NLP相似度之tf-idf计算
当然,在学习过程中也是参考了很多其他的资料,代码都是一行一行敲出来的。
一、将多个文件合并成一个文件,避免频繁的打开和关闭
import sys for line in sys.stdin:
ss = line.strip().split('\t')
file_name = ss[0].strip()
file_context = ss[1].strip()
word_list = file_context.split(' ') word_set = set()
for word in word_list:
word_set.add(word) for word in word_set:
print '\t'.join([word, ''])
执行命令:就可以得到合并后的文件啦!!!
python convert.py input_tfidf_dir/ > merge_files.data
tf-idf计算流程图:
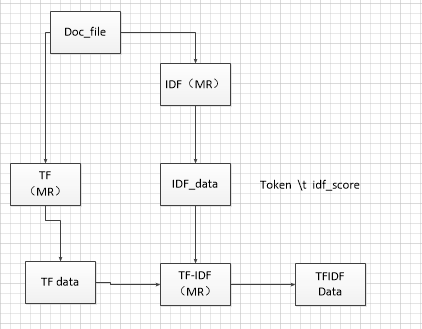
二 、计算IDF的值:
map阶段:读取每一行
import sys for line in sys.stdin:
ss = line.strip().split('\t')
file_name = ss[0].strip()
file_context = ss[1].strip()
word_list = file_context.split(' ') word_set = set()
for word in word_list:
word_set.add(word) for word in word_set:
print '\t'.join([word, ''])
reduce阶段:
import sys
import math current_word = None
doc_cnt = 508
count_pool = []
sum = 0 for line in sys.stdin:
ss = line.strip().split('\t')
if len(ss) != 2:
continue word, val = ss
if current_word == None:
current_word = word
if current_word != word:
for count in count_pool:
sum += count idf_score = math.log(float(doc_cnt) / (float(sum) + 1))
print '\t'.join([current_word, str(idf_score)]) current_word = word
count_pool = []
sum = 0 count_pool.append((int(val))) for count in count_pool:
sum += count idf_score = math.log(float(doc_cnt) / (float(sum) + 1))
print '\t'.join([current_word, str(idf_score)])
三、计算TF的值:
# 计算tf
# 读取合并后的数据
# 执行命令 cat merge_files.data | python map_tf.py mapper_func idf.data import sys word_dict = {}
idf_dict = {} # 读取计算的idf数据文件
def read_idf_file_func(idf_file_fd):
with open() as fd:
for line in fd:
ss = line.strip().split('\t')
if len(ss) != 2:
continue
token = ss[0].strip()
idf_score = ss[1].strip()
idf_dict[token] = float(idf_score)
return idf_dict # cat merge_files.data | python map_tf.py mapper_func
def mapper_func(idf_file_fd):
idf_dict = read_idf_file_func(idf_file_fd)
# 标准输入
for line in sys.stdin:
ss = line.strip().split('\t')
file_name = ss[0].strip()
file_context = ss[1].strip()
word_list = file_context.split(' ') for word in word_list:
if word not in word_dict:
word_dict[word] = 1
else:
word_dict[word] += 1 for k,v in word_dict.item():
if k not in idf_dict:
continue
print(file_name,k,v,idf_file_fd[k])
print(k,v) if __name__ == "__main__":
module = sys.modules[__name__]
func = getattr(module, sys.argv[1])
args = None
if len(sys.argv) > 1:
args = sys.argv[2:]
func(*args)
NLP相似度之tf-idf计算的更多相关文章
- TF/IDF(term frequency/inverse document frequency)
TF/IDF(term frequency/inverse document frequency) 的概念被公认为信息检索中最重要的发明. 一. TF/IDF描述单个term与特定document的相 ...
- TF/IDF计算方法
FROM:http://blog.csdn.net/pennyliang/article/details/1231028 我们已经谈过了如何自动下载网页.如何建立索引.如何衡量网页的质量(Page R ...
- 信息检索中的TF/IDF概念与算法的解释
https://blog.csdn.net/class_brick/article/details/79135909 概念 TF-IDF(term frequency–inverse document ...
- Elasticsearch由浅入深(十)搜索引擎:相关度评分 TF&IDF算法、doc value正排索引、解密query、fetch phrase原理、Bouncing Results问题、基于scoll技术滚动搜索大量数据
相关度评分 TF&IDF算法 Elasticsearch的相关度评分(relevance score)算法采用的是term frequency/inverse document frequen ...
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
- 文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型.回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示.首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的 ...
- Elasticsearch学习之相关度评分TF&IDF
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度 Elasticsearch使用的是 term frequency/inverse doc ...
- tf idf公式及sklearn中TfidfVectorizer
在文本挖掘预处理之向量化与Hash Trick中我们讲到在文本挖掘的预处理中,向量化之后一般都伴随着TF-IDF的处理,那么什么是TF-IDF,为什么一般我们要加这一步预处理呢?这里就对TF-IDF的 ...
- 25.TF&IDF算法以及向量空间模型算法
主要知识点: boolean model IF/IDF vector space model 一.boolean model 在es做各种搜索进行打分排序时,会先用boolean mo ...
随机推荐
- C# interface 的隐式与显示实现及适应范围源码演示
把代码过程中经常用到的一些代码段做个记录,如下的资料是关于C# interface 的隐式与显示实现及适应范围演示的代码. interface IAnimal { void Dog(); } clas ...
- SVN-Failed to run the WC DB work queue associated with
解决方法:清空svn的队列 1.下载sqlite3.exe 2.找到你项目的.svn文件,查看是否存在wc.db 3.将sqlite3.exe放到.svn的同级目录 4.启动cmd执行sqlite3 ...
- Gerapy 安装
1下载: pip install gerapy 2. 在D盘中新建一个文件夹,该然后cd 到该文件夹中,执行: gerapy init # 初始化,可以在任意路径下进行 cd gerapy # 初始化 ...
- vue中<select>绑定事件
<div id="app"> <select v-model="selectItem" @change="selectFn($eve ...
- 空list赋值
list=[] i =0 list[i] =1 Traceback (most recent call last): File "D:\ProgramData\Anaconda3\lib\s ...
- 脚本语言 ES
C# 编写,解释执行,语法类似 JS,动态类型,支持闭包,支持热更新,效率比较低,目前暂时没有发现 BUG,实际游戏运行稳定,没有发现内存泄漏 Github:https://github.com/ea ...
- 洛谷1855 榨取kkksc03
题目描述 洛谷2的团队功能是其他任何oj和工具难以达到的.借助洛谷强大的服务器资源,任何学校都可以在洛谷上零成本的搭建oj并高效率的完成训练计划. 为什么说是搭建oj呢?为什么高效呢? 因为,你可以上 ...
- 设计模式之Factory模式(C++)
Factory模式具有两大重要的功能: (1).定义创建对象的接口,封装了对象的创建: (2).使具体化类工作延迟到了子类中. //Product.h #ifndef _PRODUCT_H_ #def ...
- css三种基本选着器
<!DOCTYPE html><html> <head> <meta charset="utf-8" /> <title> ...
- WPF listbox实现多列显示数据
一.每行显示固定列数 <ListBox ItemsSource="{Binding DataList}" Style="{DynamicResource ListB ...