JAVA-HashMap实现原理
一、HashMap实现原理
1. HashMap概述
HashMap是基于哈希表的Map接口的非同步实现。它允许存入null值和null键。它不保证存入元素的顺序与操作顺序一致,主要是不保证元素的顺序永恒不变。
HashMap底层的数据结构是一个“链表散列“的数据结构,即数组和链表的结合体。
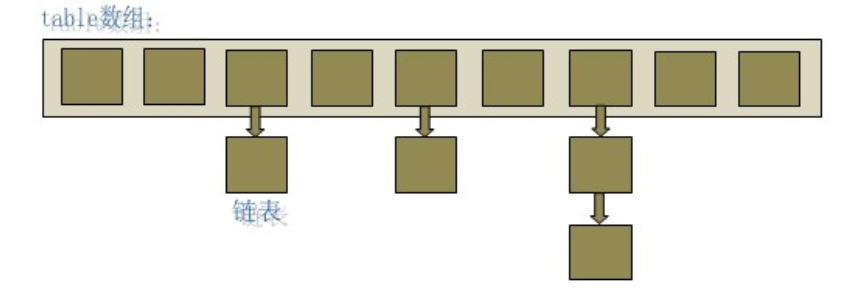
从上图中可以看出,HashMap底层就是一个数组,数组的每一个位置上又是一个链表。
2.底层代码分析
HashMap<String,Object> map = new HashMap<String,Object>();//当我们创建一个HashMap的时候,会产生哪些操作?
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
{ /**
* 初始化容量-16
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; static final int MAXIMUM_CAPACITY = 1 << 30; static final float DEFAULT_LOAD_FACTOR = 0.75f; /**
* 一个空的Entry数组
*/
static final Entry<?,?>[] EMPTY_TABLE = {}; /**
* 存储元素的数组,自动扩容
*/
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
/**
* 键值对
*/
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash; /**
* 初始化方法
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
} /** * 1.初始化方法 */
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
/** * 2.初始化方法 */
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor); this.loadFactor = loadFactor;
threshold = initialCapacity;
init();
} }
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{ private static final long serialVersionUID = 3801124242820219131L; /**
* 双重链表的一个第一个元素
*/
private transient Entry<K,V> header;
/** * 3.初始化方法 */
@Override
void init() {
header = new Entry<>(-1, null, null, null);
header.before = header.after = header;
} /**
* LinkedHashMap 中的entry继承了hashMap中的entry
*/
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
/** * 4.初始化方法 */
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
} }
通过 hashMap中的成员变量Entry<K,V>[] table,可以看出,Entry就是数组中的元素,每个Entry就是一个key-value键值对,它持有一个只指向下一个元素的引用,这就构成了链表的数据结构。
关于数组的初始化时机不是我们在new HashTable的时候,实在我们第一次执行put()操作的时候:
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
/**如果这是一个空的table,就进行初始化*/
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
/**通过hash算法获取hash值*/
int hash = hash(key);
/**根据hash值获取在数组中的位置*/
int i = indexFor(hash, table.length);
/**获取数组在 i 位置上的链表,并进行循环*/
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
/**如果hash值相等,并且value值相等,value值会进行覆盖,返回之前的value*/
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果在i位置的entry为null,或者value的值不相同,执行addEctity()方法
modCount++;
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
// 如果当前数组已经饱和,并且当前位置的entry不是null,数组进行扩容
if ((size >= threshold) && (null != table[bucketIndex])) {
// 扩容操作,原数组需要重新计算在新数组中的位置,并放进去,这里会产生性能损耗
// 如果我们能已知元素个数,就可以在创建的时候进行生命即可。
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
// 创建新的Entry
createEntry(hash, key, value, bucketIndex);
}
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
根据hash算法得出元素在数组中的存放位置,如果改位置上已经存在元素,那么这个位置上的元素将以链表的形式存放,新加入的放在头部,后加入的在尾部。
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
根据key的hash值来决定元素在数组中的位置,如何计算这个位置就是hash算法。通过hash算法尽量使得数组的每个位置上都只有一个元素,当我们再次get()的时候,直接去数组中取就可以,不用再遍历链表。
hash(int h)根据key的hashcode重新计算一次散列,此算法加入了高位计算,防止低位不变,高位变化时,造成hash的冲突。
JAVA-HashMap实现原理的更多相关文章
- Java HashMap工作原理及实现
Java HashMap工作原理及实现 2016/03/20 | 分类: 基础技术 | 0 条评论 | 标签: HASHMAP 分享到:3 原文出处: Yikun 1. 概述 从本文你可以学习到: 什 ...
- Java HashMap实现原理 源码剖析
HashMap是基于哈希表的Map接口实现,提供了所有可选的映射操作,并允许使用null值和null建,不同步且不保证映射顺序.下面记录一下研究HashMap实现原理. HashMap内部存储 在Ha ...
- [翻译]Java HashMap工作原理
大部分Java开发者都在使用Map,特别是HashMap.HashMap是一种简单但强大的方式去存储和获取数据.但有多少开发者知道HashMap内部如何工作呢?几天前,我阅读了java.util.Ha ...
- 【转】Java HashMap工作原理(好文章)
大部分Java开发者都在使用Map,特别是HashMap.HashMap是一种简单但强大的方式去存储和获取数据.但有多少开发者知道HashMap内部如何工作呢?几天前,我阅读了java.util.Ha ...
- Java HashMap工作原理深入探讨
大部分Java开发者都在使用Map,特别是HashMap.HashMap是一种简单但强大的方式去存储和获取数据.但有多少开发者知道HashMap内部如何工作呢?几天前,我阅读了java.util.Ha ...
- Java HashMap工作原理及实现[转]
原文:http://yikun.github.io/2015/04/01/Java-HashMap%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86%E5%8F%8A%E5%AE ...
- 160706、Java HashMap工作原理及实现
1. 概述 从本文你可以学习到: 什么时候会使用HashMap?他有什么特点? 你知道HashMap的工作原理吗? 你知道get和put的原理吗?equals()和hashCode()的都有什么作用? ...
- Java HashMap实现原理分析
参考链接:https://www.cnblogs.com/xiarongjin/p/8310011.html 1. HashMap的数据结构 数据结构中有数组和链表来实现对数据的存储,但这两者基本上是 ...
- Java HashMap工作原理:不仅仅是HashMap
前言: 几乎所有java程序员都用过hashMap,但会用不一定会说. 近年来hashMap是非常常见的面试题,如何为自己的回答加分?需要从理解开始. "你用过hashMap吗?" ...
- java HashMap的原理
HashMap的数据结构: 在java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,HashMap也不例外.HashMap实际 ...
随机推荐
- 玩转vue前进刷新,后退不刷新and按需刷新
大白萝卜小课堂开讲了!带你玩转vue前进后退按需刷新! 用vue做后台管理项目,特别是有列表页.列表数据详情页.列表数据修改页功能的码友们,几乎都被vue前进后退都刷新的逻辑坑过,本萝卜更是! 萝卜的 ...
- Hadoop 集群安装(主节点安装)
1.下载安装包及测试文档 切换目录到/tmp view plain copy cd /tmp 下载Hadoop安装包 view plain copy wget http://192.168.1.100 ...
- SUSE12Sp3-.NET Core 2.2.1 runtime安装
1.安装libicu依赖 1.在线安装 sudo mkdir /usr/local/dotnet #创建目录 cd /usr/local/dotnet sudo wget https://downlo ...
- [Swift]LeetCode230. 二叉搜索树中第K小的元素 | Kth Smallest Element in a BST
Given a binary search tree, write a function kthSmallest to find the kth smallest element in it. Not ...
- [Swift]LeetCode365. 水壶问题 | Water and Jug Problem
You are given two jugs with capacities x and y litres. There is an infinite amount of water supply a ...
- [Swift]LeetCode763. 划分字母区间 | Partition Labels
A string S of lowercase letters is given. We want to partition this string into as many parts as pos ...
- [Swift]LeetCode798. 得分最高的最小轮调 | Smallest Rotation with Highest Score
Given an array A, we may rotate it by a non-negative integer K so that the array becomes A[K], A[K+1 ...
- [Swift]LeetCode985. 查询后的偶数和 | Sum of Even Numbers After Queries
We have an array A of integers, and an array queries of queries. For the i-th query val = queries[i] ...
- [Swift]LeetCode998. 最大二叉树 II | Maximum Binary Tree II
We are given the root node of a maximum tree: a tree where every node has a value greater than any o ...
- 开启SSH
开启 ssh 远程连接 1.修改 sshd_config 输入 sudo vim /etc/ssh/sshd_config 做如下修改 PermitRootLogin yes [需要把注释 #号去掉, ...