 Redis ...
- 跟着大彬读源码 - Redis 9 - 对象编码之 三种list
目录 1 ziplist 2 skiplist 3 quicklist 总结 Redis 底层使用了 ziplist.skiplist 和 quicklist 三种 list 结构来实现相关对象.顾名 ...
- 跟着大彬读源码 - Redis 10 - 对象编码之整数集合
[TOC] 整数集合是 Redis 集合键的底层实现之一.当一个集合只包含整数值元素,并且元素数量不多时,Redis 就会使用整数集合作为集合键的底层实现. 1 整数集合的实现 整数集合是 Redis ...
- 跟着大彬读源码 - Redis 6 - 对象和数据类型(下)
继续撸我们的对象和数据类型. 上节我们一起认识了字符串和列表,接下来还有哈希.集合和有序集合. 1 哈希对象 哈希对象的可选编码分别是:ziplist 和 hashtable. 1.1 ziplist ...
- 跟着大彬读源码 - Redis 5 - 对象和数据类型(上)
相信很多人应该都知道 Redis 有五种数据类型:字符串.列表.哈希.集合和有序集合.但这五种数据类型是什么含义?Redis 的数据又是怎样存储的?今天我们一起来认识下 Redis 这五种数据结构的含 ...
- 跟着大彬读源码 - Redis 1 - 启动服务,程序都干了什么?
一直很羡慕那些能读 Redis 源码的童鞋,也一直想自己解读一遍,但迫于 C 大魔王的压力,解读日期遥遥无期. 相信很多小伙伴应该也都对或曾对源码感兴趣,但一来觉得自己不会 C 语言,二来也不知从何入 ...
- 跟着大彬读源码 - Redis 2 - 服务器如何响应客户端请求?(上)
上次我们通过问题"启动服务器,程序都干了什么?",跟着源码,深入了解了 Redis 服务器的启动过程. 既然启动了 Redis 服务器,那我们就要连上 Redis 服务干些事情.这 ...
- 跟着大彬读源码 - Redis 3 - 服务器如何响应客户端请求?(下)
继续我们上一节的讨论.服务器启动了,客户端也发送命令了.接下来,就要到服务器"表演"的时刻了. 1 服务器处理 服务器读取到命令请求后,会进行一系列的处理. 1.1 读取命令请求 ...
- 跟着大彬读源码 - Redis 4 - 服务器的事件驱动有什么含义?(上)
众所周知,Redis 服务器是一个事件驱动程序.那么事件驱动对于 Redis 而言有什么含义?源码中又是如何实现事件驱动的呢?今天,我们一起来认识下 Redis 服务器的事件驱动. 对于 Redis ...
随机推荐
- 跟我学SpringCloud | 第五篇:熔断监控Hystrix Dashboard和Turbine
SpringCloud系列教程 | 第五篇:熔断监控Hystrix Dashboard和Turbine Springboot: 2.1.6.RELEASE SpringCloud: Greenwich ...
- docker安装gitlab-runner
docker安装gitlab-runner docker pull gitlab/gitlab-runner:latest安装gitlab-runner 打开自己搭建的GitLab网站,点击顶栏的Sn ...
- 关于java中构造方法、实例初始化、静态初始化执行顺序
在Java笔试中,构造方法.实例初始化.静态初始化执行顺序,是一个经常被考察的知识点. 像下面的这道题(刚刚刷题做到,虽然做对了,但是还是想整理一下) 运行下面的代码,输出的结果是... class ...
- 网络虚拟化基础协议·Geneve
[分层] 要实现网络虚拟化,最基础的技术肯定是分层(OverLay & UnderLay). ·UnderLay 中文释义中,老房子漏雨,在房子里面撑一把大雨伞,这把大雨伞就是UnderLay ...
- WinForm控件之【MonthCalendar】
基本介绍 日期月历控件,顾名思义用来主要用来展示月历,获取年份.月份.日期.时分秒信息等 常设置属性 FirstDayOfWeek:面板展示周期的循序,一周的第一天由从周几开始排列: MaxDate: ...
- ZIP:Checksum
Checksum: long getValue() :返回当前的校验和值. void reset() :将校验和重置为其初始值. void update(byte[] b, int off, int ...
- mac环境下java项目无创建文件的权限
1.问题: 先抛问题,由于刚刚换用mac环境,之前windows上开发的代码调试完毕,还未上线.之后上线部署之前,tl直连测试本地环境(mac)环境,功能无法使用,显示java.io.IOExcept ...
- aspnetcore 刷新Session Id总是改变
public class Startup { public Startup(IConfiguration configuration) { Configuration = configuration; ...
- JavaScript剩余操作符Rest Operator
本文适合JavaScript初学者阅读 剩余操作符 之前这篇文章JavaScript展开操作符(Spread operator)介绍讲解过展开操作符.剩余操作符和展开操作符的表示方式一样,都是三个点 ...
- python函数知识二 动态参数、函数的注释、名称空间、函数的嵌套、global,nonlocal
6.函数的动态参数 *args,**kwargs:能接受动态的位置参数和动态的关键字参数 *args -- tuple *kwargs -- dict 动态参数优先级:位置参数 > 动态位置参数 ...