MapReduce-CombineTextInputFormat 切片机制
MapReduce 框架默认的 TextInputFormat 切片机制是对任务按文件规划切片,如果有大量小文件,就会产生大量的 MapTask,处理小文件效率非常低。
CombineTextInputFormat:用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个 MapTask 处理。
CombineTextInputFormat 切片机制过程包括:虚拟存储过程和切片过程二部分 假设 setMaxInputSplitSize 值为 4M,有如下四个文件
a.txt 1.7M
b.txt 5.1M
c.txt 3.4M
d.txt 6.8M (1)虚拟存储过程
(1.1)将输入目录下所有文件大小,依次和设置的 setMaxInputSplitSize 值比较,如果不大于设置的最大值,逻辑上划分一个块。
(1.2)如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块,当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)。
1.7M < 4M 划分一块
5.1M > 4M 但是小于 2*4M 划分二块:块1=2.55M,块2=2.55M
3.4M < 4M 划分一块
6.8M > 4M 但是小于 2*4M 划分二块:块1=3.4M,块2=3.4M
最终存储的文件:
1.7M
2.55M,2.55M
3.4M
3.4M,3.4M (2)切片过程
(2.1)判断虚拟存储的文件大小是否大于 setlMaxIputSplitSize 值,大于等于则单独形成一个切片。
(2.2)如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
最终会形成3个切片:
(1.7+2.55)M,(2.55+3.4)M,(34+3.4)M
测试读取数据的方式

控制台日志

可以看到读取方式与 TextInputFormat 一样,k 为偏移量,v 为一行的值,按行读取
以 WordCount 为例进行测试,测试切片数
测试数据
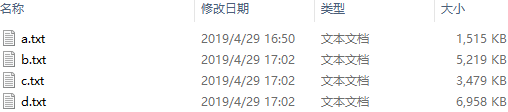
测试代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.log4j.BasicConfigurator; import java.io.IOException;
import java.util.StringTokenizer; public class WordCount { static {
try {
// 设置 HADOOP_HOME 环境变量
System.setProperty("hadoop.home.dir", "D:/DevelopTools/hadoop-2.9.2/");
// 日志初始化
BasicConfigurator.configure();
// 加载库文件
System.load("D:/DevelopTools/hadoop-2.9.2/bin/hadoop.dll");
} catch (UnsatisfiedLinkError e) {
System.err.println("Native code library failed to load.\n" + e);
System.exit(1);
}
} public static void main(String[] args) throws Exception {
args = new String[]{"D:\\tmp\\input", "D:\\tmp\\456"};
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); // 设置 InputFormat,默认为 TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);
// 设置最大值即可 128M
CombineTextInputFormat.setMaxInputSplitSize(job, 1024 * 1024 * 128); FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
} public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); @Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// 查看 k-v
// System.out.println(key + "\t" + value);
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable(); @Override
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
}
由于所有文件加起来大小都没有 128M,所以切片数为 1

MapReduce-CombineTextInputFormat 切片机制的更多相关文章
- Hadoop(14)-MapReduce框架原理-切片机制
1.FileInputFormat切片机制 切片机制 比如一个文件夹下有5个小文件,切片时会切5个片,而不是一个片 案例分析 2.FileInputFormat切片大小的参数配置 源码中计算切片大小的 ...
- MapReduce-TextInputFormat 切片机制
MapReduce 默认使用 TextInputFormat 进行切片,其机制如下 (1)简单地按照文件的内容长度进行切片 (2)切片大小,默认等于Block大小,可单独设置 (3)切片时不考虑数据集 ...
- 【大数据】MapTask并行度和切片机制
一. MapTask并行度决定机制 maptask的并行度决定map阶段的任务处理并发度,进而影响到整个job的处理速度 那么,mapTask并行实例是否越多越好呢?其并行度又是如何决定呢? 1.1 ...
- MapReduce中作业调度机制
MapReduce中作业调度机制主要有3种: 1.先入先出FIFO Hadoop 中默认的调度器,它先按照作业的优先级高低,再按照到达时间的先后选择被执行的作业. 2.公平调度器(相当于时间 ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- 经典MapReduce作业和Yarn上MapReduce作业运行机制
一.经典MapReduce的作业运行机制 如下图是经典MapReduce作业的工作原理: 1.1 经典MapReduce作业的实体 经典MapReduce作业运行过程包含的实体: 客户端,提交MapR ...
- MapReduce 切片机制源码分析
总体来说大概有以下2个大的步骤 1.连接集群(yarnrunner或者是localjobrunner) 2.submitter.submitJobInternal()在该方法中会创建提交路径,计算切片 ...
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- hadoop MapReduce Yarn运行机制
原 Hadoop MapReduce 框架的问题 原hadoop的MapReduce框架图 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 首先用户程序 (JobClient) ...
随机推荐
- 华为6.0系统设备最完美激活Xposed框架的经验
对于喜欢玩手机的伙伴而言,经常会使用上Xposed框架及种种功能强大的模块,对于5.0以下的系统版本,只要手机能获得root权限,安装和激活Xposed框架是非常轻松的,但随着系统版本的迭代,5.0以 ...
- 解决laravel Class 'Doctrine\DBAL\Driver\PDOMySql\Driver' not found 错误
这个错误的原因来自于没有安装一个依赖库: 官方文档说明如下: Modifying Columns Prerequisites Before modifying a column, be sure to ...
- win10下安装mysql5.7.25版本
之前使用mysql都是使用的xampp上面集成的mysql,也在安装过5.6.35的版本,好像都是下一步下一步就完成了,昨天安装了一个5.7.25的版本的mysql,也不知道怎么了,就开始百度一些东西 ...
- 轻松学习UML之类图,状态图
本文主要讲解UML图中的类图与状态图相关内容,如有不足之处,还请指正. 概述 统一建模语言(UML,UnifiedModelingLanguage)是面向对象软件的标准化建模语言,UML因其简单.统一 ...
- mysql 高级
Sql优化: 1.SELECT语句中避免使用 *, 尽量根据业务需求按字段进行查询 举例:如果表中有个字段用的是clob或者是blob这种大数据字段的话, 他们的查询应该根据业务需要来进行指定字段的查 ...
- DotNetCore + Sonar + Coverlet 代码覆盖率检查
一,下载 sonar-scanner-msbuild 我当前下载的最新版本是:sonar-scanner-msbuild-4.5.0.1761-netcoreapp2.0 https://docs.s ...
- IP包头结构详解
版本号(Version):长度4比特.标识目前采用的IP协议的版本号.一般的值为0100(IPv4),0110(IPv6) IP包头长度(Header Length):长度4比特.这个字段的作用是为了 ...
- C#之事件与eventArgs
static void Main(string[] args) { MyText myText = new MyText(); myTe ...
- java中的“空格”用trim()无法去除?原来是这样!
原因: 从txt文件中读取一些数据导入mysql数据库,导入数据库之后发现有一个字段的前面有两个“空格”,后来在代码里我尝试用trim().replace()等方法去除,发现怎么也去不掉,于是我将字符 ...
- Docker 核心技术之容器与镜像
Docker容器与镜像的关系 容器提交 – docker commit docker commit -h 作用: 根据容器生成一个新的镜像 命令格式: docker commit [OPTIONS] ...