Scrapyd
scrapyd
安装
scrapyd-中心节点,子节点安装scrapyd-client
pip3 install scrapyd
pip3 install scrapyd-client

scrapyd-client两个作用
把本地的代码打包生成egg包
把egg上传到远程的服务器上
windows配置scrapyd-deploy
H:\Python36\Scripts下创建scrapyd-deploy.bat
python H:/Python36/Scripts/scrapyd-deploy %*
curl.exe放入H:\Python36\Scripts
启动scrapyd启动服务!!!!!!!!!!
scrapyd-deploy 查询
切换到scrapy中cmd运行scrapyd-deploy
H:\DDD-scrapy\douban>scrapyd-deploy
scrapyd-deploy -l

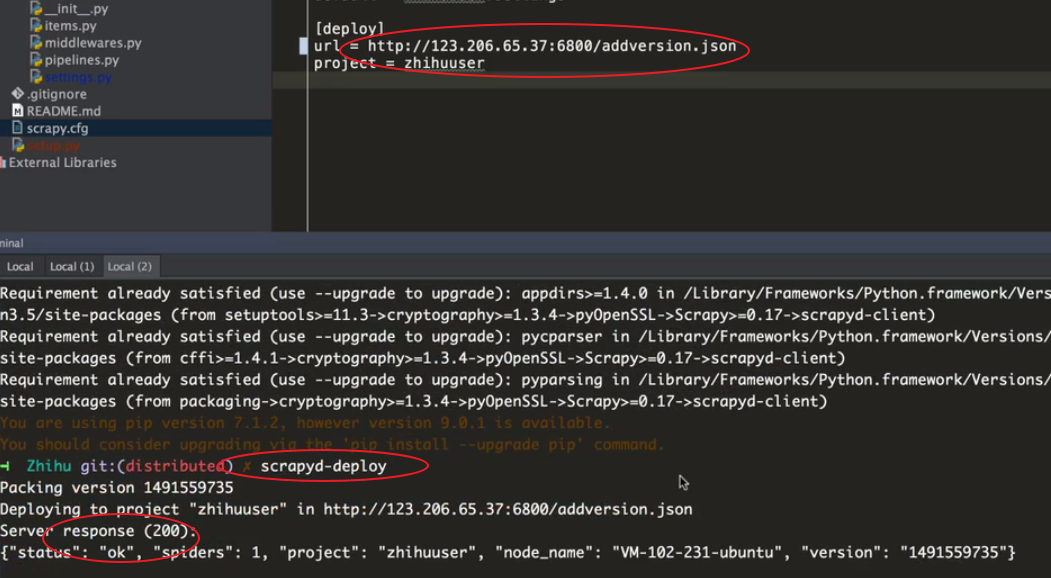
scrapy中scrapy.cfg修改配置
[deploy:dj] #开发项目名
url = http://localhost:6800/
project = douban #项目名
scrapy list这个命令确认可用,结果dang是spider名

如不可用,setting中添加以下

scrapyd-deploy 添加爬虫
scrapyd-deploy dj -p douban
H:/Python36/Scripts/scrapyd-deploy dang1 -p dangdang
dang1是开发项目名,dangdang是项目名

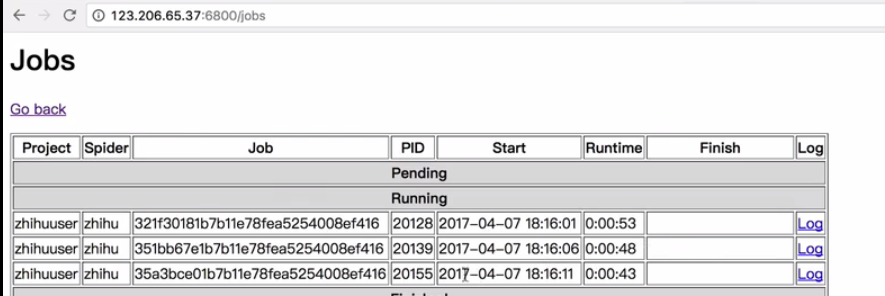
http://127.0.0.1:6800/jobs
scrapyd 当前项目的状态
curl http://localhost:6800/daemonstatus.json

curl启动爬虫
curl http://localhost:6800/schedule.json -d project=dangdang -d spider=dang
dangdang是项目名,dang是爬虫名

project=douban,spider=doubanlogin
curl http://localhost:6800/schedule.json -d project=douban -d spider=doubanlogin


远程部署:scrapyd-deploy
scrapyd-deploy 17k -p my17k
列出所有已经上传的spider
curl http://47.97.169.234:6800/listprojects.json

列出当前项目project的版本version
curl http://47.97.169.234:6800/listversions.json\?project\=my17k

远程启动spider
curl http://47.97.169.234:6800/schedule.json -d project=my17k-d spider=mys1

运行三次,就类似于开启三个进程
curl http://47.97.169.234:6800/schedule.json -d project=my17k-d spider=mys1

查看当前项目的运行情况

取消爬虫项目的job任务
curl http://localhost:6800/cancel.json -d project=dangdang -d job=68d25db0506111e9a4c0e2df1c2eb35b
curl http://47.97.169.234:6800/cancel.json -d project=my17k -d job=be6ed036508611e9b68000163e08dec9

centos配置scrapyd
https://www.cnblogs.com/ss-py/p/9661928.html
安装后新建一个配置文件:
sudo mkdir /etc/scrapyd
sudo vim /etc/scrapyd/scrapyd.conf
写入如下内容:(给内容在https://scrapyd.readthedocs.io/en/stable/config.html可找到)
[scrapyd]
eggs_dir = eggs
logs_dir = logs
items_dir =
jobs_to_keep = 5
dbs_dir = dbs
max_proc = 0
max_proc_per_cpu = 10
finished_to_keep = 100
poll_interval = 5.0
bind_address = 0.0.0.0
http_port = 6800
debug = off
runner = scrapyd.runner
application = scrapyd.app.application
launcher = scrapyd.launcher.Launcher
webroot = scrapyd.website.Root [services]
schedule.json = scrapyd.webservice.Schedule
cancel.json = scrapyd.webservice.Cancel
addversion.json = scrapyd.webservice.AddVersion
listprojects.json = scrapyd.webservice.ListProjects
listversions.json = scrapyd.webservice.ListVersions
listspiders.json = scrapyd.webservice.ListSpiders
delproject.json = scrapyd.webservice.DeleteProject
delversion.json = scrapyd.webservice.DeleteVersion
listjobs.json = scrapyd.webservice.ListJobs
daemonstatus.json = scrapyd.webservice.DaemonStatus
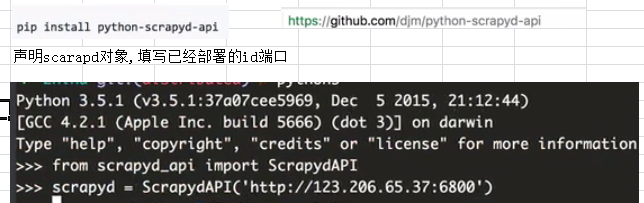
scrapyd-api
安装
scrapyd-api对scrapyd进行了一些封装
from scrapyd_api import ScrapydAPI
scrapyd=ScrapydAPI('http://47.97.169.234:6800')
使用
显示所有的projects
scrapyd.list_projects()

显示该项目下的spiders
scrapyd.list_spiders('my17k')

from scrapyd_api import ScrapydAPI
scrapyd=ScrapydAPI('http://47.97.169.234:6800')
print(scrapyd.list_projects()) #查询项目名
print(scrapyd.list_spiders('my17k')) #查询该项目名下的爬虫名
Scrapyd的更多相关文章
- scrapy的scrapyd使用方法
一直以来,很多人疑惑scrapy提供的scrapyd该怎么用,于我也是.自己在实际项目中只是使用scrapy crawl spider,用python来写一个多进程启动,还用一个shell脚本来监控进 ...
- 如何将Scrapy 部署到Scrapyd上?
安装上传工具 1.上传工具 scrapyd-client 2.安装方法: pip install scrapyd-client 3.上传方法: python d:\Python27\Scripts\s ...
- 如何部署Scrapy 到Scrapyd上?
安装上传工具 1.上传工具 scrapyd-client 2.安装方法: pip install scrapyd-client 3.上传方法: python d:\Python27\Scripts\s ...
- Scrapyd部署爬虫
Scrapyd部署爬虫 准备工作 安装scrapyd: pip install scrapyd 安装scrapyd-client : pip install scrapyd-client 安装curl ...
- 芝麻HTTP:Scrapyd的安装
Scrapyd是一个用于部署和运行Scrapy项目的工具,有了它,你可以将写好的Scrapy项目上传到云主机并通过API来控制它的运行. 既然是Scrapy项目部署,基本上都使用Linux主机,所以本 ...
- Scrapyd日志输出优化
现在维护着一个新浪微博爬虫,爬取量已经5亿+,使用了Scrapyd部署分布式. Scrapyd运行时会输出日志到本地,导致日志文件会越来越大,这个其实就是Scrapy控制台的输出.但是这个日志其实有用 ...
- Scrapy+Scrapy-redis+Scrapyd+Gerapy 分布式爬虫框架整合
简介:给正在学习的小伙伴们分享一下自己的感悟,如有理解不正确的地方,望指出,感谢~ 首先介绍一下这个标题吧~ 1. Scrapy:是一个基于Twisted的异步IO框架,有了这个框架,我们就不需要等待 ...
- Scrapyd 改进第二步: Web Interface 添加 STOP 和 START 超链接, 一键调用 Scrapyd API
0.提出问题 Scrapyd 提供的开始和结束项目的API如下,参考 Scrapyd 改进第一步: Web Interface 添加 charset=UTF-8, 避免查看 log 出现中文乱码,准备 ...
- Scrapyd 改进第一步: Web Interface 添加 charset=UTF-8, 避免查看 log 出现中文乱码
0.问题现象和原因 如下图所示,由于 Scrapyd 的 Web Interface 的 log 链接直接指向 log 文件,Response Headers 的 Content-Type 又没有声明 ...
随机推荐
- 【Swift 3.1】iOS开发笔记(四)
一.唱片旋转效果(360°无限顺时针旋转) func animationRotateCover() { coverImageView.layer.removeAllAnimations() let a ...
- 使用Github生成燃尽图
经过一晚上折腾,终于算是把linux上成功生成了我们团队项目的燃尽图,效果还是不错,在过程中又发现了另一种生成燃尽图的方式,也是基于一个开源项目. 1.准备: 首先你的项目一定要有milestone. ...
- 【学习总结】Git学习-GIT工作流-千峰教育(来自B站)
Git工作流指南 - av32575602 文档资料 目录: 1-什么是版本控制系统 2-工作流简介 3-集中式工作流 4-功能分支工作流 5-GitFlow工作流 小记: 初看差点放弃了,不过后面还 ...
- windows平台上用python 远程线程注入,执行shellcode
// 转自: https://blog.csdn.net/Jailman/article/details/77573990import sys import psutil import ctypes ...
- Bean的自动装配
再说自动装配之前,我们先聊一聊什么是手动装配. 手动装配就是我们在先前讲的那些,要自己给定属性,然后赋值 Spring IOC容器可以自动装配Bean,需要做的仅仅实在<bean>的aut ...
- 第四章· Redis的事务、锁及管理命令
一.事务介绍 二.Redis乐观锁介绍 三.Redis管理命令 一.事务介绍 Redis的事务与关系型数据库中的事务区别 1)在MySQL中讲过的事务,具有A.C.I.D四个特性 Atomic(原子性 ...
- Python量化交易
资料整理: 1.python量化的一个github 代码 2.原理 + python基础 讲解 3.目前发现不错的两个量化交易 学习平台: 聚宽和优矿在量化交易都是在15年线上布局的,聚宽是15年的新 ...
- [NOIp2016] 换教室
题目类型:期望\(DP\) 传送门:>Here< 题意:现有\(N\)个时间段,每个时间段上一节课.如果不申请换教室,那么时间段\(i\)必须去教室\(c[i]\)上课,如果申请换课成功, ...
- Magento Meigee-Glam 主题的用法
Start起点 Package Structure包装结构 License许可证 Installation安装 What's new Updated!更新了什么! Theme options主题选项 ...
- [https]公司导入自签名证书实现https监控
https://www.v2ex.com/t/143012