Selenium及Headless Chrome抓取动态HTML页面
一般的的静态HTML页面可以使用requests等库直接抓取,但还有一部分比较复杂的动态页面,这些页面的DOM是动态生成的,有些还需要用户与其点击互动,这些页面只能使用真实的浏览器引擎动态解析,Selenium和Chrome Headless可以很好的达到这种目的。
Headless Chrome
Headless Chrome 是 Chrome 浏览器的无界面形态,可以在不打开浏览器的前提下,使用所有Chrome支持的特性,在命令行中运行你的脚本。以前在爬虫要使用Phantomjs来实现这些功能,但Phantomjs已经暂停开发,现在可以使用Headless Chrome来代替。
使用很简单,保证chrome命令指向chrome浏览器的安装路径,ubuntu下为google-chrome。
输出html:
google-chrome --headless --dump-dom https://www.cnblogs.com/
将目标页面截图:
google-chrome --headless --disable-gpu --screenshot https://www.cnblogs.com/
# 规定大小
google-chrome --headless --disable-gpu --screenshot --window-size=640,960 https://www.cnblogs.com/
保存为pdf:
google-chrome --headless --disable-gpu --print-to-pdf https://www.cnblogs.com/
以上文件会保存于当前目录。
还可以使用--remote-debugging-port参数进行远程调试:
google-chrome --headless --disable-gpu --no-sandbox --remote-debugging-port=9222 --user-data-dir='/d/cnblogs' http://www.cnblogs.com
--user-data-dir参数可以设定保存目录,--user-agent参数可以设定请求agent。上述的命令打开了一个websocket调试接口对当前Tab内页面的DOM、网络、性能、存储等等进行调试。
打开http://127.0.0.1:9222/链接可以看到可检查的网页,可以点击它们并看到使用了哪种Headless渲染。
还有一系列地址:
http://127.0.0.1:9222/json 查看已经打开的Tab列表:
[ {
"description": "",
"devtoolsFrontendUrl": "/devtools/inspector.html?ws=127.0.0.1:9222/devtools/page/5C7774203404DC082182AF4563CC7256",
"id": "5C7774203404DC082182AF4563CC7256",
"title": "博客园 - 代码改变世界",
"type": "page",
"url": "https://www.cnblogs.com/",
"webSocketDebuggerUrl": "ws://127.0.0.1:9222/devtools/page/5C7774203404DC082182AF4563CC7256"
} ]
http://127.0.0.1:9222/json/version : 查看浏览器版本信息
{
"Browser": "HeadlessChrome/71.0.3578.98",
"Protocol-Version": "1.3",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/71.0.3578.98 Safari/537.36",
"V8-Version": "7.1.302.31",
"WebKit-Version": "537.36 (@15234034d19b85dcd9a03b164ae89d04145d8368)",
"webSocketDebuggerUrl": "ws://127.0.0.1:9222/devtools/browser/ed156c0d-805c-4849-99d0-02e454260c17"
}
http://127.0.0.1:9222/json/new?http://www.baidu.com : 新开Tab打开指定地址
http://127.0.0.1:9222/json/close/8795FFF09B01BD41B1F2931110475A67 : 关闭指定Tab,close后为tab页面的id
http://127.0.0.1:9222/json/activate/5C7774203404DC082182AF4563CC7256 : 切换到目标Tab
tab页面信息中有一个devtoolsFrontendUrl,是开发者工具的前端地址,可以打开:
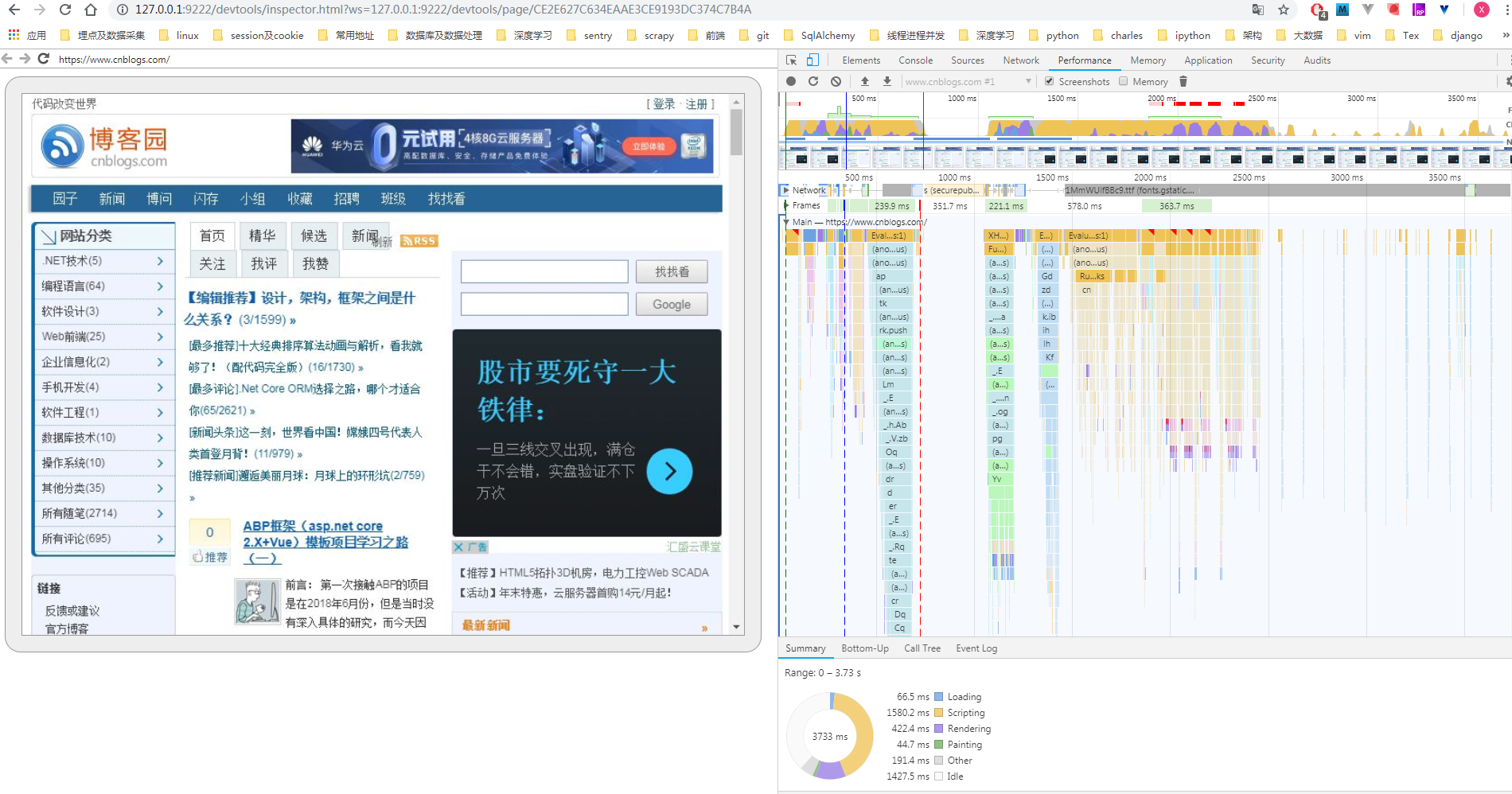
http://127.0.0.1:9222/devtools/inspector.html?ws=127.0.0.1:9222/devtools/page/CE2E627C634EAAE3CE9193DC374C7B4A
在开发者工具里切换到Performance,勾选Screenshots,点刷新图标,重新加载完成就可以看到逐帧加载的截图:
Selenium
Selenium 是用于测试 Web 应用程序用户界面的常用框架,它支持各种浏览器,包括 Chrome,Safari,Firefox 等,支持多种语言开发,比如 Java,C,Ruby等等,当然也有Python。
pip install selenium
使用时还需要下载浏览器驱动,以chromedriver为例,下载地址:
国内镜像:
下载时注意与电脑的chrome版本保持一致,然后将chromedriver置于环境变量之中。
打开一个淘宝商品网页:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://market.m.taobao.com/app/dinamic/h5-tb-detail/index.html?id=568217064643')
浏览器会自动打开并访问网页。
使用headless模式:
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
browser = webdriver.Chrome(options=chrome_options)
browser.get('https://market.m.taobao.com/app/dinamic/h5-tb-detail/index.html?id=568217064643')
data = browser.page_source
page_souce属性可以获取html网页源码。
可以看到获取的源码都是些js与css语句,dom并未生成,需要模拟浏览器滚动来生成dom:
for i in range(1, 11):
browser.execute_script(
"window.scrollTo(0, document.body.scrollHeight/10*%s);" % i
)
time.sleep(0.5)
execute_script方法可以用来执行js脚本。
现在获取的源码基本是完整的,还存在一些小问题,比如网页为了让img延迟加载,img的地址是放在data-img属性上的,等到浏览器滑动至图片时才修改src属性,可以使用pyquery修改:
import time from selenium import webdriver
from pyquery import PyQuery as pq base_dir = os.path.dirname(__file__)
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
browser = webdriver.Chrome(options=chrome_options)
# browser.implicitly_wait(10)
browser.get('https://market.m.taobao.com/app/dinamic/h5-tb-detail/index.html?id=568217064643')
for i in range(1, 11):
browser.execute_script(
"window.scrollTo(0, document.body.scrollHeight/10*%s);" % i
)
time.sleep(0.5)
data = browser.page_source.encode('utf-8')
doc = pq(data)
for img in doc('img'):
img = pq(img)
if img.attr['data-img']:
img.attr.src = img.attr['data-img']
data = doc.html(method='html').replace('src="//', 'src="http://')
f = open(os.path.join(base_dir, 'detail.html'), 'w')
f.write(data.encode('utf-8'))
f.close()
保存为html后打开可以看到网页爬取成功。
selenium还提供了很多element提取接口:
提取单个element:
elem = browser.find_element_by_id("description")
提取多个:
elem = browser.find_elements_by_class_name("detail-desc")
批量爬取
可以使用concurrent.futures 线程池进行多线程批量爬取:
# -*- coding: utf-8 -*-
import threading
import time
import os from concurrent.futures import ThreadPoolExecutor, as_completed
from pyquery import PyQuery as pq class TaobaoCrawler(object):
def __init__(self, ids):
self.ids = ids
self.browsers = {}
self.timeout_spus = []
self.url = 'https://market.m.taobao.com/app/dinamic/h5-tb-detail/index.html?id=' def _create_new_browser(self):
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# chrome_options.add_argument('--blink-settings=imagesEnabled=false')
browser = webdriver.Chrome(options=chrome_options)
return browser def get_browser(self):
current_thread_id = threading.currentThread().ident
existed = self.browsers.get(current_thread_id)
if existed:
return existed
new_browser = self._create_new_browser()
self.browsers[current_thread_id] = new_browser
return new_browser def close_browsers(self):
for _, browser in self.browsers.iteritems():
browser.quit()
self.browsers = {} def scroll_browser(self, browser, num):
'''模拟浏览器滚动 保证js全部执行完成'''
for i in range(1, num+1):
browser.execute_script(
"window.scrollTo(0, document.body.scrollHeight/%d*%d);" % (
num, i)
)
time.sleep(0.5) def handle_detail_doc(self, detail):
doc = pq(detail)
for img in doc('img'):
img = pq(img)
if img.attr['data-img']:
img.attr.src = img.attr['data-img']
detail = doc.html(method='html')
detail = detail.replace('src="//', 'src="http://')
return detail def crawl_taobao_detail(self, taobao_id):
browser = self.get_browser()
url = self.url + str(taobao_id)
browser.execute_script("window.stop();")
browser.get(url)
self.scroll_browser(browser, 20)
data = browser.page_source.encode('utf-8')
data = self.handle_detail_doc(data)
return taobao_id, data def start_crawl(self):
if not self.ids:
return
with ThreadPoolExecutor(max_workers=4) as executor:
futures = [executor.submit(self.crawl_taobao_detail, _)
for _ in self.ids]
for task in as_completed(futures):
if task.done():
taobao_id, data = task.result()
base_dir = os.path.dirname(__file__)
f = open(os.path.join(base_dir, str(taobao_id) + '.html'), 'w')
f.write(data.encode('utf-8'))
f.close()
self.close_browsers() def test_crawl():
ids = [568217064643, 584126060993, 581555053584, 581002124614]
c = TaobaoCrawler(ids)
c.start_crawl() if __name__ == '__main__':
test_crawl()
Selenium及Headless Chrome抓取动态HTML页面的更多相关文章
- 爬虫(三)通过Selenium + Headless Chrome爬取动态网页
一.Selenium Selenium是一个用于Web应用程序测试的工具,它可以在各种浏览器中运行,包括Chrome,Safari,Firefox 等主流界面式浏览器. 我们可以直接用pip inst ...
- selenium抓取动态网页数据
1.selenium抓取动态网页数据基础介绍 1.1 什么是AJAX AJAX(Asynchronouse JavaScript And XML:异步JavaScript和XML)通过在后台与服务器进 ...
- 爬虫(四)Selenium + Headless Chrome爬取Bing图片搜索结果
Bing图片搜索结果是动态加载的,如果我们直接用requests去访问页面爬取数据,那我们只能拿到很少的图片.所以我们使用Selenium + Headless Chrome来爬取搜索结果.在开始前, ...
- scrapy和selenium结合抓取动态网页
1.安装python (我用的是2.7版本的) 2.安装scrapy: 详情请参考 http://blog.csdn.net/wukaibo1986/article/details/8167590 ...
- selenium使用chrome抓取自动消失弹框的方法
selenium使用chrome抓取自动消失弹框的方法 转:https://blog.csdn.net/kennin19840715/article/details/76512394
- 使用scrapy-selenium, chrome-headless抓取动态网页
在使用scrapy抓取网页时, 如果遇到使用js动态渲染的页面, 将无法提取到在浏览器中看到的内容. 针对这个问题scrapy官方给出的方案是scrapy-selenium, 这是一个把sel ...
- 【转】详解抓取网站,模拟登陆,抓取动态网页的原理和实现(Python,C#等)
转自:http://www.crifan.com/files/doc/docbook/web_scrape_emulate_login/release/html/web_scrape_emulate_ ...
- java抓取动态生成的网页
最近在做项目的时候有一个需求:从网页面抓取数据,要求是首先抓取整个网页的html源码(后期更新要使用到).刚开始一看这个简单,然后就稀里哗啦的敲起了代码(在这之前使用过Hadoop平台的分布式爬虫框架 ...
- 手把手视频:万能开源Hawk抓取动态网站
Hawk是沙漠之鹰历时五年开发的开源免费网页抓取工具(爬虫),无需编程,全部可视化. 自从上次发布Hawk 2.0过了小半年,可是还是有不少朋友通过邮件或者微信的方式询问如何使用.看文档还是不如视频教 ...
随机推荐
- 关于javascript中的变量对象和活动对象
https://segmentfault.com/a/1190000010339180 https://zhuanlan.zhihu.com/p/26011572 https://www.cnblog ...
- day24:继承
1,复习1 # 面向对象编程 # 思想:角色的抽象,创建类,创建角色(实例化),操作这些示例 # 面向对象的关键字 class 类名: 静态属性 = 'aaa' def __init__(self): ...
- oracle根据某个字段的值进行排序
需求:按照颜色为蓝色.红色.黄色进行排序: order by case when color = '蓝色' then 1 ...
- L1-039. 古风排版
L1-039. 古风排版 中国的古人写文字,是从右向左竖向排版的.本题就请你编写程序,把一段文字按古风排版. 输入格式: 输入在第一行给出一个正整数N(<100),是每一列的字符数.第二行给出一 ...
- Python3学习之路~7.3 反射
python中的反射功能是由以下四个内置函数提供:hasattr.getattr.setattr.delattr,该四个函数分别用于对对象内部执行:检查是否含有某成员.获取成员.设置成员.删除成员. ...
- STM32F103驱动GT911
0x00 引脚连接: // SCL-------PB10 // SDA-------PB11 // INT--------PB1 // RST--------PB2 IIC的SCL与SDA需要接上拉电 ...
- kafka笔记9(监控)
Kafka提供的所有度量指标都是通过JMX(Java Management Extensions)接口访问 JMX端口查询: zookeeper上获取端口信息 /brokers/ids/<I ...
- linux----------linux下安装rar和unrar命令
1.wget http://www.rarlab.com/rar/rarlinux-x64-4.2.0.tar.gz 2.tar xf rarlinux-x64-4.2.0.tar.gz 解压下 ...
- iframe子页面与父页面元素的访问以及js变量的访问
1.子页面访问父页面元素 parent.document.getElementById('id')和document相关的方法都可以这样用 2.父页面访问子页面元素 document.getEle ...
- puppeteer(五)chrome启动参数列表API
List of Chromium Command Line Switches https://peter.sh/experiments/chromium-command-line-switches/ ...