Disruptor中shutdown方法失效,及产生的不确定性源码分析
版权声明:原创作品,谢绝转载!否则将追究法律责任。
Disruptor框架是一个优秀的并发框架,利用RingBuffer中的预分配内存实现内存的可重复利用,降低了GC的频率。
具体关于Disruptor的原理,参见:http://ifeve.com/disruptor/,本文不在赘述。
在Disruptor的使用中,偶尔会出现调用了shutdown函数但程序并未终止的现象。在网上已有的文章中并没有对该问题的分析,本文对此现象进行总结和说明:
例子:相关的Event、EventHandler、Producer及OrderFactory定义
1.1 消费事件Event类Order
Order用于生产者生产事件,消费者消费事件。是RingBuffer的槽中存储的数据类型。其定义如下:
package liuqiang.instance;
public class Order {
private String id;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
}
Order类中由一个id成员,用于生产者生产和消费者消费。
1.2 事件处理器OrderHandler1
定义一个事件处理器OrderHandler1。
package liuqiang.instance;
import com.lmax.disruptor.EventHandler;
import java.util.concurrent.atomic.AtomicInteger;
public class OrderHandler1 implements EventHandler<Order>{
private String consumerId;
private static AtomicInteger count = new AtomicInteger(0);
public OrderHandler1(String consumerId){
this.consumerId = consumerId;
}
public static int getCount(){
return count.get();
}
@Override
public void onEvent(Order order, long sequence, boolean endOfBatch) throws Exception {
System.out.println("OrderHandler1 " + this.consumerId + ",消费信息:" + order.getId());
count.incrementAndGet();
}
}
每次消费一个事件,count静态变量自增1次。
1.3 生产者Producer
生产者用于在ringBuffer放入生产的order信息。
package liuqiang.instance;
import com.lmax.disruptor.RingBuffer;
public class Producer {
private final RingBuffer<Order> ringBuffer;
public Producer(RingBuffer<Order> ringBuffer){
this.ringBuffer = ringBuffer;
}
public void onData(String data){
long sequence = ringBuffer.next();
try {
Order order = ringBuffer.get(sequence);
order.setId(data);
} finally {
ringBuffer.publish(sequence);
}
}
}
onData方法首先获得Order的id属性值data,然后通过ringBuffer获取下一个sequence,并将data值填充进Order对象当中。
ringBuffer中预先分配了order数组,生产过程仅仅是将数组中的对象属性更改,因此大大减少了gc过程。
ringBuffer中预生成order对象数组,需要一个工厂方法。
1.4 消费事件的工厂方法OrderFactory
package liuqiang.instance;
import com.lmax.disruptor.EventFactory;
public class OrderFactory implements EventFactory<Order> {
@Override
public Order newInstance() {
return new Order();
}
}
该工厂方法重写了父类的newInstance方法,该方法仅仅是new一个尚未填充属性信息的Order对象,用于在RingBuffer中预先占据内存。
场景一:disruptor.shutdown操作先于BatchEventProcessor的线程执行
package liuqiang.instance; import com.lmax.disruptor.*;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.dsl.ProducerType; import java.util.concurrent.Executors; public class Main1 { public static void main(String[] args) throws Exception {
EventFactory<Order> factory = new OrderFactory();
int ringBufferSize = 1024 * 1024;
Disruptor<Order> disruptor =
new Disruptor<Order>(factory, ringBufferSize, Executors.defaultThreadFactory(), ProducerType.SINGLE, new YieldingWaitStrategy());
disruptor.handleEventsWith(new OrderHandler1("1"), new OrderHandler1("2")); //两个独立的消费者,各自对消费ringBuffer中的所有事件。
disruptor.start();
RingBuffer<Order> ringBuffer = disruptor.getRingBuffer();
Producer producer = new Producer(ringBuffer);
//producer生产1个对象,并存入ringBuffer数组当中
for (long l = 0; l < 1; l++) {
producer.onData(l + "");
}
disruptor.shutdown(); //方法会阻塞,但该方法执行结束后,并不一定会使程序关闭,后面详细分析原因。
}
}
最终打印结果如下:
OrderHandler1 1,消费信息:0
OrderHandler1 2,消费信息:0
两个消费者都已经消费掉了生产者生产的一个事件。然而,该程序多次运行,会发现存在某些次运行过程消费完事件后,程序并没有终止。调用jconsole查看线程相关信息,如下:
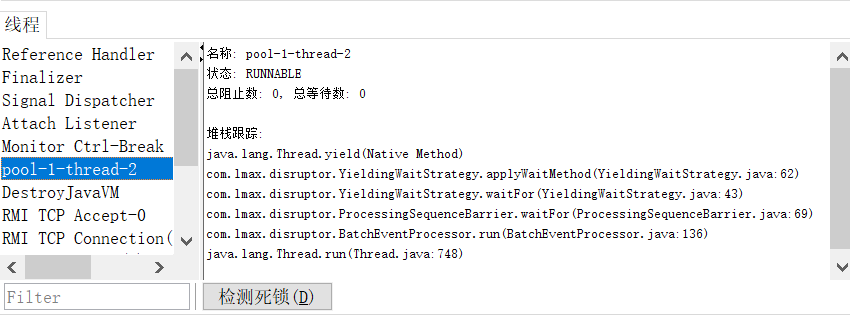
BatchEventProcess的run方法中,调用消费者Handler方法进行消费。
显然,shutdown关闭之后,该消费者依然在等待RingBuffer中新的event进行消费。这个问题是如何产生的呢?
disruptor的start方法如下:
public RingBuffer<T> start()
{
//开启Disruptor,保证只被开启一次
checkOnlyStartedOnce();
for (final ConsumerInfo consumerInfo : consumerRepository)
{
consumerInfo.start(executor);
} return ringBuffer;
}
由此可见,start方法非阻塞的。将消费者线程放入一个线程池之后,即返回。start方法执行结束,此时的消费者线程未必会立刻运行!
我们继续看,disruptor.shutdown方法。
public void shutdown()
{
try
{
shutdown(-1, TimeUnit.MILLISECONDS); //超时shutdown,此时超时时间设置为-1,表示一直阻塞,直到关闭
}
catch (final TimeoutException e)
{
exceptionHandler.handleOnShutdownException(e);
}
}
public void shutdown(final long timeout, final TimeUnit timeUnit) throws TimeoutException
{
final long timeOutAt = System.currentTimeMillis() + timeUnit.toMillis(timeout);// 此处可能积压事件处理完了,但生产者还没有生产完
while (hasBacklog())
{
if (timeout >= 0 && System.currentTimeMillis() > timeOutAt)
{
throw TimeoutException.INSTANCE;
}
// Busy spin
}
halt();
}
// 此处可能积压事件处理完了,但生产者还没有生产完
private boolean hasBacklog()
{
final long cursor = ringBuffer.getCursor();
//获取所有除去已经停止的customer之外的所有的sequence
for (final Sequence consumer : consumerRepository.getLastSequenceInChain(false)) //false参数。表明已经停止或未启动的消费者,不再考虑
{
//说明有消费者还没有消费完cursor
if (cursor > consumer.get())
{
return true;
}
}
//所有消费者都已经消费完所有事件,不存在积压的未处理事件
return false;
}
public void halt()
{
for (final ConsumerInfo consumerInfo : consumerRepository)
{
consumerInfo.halt();
}
}
此处关闭过程主要分为两部分:
1. 判断RingBuffer当中是否还有未消费完的事件。
2. 所有事件都消费完之后,调用halt终止各个Customer。
consumerRepository.getLastSequenceInChain(false)
false参数表示只取消费者线程集合中正在运行的消费者线程,并将对应消费者线程的alert标记置为true。尚未启动的消费者线程不受影响。
此处为何要设置参数为false呢?个人理解为:消费者线程在运行中可能会抛出异常造成线程退出。如果shutdown方法考虑到这些消费者线程,则该消费者线程将永远不可能消费RingBuffer中的event,造成阻塞。
另外解释一下getLastSequenceInChain的意义,我们在编写消费者的时候,常常会存在消费者之间的依赖关系。例如:消费者A先消费event,然后消费者B、C同时消费该event,最后消费者D在B、C之后最后消费该event。这样的结构,有利于编写出流水线式的处理。具体如下图所示:
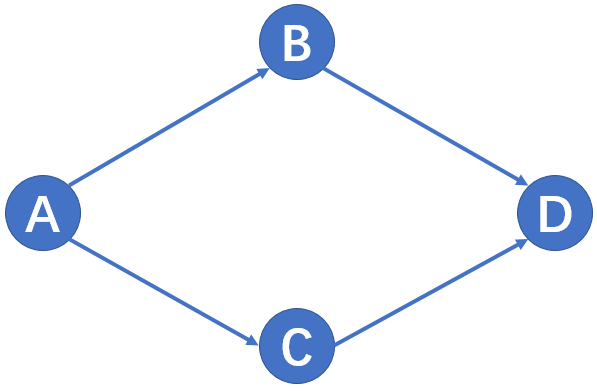
一个事件event,最后处理该事件的event一定是D,D处理过的事件,前驱消费者A、B、C一定都已经消费过了。在判断消费者集合中是否所有消费者都已经消费完某event,可以直接取依赖的末端消费者集合,进行判断即可。
getLastSequenceInChain方法即是完成该操作。
public Sequence[] getLastSequenceInChain(boolean includeStopped) //返回集合是否要包含未启动或已停止的消费者线程
{
List<Sequence> lastSequence = new ArrayList<>();
for (ConsumerInfo consumerInfo : consumerInfos)
{
//includeStopped为true,则无论消费者线程是否已经在执行,都返回。
if ((includeStopped || consumerInfo.isRunning()) && consumerInfo.isEndOfChain())
{
final Sequence[] sequences = consumerInfo.getSequences();
Collections.addAll(lastSequence, sequences);
}
} return lastSequence.toArray(new Sequence[lastSequence.size()]);
}
由于disruptor的shutdown方法中,最终调用的getLastSequenceInChain方法,inclueStopped为false。因此,如果消费者线程在调用shutown的时候尚未开启,此时就会导致返回的Sequence序列漏掉了这部分线程。导致shutdown方法失效。
第二部分操作:halt,该方法最终调用BatchEventProcessor线程的halt方法。BatchEventProcessor线程负责对消费者OrderHandler1进行循环调用。其halt方法:
public void halt()
{
running.set(false); //运行状态设置为false
sequenceBarrier.alert(); //Barrier调用alert方法,在后面消费者消费的时候,会查看该状态,以决定是否阻塞在ringBuffer上等待事件。
}
BatchEventProcessor线程的run方法如下。disruptor的shutdown方法最终的效果是,设置了正在运行的消费者线程的BatchEventProcessor的alert状态。而即便我们将shutdown调用过程中的getLastSequenceInChain方法的includeStopped设置为true,获取到未开启的消费者线程,在消费者线程执行的第一步也会将alert状态清除(sequenceBarrier.clearAlert();调用重置了alert的状态为false)。
@Override
public void run()
{
//确保一次只有一个线程执行这个方法
if (!running.compareAndSet(false, true))
{
throw new IllegalStateException("Thread is already running");
}
//清除sequenceBarrier的通知状态!!!该代码是导致shutdown不起效果的原因
sequenceBarrier.clearAlert();
//通知生命周期eventHandler,事件处理开始
notifyStart();
T event = null;
//获取下一个应当进行消费的序号
long nextSequence = sequence.get() + 1L;
try
{
while (true)
{
try
{
//准备获取下一个可用于消费者线程的sequence。抛出AlertException,说明disruptor已经运行结束了。
final long availableSequence = sequenceBarrier.waitFor(nextSequence);
if (batchStartAware != null)
{
batchStartAware.onBatchStart(availableSequence - nextSequence + 1);
}
//针对从nextSequence到availableSequence的每一个event,调用相应的事件处理器进行处理
while (nextSequence <= availableSequence)
{
event = dataProvider.get(nextSequence);
eventHandler.onEvent(event, nextSequence, nextSequence == availableSequence);
nextSequence++;
}
//当前消费到的序号写入sequence的value变量
sequence.set(availableSequence);
}
catch (final TimeoutException e)
{
notifyTimeout(sequence.get());
}
catch (final AlertException ex)
{
if (!running.get())
{
break;
}
}
catch (final Throwable ex)
{
exceptionHandler.handleEventException(ex, nextSequence, event);
sequence.set(nextSequence);
nextSequence++;
}
}
}
finally
{
//事件处理完毕,发送关闭通知。
notifyShutdown();
//线程运行完毕,设置运行状态为false
running.set(false);
}
}
线程中会调用SequenceBarrier的waitFor方法等待下一个可消费事件的序号。该方法如下:
@Override
public long waitFor(final long sequence)
throws AlertException, InterruptedException, TimeoutException
{
//检查alert状态是否改变。如果alert了,则抛出异常,消费者线程执行结束
checkAlert(); //如果状态没有改变,继续根据后面的等待策略等待下一个可消费event的最大可用序号。
long availableSequence = waitStrategy.waitFor(sequence, cursorSequence, dependentSequence, this);
if (availableSequence < sequence)
{
return availableSequence;
}
return sequencer.getHighestPublishedSequence(sequence, availableSequence);
}
在具体的WaitStrategy中,会继续检查alert状态。以YieldWaitStrategy为例,其waitFor方法如下:
private int applyWaitMethod(final SequenceBarrier barrier, int counter)
throws AlertException
{
//判断是否在这一步骤时disruptor已经停止
barrier.checkAlert();
if (0 == counter)
{
Thread.yield();
}
else
{
--counter;
}
return counter;
}
在BatchEventProcessor消费的过程中,会多次检查alert状态。如果alert状态为true,则说明shutdown方法已经改变了该状态,程序需要停止。但如果shutdown线程先于消费者线程执行,则alert永远为false,消费者线程永远阻塞。
场景二、disruptor的shutdown过程先于生产者的生产过程执行。
package liuqiang.instance; import com.lmax.disruptor.EventFactory;
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.YieldingWaitStrategy;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.dsl.ProducerType; import java.util.concurrent.Executors; public class Main2 { public static void main(String[] args) throws Exception {
EventFactory<Order> factory = new OrderFactory();
int ringBufferSize = 1024 * 1024;
Disruptor<Order> disruptor =
new Disruptor<Order>(factory, ringBufferSize, Executors.defaultThreadFactory(), ProducerType.SINGLE, new YieldingWaitStrategy());
disruptor.handleEventsWith(new OrderHandler1("1"), new OrderHandler1("2"));
disruptor.start();
RingBuffer<Order> ringBuffer = disruptor.getRingBuffer();
//生产者单独通过一个线程进行生产
new Thread(new ProducerTask(ringBuffer)).start();
//要想disruptor可以正常的关闭,还需要消费者线程在执行该方法时,已经全部正常启动。
disruptor.shutdown();//关闭 disruptor,方法会堵塞,直至所有的事件都得到处理;
}
} class ProducerTask implements Runnable {
Producer producer;
public ProducerTask(RingBuffer<Order> ringBuffer) {
producer = new Producer(ringBuffer);
}
@Override
public void run() {
producer.onData("1");
System.out.println("producer event finished");
}
}
在这个例子中,我们将生产者的生产过程单独作为一个线程运行。
多次尝试之后,可能出现的结果如下:
输出结果1:(输出后执行结束)
producer event finished
输出结果2:(输出后程序不停止运行,三条打印信息的顺序可能不同)
producer event finished
OrderHandler1 2,消费信息:1
OrderHandler1 1,消费信息:1
输出结果3:(输出后程序停止运行,三条打印信息的顺序可能不同)
producer event finished
OrderHandler1 1,消费信息:1
OrderHandler1 2,消费信息:1
为何会出现三种不同的打印结果呢?
原因在于,这段程序的运行过程中,存在三个线程:生产者线程、shutdown线程、消费者线程。三个线程的执行顺序不同,会导致结果产生不同的效果。按照线程执行的顺序不同,如下我们分别进行分析:
1. 消费者线程->shutdown线程->生产者线程,输出结果1
原因在于,调用shutdown线程时,消费者线程已经在运行。而此时生产者线程尚未填充event数据,在执行hasBackLog判断时,会发现消费者无数据可消费,因此直接关掉消费者线程,结束shutdown调用。最终生产者线程执行,放入event数据到RingBuffer中,程序运行结束。
2. shutdown线程->生产者线程->消费者线程(或者,shutdown线程->消费者线程->生产者线程),输出结果2
调用shutdown线程会给正在运行的消费者线程设置alert,但由于消费者线程尚未开启,所以此步骤跳过。随后消费者线程启动,线程持续执行。无论生产者、消费者线程执行的顺序如何,消息都最终可以被消费(只是输出的信息顺序不同),但最终消费者阻塞在等待RingBuffer的过程上。
3. 生产者线程->消费者线程->shutdown线程,输出结果3
生产者先生产好数据放入ringBuffer,随后消费者线程开启,shutdown线程发现消费者线程尚未消费完所有数据时,会在hasBackLog方法上循环等待。最终,消费者线程消费完数据,shutdown关闭,程序正常结束。
4. 生产者线程->shutdown线程->消费者线程,输出结果2
生产者生产好数据放入ringbuffer,shutdown取出此时正在运行的依赖尾节点消费者集合。但由于消费者线程尚未启动,此操作无效。随后消费者线程启动,消费数据集并阻塞
5. 消费者线程->生产者线程->shutdown线程,输出结果3
消费者线程运行并等待数据,生产者线程生产数据,shutdown线程等待消费者线程消费完毕,并关闭消费者线程。程序正常结束。
总结
由上可见,disruptor.shutdown方法仅仅能关闭当前已经启动了的消费者线程,对于调用时尚未启动的消费者线程不起作用。在disruptor.shutdown如果能正确的关闭程序,需要满足两个条件:
1. 生产者的生产线程必须执行在disruptor.shutdown方法之前。
2. disruptor.shutdown方法必须执行在所有消费者线程启动之前。
在实际使用中,第二个条件产生的disruptor.shutdown失效问题也许并不常见。原因在于:线上环境中,生产者线程往往已经运行了一段时间,这段时间内,足够线程池调用所有的消费者线程并运行。但如果生产者运行的时间过短,导致shutdown提前调用在消费者线程启动之前,则会产生问题。
Disruptor中shutdown方法失效,及产生的不确定性源码分析的更多相关文章
- Flink中Periodic水印和Punctuated水印实现原理(源码分析)
在用户代码中,我们设置生成水印和事件时间的方法assignTimestampsAndWatermarks()中这里有个方法的重载 我们传入的对象分为两种 AssignerWithPunctuatedW ...
- Flink中发送端反压以及Credit机制(源码分析)
上一篇<Flink接收端反压机制>说到因为Flink每个Task的接收端和发送端是共享一个bufferPool的,形成了天然的反压机制,当Task接收数据的时候,接收端会根据积压的数据量以 ...
- Java中ArrayList源码分析
一.简介 ArrayList是一个数组队列,相当于动态数组.每个ArrayList实例都有自己的容量,该容量至少和所存储数据的个数一样大小,在每次添加数据时,它会使用ensureCapacity()保 ...
- Flink中Idle停滞流机制(源码分析)
前几天在社区群上,有人问了一个问题 既然上游最小水印会决定窗口触发,那如果我上游其中一条流突然没有了数据,我的窗口还会继续触发吗? 看到这个问题,我蒙了???? 对哈,因为我是选择上游所有流中水印最小 ...
- angular源码分析:angular中脏活累活的承担者之$interpolate
一.首先抛出两个问题 问题一:在angular中我们绑定数据最基本的方式是用两个大括号将$scope的变量包裹起来,那么如果想将大括号换成其他什么符号,比如换成[{与}],可不可以呢,如果可以在哪里配 ...
- jquery中Live方法不可用,Jquery中Live方法失效
jquery中Live方法不可用,Jquery中Live方法失效 >>>>>>>>>>>>>>>>> ...
- ABP源码分析十五:ABP中的实用扩展方法
类名 扩展的类型 方法名 参数 作用 XmlNodeExtensions XmlNode GetAttributeValueOrNull attributeName Gets an attribu ...
- 详解SpringMVC中Controller的方法中参数的工作原理[附带源码分析]
目录 前言 现象 源码分析 HandlerMethodArgumentResolver与HandlerMethodReturnValueHandler接口介绍 HandlerMethodArgumen ...
- 4 weekend110的textinputformat对切片规划的源码分析 + 倒排索引的mr实现 + 多个job在同一个main方法中提交
好的,现在,来weekend110的textinputformat对切片规划的源码分析, Inputformat默认是textinputformat,一通百通. 这就是今天,weekend110的te ...
随机推荐
- grep使用集合
一.grep使用 (一).选项 -a 不要忽略二进制数据. -A<显示列数> 除了显示符合范本样式的那一行之外,并显示该行之后的内容. -b 在显示符合范本样式的那一行之外,并显示该行之前 ...
- 二叉查找树(查找、插入、删除)——C语言
二叉查找树 二叉查找树(BST:Binary Search Tree)是一种特殊的二叉树,它改善了二叉树节点查找的效率.二叉查找树有以下性质: (1)若左子树不空,则左子树上所有节点的值均小于它的根节 ...
- 初试kafka消息队列中间件一 (只适合初学者哈)
初试kafka消息队列中间件一 今天闲来有点无聊,然后就看了一下关于消息中间件的资料, 简单一点的理解哈,网上都说的太高大上档次了,字面意思都想半天: 也就是用作消息通知,比如你想告诉某某你喜欢他,或 ...
- 又拍云叶靖:OpenResty 在又拍云存储中的应用
2019 年 7 月 6 日,OpenResty 社区联合又拍云,举办 OpenResty × Open Talk 全国巡回沙龙·上海站,又拍云平台开发部负责人叶靖在活动上做了<OpenRest ...
- Vue系列:为不同页面设置body背景颜色
由于SPA页面的特性,传统的设置 body 背景色的方法并不通用. 解决方案:利用组件内的路由实现 代码参考如下
- node 删除和复制文件或文件夹
[toc] 创建时间:2019-08-12 注意:在win10,v10.16.1 环境运行无问题 首先引入相关包(会在使用处具体说明): const fs = require('fs') const ...
- 【0802 | Day 7】Python进阶(一)
目 录 数字类型的内置方法 一.整型内置方法(int) 二.浮点型内置方法(float) 字符串类型内置方法 一.字符串类型内置方法(str) 二.常用操作和内置方法 优先掌握: 1.索引取值 2. ...
- 深入剖析PHP7内核源码(一)- PHP架构与生命周期
PHP7 为什么这么快? 全新的zval 更节约的空间,栈上分配内存 zend_string 存储字符串的Hash值,数组查询的时候不需要进行Hash计算 在HashTable桶内直接存数据,减少了内 ...
- Java String引起的常量池、String类型传参、“==”、“equals”、“hashCode”问题 细节分析
在学习javase的过程中,总是会遇到关于String的各种细节问题,而这些问题往往会出现在Java攻城狮面试中,今天想写一篇随笔,简单记录下我的一些想法.话不多说,直接进入正题. 1.String常 ...
- 12-Factor,构建原生软件应用方法论
官方地址:https://12factor.net/zh_cn/ 原则1:一份基准代码,多份部署 这个原则不管对微服务模式还是其他软件开发模式来说都非常基本,所以被列为12原则的第一条,该原则包括如下 ...