Mysql - 高可用方案之MMM(二)
一、概述
上一篇博客中(https://www.cnblogs.com/ddzj01/p/11535796.html)介绍了如何搭建MMM架构,本文将通过实验介绍MMM架构的优缺点。
二、优点
1. 写vip转移
关掉node1的mysql,看集群会发生什么变化
[root@mysqla ~]# service mysql stop
在monitor查看集群状态
[root@monitor ~]# mmm_control show

在node3中查看
(root@localhost)[(none)]> show slave status\G

可以看到写vip(10.40.16.71)已经漂移到node2,并且node3重新指向了node2
2. 读vip漂移
启动node1的mysql
[root@mysqla ~]# service mysql start
在monitor查看集群状态(可能需要等接近一分钟才能看到下面的状态)
如果长时间是AWAITING_RECOVERY状态,可以去日志中查看原因/var/log/mysql-mmm/mmm_mond.log,确认都没有问题可以使用手工将节点上线"mmm_control set_online db1"
[root@monitor ~]# mmm_control show

可以看到node1又重新加到集群中了,并且有一个读vip已经漂移到node1上了
关闭node3(从库)的mysql
[root@mysqlc ~]# service mysql stop
在monitor查看集群状态
[root@monitor ~]# mmm_control show

可以看到node3(从库)的读vip漂移到了node1上,node3(从库)没有任何读vip了
3. 读延迟
启动node3(从库)的mysql
[root@mysqlc ~]# service mysql start
在monitor查看集群状态
[root@monitor ~]# mmm_control show

在monitor中编辑/etc/mysql-mmm/mmm_mon.conf
添加max_backlog参数,这个参数指的是集群中从库落后于主库多长时间,就将从库上面的读vip摘除。默认是60。
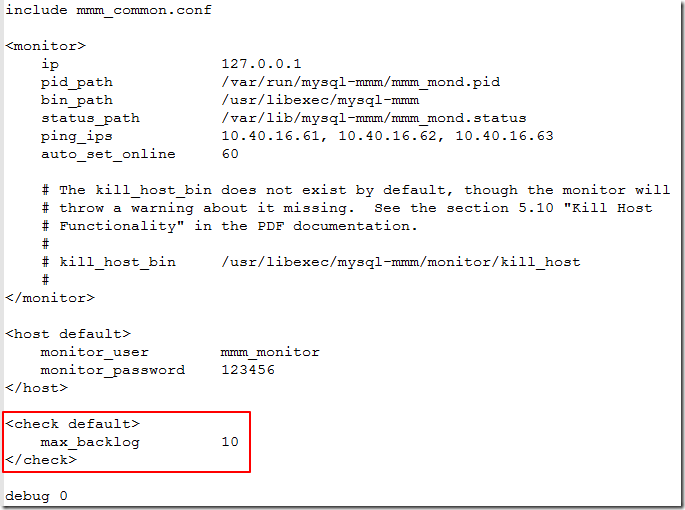
在monitor上重启进程
[root@monitor ~]# service mysql-mmm-monitor restart
在node3(从库)将数据库锁住
(root@localhost)[(none)]> flush tables with read lock;
在node2(主库)对数据库随便做点修改
(root@localhost)[test1]> insert into t1 values(20);
在node3(从库)查看从库状态
(root@localhost)[(none)]> show slave status\G
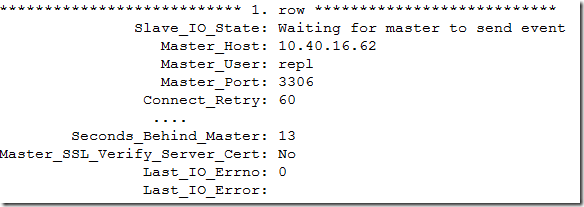
可以看到从库已经落后了13秒了
在monitor查看状态
[root@monitor ~]# mmm_control checks all
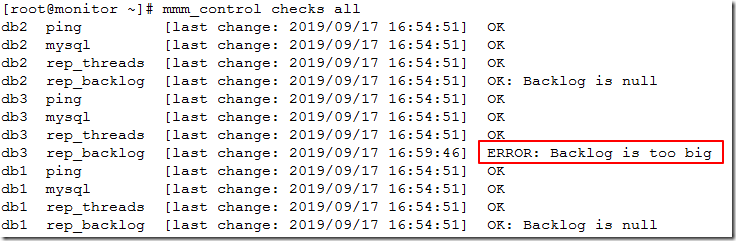
可以看到node3显示ERROR: Backlog is too big
[root@monitor ~]# mmm_control show

可以看到node3的读vip又飘走了。
三、缺点
1. 新主如果落后于旧主,故障切换时,容易造成新主的数据丢失
这个好理解,mysql主从采用的是异步架构,主库的日志如果还没有传到从库上就已经down了,从库就丢失这部分事务了。MMM这种架构也不例外。
2. 事务重复提交的问题
在monitor中编辑/etc/mysql-mmm/mmm_mon.conf,将max_backlog参数删除

在monitor上重启进程
[root@monitor ~]# service mysql-mmm-monitor restart
在node3(从库)将数据库锁释放
(root@localhost)[(none)]> unlock tables;
在monitor查看状态
[root@monitor ~]# mmm_control show 
现在承担写角色的是节点2
先把node1的sql_thread停掉,模拟node1落后于node2的情况(这种情况是指node1已经接收到node2的日志,但是还没有应用)
(root@localhost)[test1]> stop slave sql_thread;
在node2上插入一条数据
(root@localhost)[test1]> insert into t1 values(20);
然后把node2的msyql关闭
[root@mysqlb ~]# service mysql stop
在monitor查看状态
[root@monitor ~]# mmm_control show

可以看到写vip飘到node1上了
再重启node1的slave进程
(root@localhost)[test1]> stop slave;
(root@localhost)[test1]> start slave;
再来查看node1和node3上t1这张表的数据
node1
(root@localhost)[test1]> select * from t1;
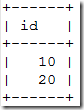
node3
(root@localhost)[test1]> select * from t1;
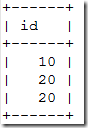
(root@localhost)[test1]> show slave status\G
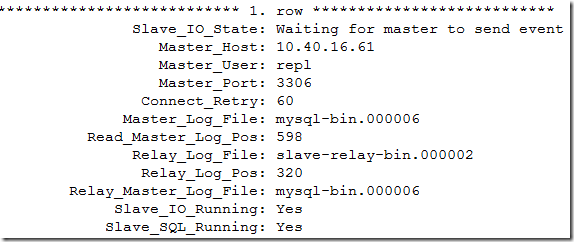
可以看到新主变成node1,但是node3上面20却有两条,出现了事务重复提交的情况。
3. 从库丢失事务的情况
先把node2的msyql打开
[root@mysqlb ~]# service mysql start
在monitor查看状态
[root@monitor ~]# mmm_control show

在node1把t1表truncate
(root@localhost)[test1]> truncate table t1;
把node3的sql_thread停掉,模拟node3落后于node1的情况(这种情况是指node3已经接收到node1的日志,但是还没有应用)
(root@localhost)[test1]> stop slave sql_thread;
在node1上插入一条数据
(root@localhost)[test1]> insert into t1 values(10);
把node1的msyql关闭
[root@mysqlb ~]# service mysql stop
再重启node3的slave进程
(root@localhost)[test1]> stop slave;
(root@localhost)[test1]> start slave;
查看node3的复制状态
(root@localhost)[test1]> show slave status\G
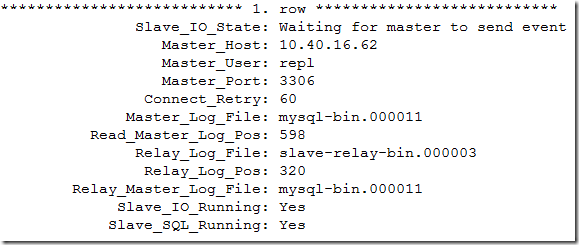
可以看到节点重新指向了node2
查看各节点的t1数据
node2
(root@localhost)[test1]> insert into t1 values(20);
(root@localhost)[test1]> select * from t1;
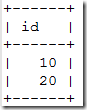
node3
(root@localhost)[test1]> select * from t1;

可以看到现在是同步了,但是此时从库已经丢失了原主库的事务,即10这条数据。
四、总结
MMM这种高可用架构比较老了,从库的数据一致性很难保证,所以在生产上尽量不要使用这种架构。后面将给大家介绍mysql的另一种高可用架构MHA。
Mysql - 高可用方案之MMM(二)的更多相关文章
- Mysql - 高可用方案之MMM(一)
一.概述 本文将介绍mysql的MMM(Master-Master replication manager for MySQL)方案.官方文档地址:https://mysql-mmm.org/star ...
- MySQL高可用方案 MHA之二 master_ip_failover
异步主从复制架构master:10.150.20.90 ed3jrdba90slave:10.15.20.97 ed3jrdba9710.150.20.132 ed3jrdba132manager:1 ...
- [转载] MySQL高可用方案选型参考
原文: http://imysql.com/2015/09/14/solutions-of-mysql-ha.shtml?hmsr=toutiao.io&utm_medium=toutiao. ...
- MySQL高可用方案-PXC环境部署记录
之前梳理了Mysql+Keepalived双主热备高可用操作记录,对于mysql高可用方案,经常用到的的主要有下面三种: 一.基于主从复制的高可用方案:双节点主从 + keepalived 一般来说, ...
- 五大常见的MySQL高可用方案【转】
1. 概述 我们在考虑MySQL数据库的高可用的架构时,主要要考虑如下几方面: 如果数据库发生了宕机或者意外中断等故障,能尽快恢复数据库的可用性,尽可能的减少停机时间,保证业务不会因为数据库的故障而中 ...
- [转]MYSQL高可用方案探究(总结)
前言 http://blog.chinaunix.net/uid-20639775-id-3337432.htmlLvs+Keepalived+Mysql单点写入主主同步高可用方案 http://bl ...
- MySQL高可用方案MHA的部署和原理
MHA(Master High Availability)是一套相对成熟的MySQL高可用方案,能做到在0~30s内自动完成数据库的故障切换操作,在master服务器不宕机的情况下,基本能保证数据的一 ...
- MySQL高可用方案MHA自动Failover与手动Failover的实践及原理
集群信息 角色 IP地址 ServerID 类型 Master ...
- MySQL高可用方案-PXC(Percona XtraDB Cluster)环境部署详解
MySQL高可用方案-PXC(Percona XtraDB Cluster)环境部署详解 Percona XtraDB Cluster简称PXC.Percona Xtradb Cluster的实现是在 ...
随机推荐
- html元素是否包含另外一个元素,以及classList属性
如何判断一个元素A包含了元素B呢?如果不用contains方法的话,如何做呢? 腾讯面试的时候也出了这道题啊,当时没看dom的知识,所以一抹黑哦... 那就判断B是否为A的child喽,那也就是A是B ...
- 【经验分享】如何搭建本地MQTT服务器(Windows ),并进行上下行调测
网上查了很多资料,实际动手的时候踩了很多坑,现在把我的经验分享给大家: 一.安装和启动 使用EMQTT,下载完直接到bin目录下执行emqttd start就可以了,简单方便 下载地址:https:/ ...
- 谁说微服务是Spring Cloud的独角戏?Service Mesh了解一下?
Service Mesh 的概念自 2017 年初提出之后,受到了业界的广泛关注,作为微服务的下一代发展架构在社区迅速发酵,并且孵化出了诸如 Istio 等广受业界关注的面向于云原生 (Cloud N ...
- 开发者如何学好 MongoDB
作为一名研发,数据库是或多或少都会接触到的技术. MongoDB 是当前火热的 NoSQL 之一,我们怎样才能学好 MongoDB 呢?本篇文章,我们将从以下几方面讨论这个话题: MongoDB 是什 ...
- 5G,仅仅是更快的网速吗?
前不久参加了华为的Dev Summit 2020开发者大会,听到了关于5G的一些分享,刚好最近对5G有一些自己的思考,在此分享给大家. 什么是5G 在这里我不想列举各种晦涩难懂的术语,简单说来,5G就 ...
- 使用Python进行防病毒免杀
很多渗透工具都提供了权限维持的能力,如Metasploit.Empire和Cobalt Strike,但是都会被防病毒软件检测到这种恶意行为.在探讨一个权限维持技巧的时候,似乎越来越多的人关注的是,这 ...
- APP Distribution Guide 苹果官网
https://developer.apple.com/library/ios/documentation/IDEs/Conceptual/AppDistributionGuide/Introduct ...
- [TimLinux] Python 自定义描述符
1. 含义 在类中,含有属性(该属性需要存在类对象到__dict__属性中,不能为存在示例对象的__dict__属性中),对属性对操作(访问,设置值,删除)可以自定义行为,这样对自定义行为成为自定义属 ...
- AcWing 291.蒙德里安的梦想
题目:蒙德里安的梦想 链接:(蒙德里安的梦想)[https://www.acwing.com/problem/content/293/] 题意:求把N * M的棋盘分割成若干个1 * 2的长方形,有多 ...
- Selenium之xpath绝对路径表示法
xpath写法: 绝对路径:以/开始,逐个增加节点用/分割 特点:不能跨级.类似css中的直接子元素选择器 相对路径:用两个斜杠 // 如 //div//p//a 通配符:xpath也有 ...