alibaba canal安装笔记
canal是alibaba开源的基于mysql binlog解析工具,可利用它实现mysql增量订阅/消费,典型的应用场景如下图:
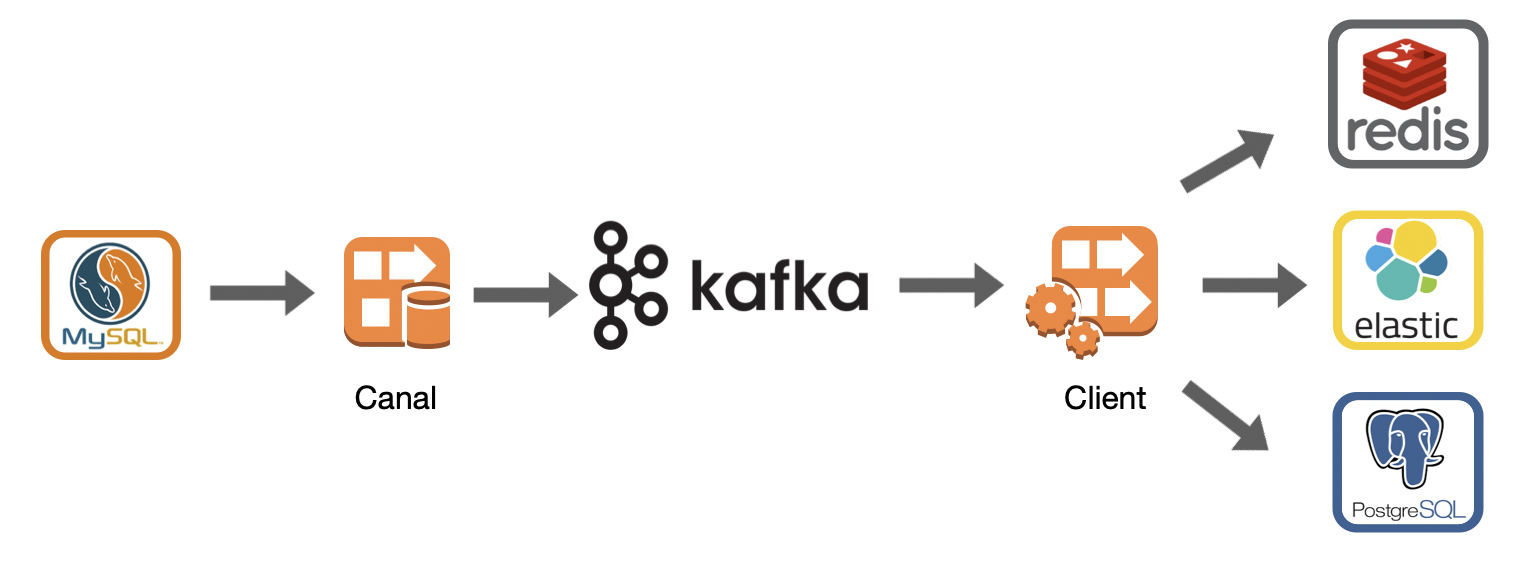
利用canal,可以将mysql的数据变化,通过解析binlog,投递到kafka(或rocket mq),mq的消费方,可以把这些数据变化,应用到不同的业务场景,比如:
1. 同步到redis(即:数据库的变化自动同步到缓存)
2. 同步到es搜索引擎(即:数据库的变化自动刷新ES索引)
3. 同步到其它异构数据库(即:mysql的变化,自动同步到pg、oracle等其它类型的数据库)
下面是mac本上,搭建standalone单机模式的过程:
一、安装zookeeper
注:canal、kafka都依赖zk,所以得先安装zk
1.1 wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
1.2 tar -zxvf zookeeper-3.4.14.tar.gz
1.3 cd zookeeper-3.4.14
1.4 cp conf/zoo_sample.cfg conf/zoo.cfg
1.5 vim conf/zoo.cfg 参考下面的内容
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/Users/jimmy/soft/zookeeper-3.4.14/data
dataLogDir=/Users/jimmy/soft/zookeeper-3.4.14/logs
clientPort=2181
注:dataDir, dataLogDir的目录大家可自行调整,如果没有,请先创建,且zk必须有写入权限
1.6 bin/zkServer.sh start-foreground 如果看到终端有类似下面的输入:
2019-05-26 13:27:38,667 [myid:] - INFO [main:ServerCnxnFactory@117] - Using org.apache.zookeeper.server.NIOServerCnxnFactory as server connection factory
2019-05-26 13:27:38,682 [myid:] - INFO [main:NIOServerCnxnFactory@89] - binding to port 0.0.0.0/0.0.0.0:2181
就表示启动成功了。
注:start-foreground表示前台启动,如果启动过程中有任何错误,也会直接输出,首次启动时,用这种方式可以快速排错。如果启动成功后,可以ctrl+c,然后用bin/zkServer.sh start 转入后台运行模式。
二、安装kafka
2.1 wget http://mirror.bit.edu.cn/apache/kafka/2.1.1/kafka_2.11-2.1.1.tgz
2.2 tar -zxvf kafka_2.11-2.1.1.tgz
2.3 vim config/server.properties 修改下面几处
...
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://127.0.0.1:9092
...
log.dirs=/Users/jimmy/soft/kafka_2.11-2.1.1/logs
注:主要就是指定个zk的地址,以及日志目录
2.4 bin/kafka-server-start.sh config/server.properties 启动
如果控制台没输出错误信息,lsof -i:9092 端口都在(另开1个终端检测),说明启用成功,Ctrl+C停掉,再用 bin/kafka-server-start.sh -daemon config/server.properties 后台方式运行
三、安装mysql
3.1 brew install mysql@5.7
注:不建议安装mysql 5.8版本,因为5.8采用了新的身份验证方式,canal在连接时,低版本会遇到问题(将来canal可能会支持5.8版本)
3.2 brew services start mysql@5.7 (注:start换成stop就是停止)
3.3 随便找个mysql客户端连上去,创建canal专用连接账号
CREATE USER 'canal'@'%' IDENTIFIED BY 'Canal.1.1.3.x';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
注:上面Canal.1.1.3.x 是canal的密码,大家根据需求自行修改。
3.4 调整my.cnf参数,启用binlog功能
vim /usr/local/etc/my.cnf
# Default Homebrew MySQL server config
[mysqld]
log-bin=mysql-bin
binlog-format=ROW
server_id=1
# Only allow connections from localhost
bind-address=127.0.0.1
调整好后,重启mysql,然后连上去,输入:
show master status;
验证一下,如果能看到类似: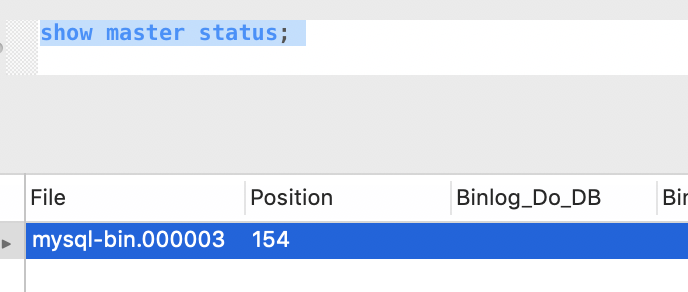
就表示ok了。
四、安装canal
4.1 wget https://github.com/alibaba/canal/releases/download/canal-1.1.3/canal.deployer-1.1.3.tar.gz
4.2 tar -zxvf canal.deployer-1.1.3.tar.gz
4.3 cd canal-1.1.3 (注:如果解析后的目录名,不是这个,大家自行调整)
4.4 vim conf/example/instance.properties
....
canal.instance.mysql.slaveId=1234 ....
canal.instance.master.address=127.0.0.1:3306
canal.instance.master.journal.name=mysql-bin.000001
canal.instance.master.position=154 ...
canal.instance.dbUsername=canal
canal.instance.dbPassword=Canal.1.1.3.x
canal.instance.connectionCharset=UTF-8 ... # table regex(同步sample库中的employee,city这二张表)
canal.instance.filter.regex=sample\\.employee,sample\\.city # mq config(上面的二张表,数据变化,投放到sample-data中)
canal.mq.topic=sample-data ...
主要是指定:mysql地址及binlog起始位置(注:最好与上一步show master status里输出的信息一致),连接用户名/密码,以及kafka mq的topic信息(上面的配置,我们会把sample库的employee,city这二张表的变化,都投递到sample-data这个topic中)
4.5 vim conf/canal.properties
...
canal.serverMode=kafka ...
canal.destinations = example ...
canal.mq.servers = 127.0.0.1:9092
注:上述关键配置,表示canal将使用kafka作为mq,同时conf/example作为desination之一。
4.6 bin/startup.sh 启动
启动完成后,是否成功要通过日志查看
cat logs/canal/canal.log 如果能看到类似下面的输出:
2019-05-26 14:43:36.468 [main] INFO com.alibaba.otter.canal.deployer.CanalStater - ## the canal server is running now ......
2019-05-26 14:43:36.468 [destination = metrics , address = null , EventParser] ERROR c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - parse events has an error
com.alibaba.otter.canal.parse.exception.CanalParseException: illegal connection is null
2019-05-26 14:43:36.482 [canal-instance-scan-0] INFO c.a.o.canal.deployer.monitor.SpringInstanceConfigMonitor - auto notify stop metrics successful.
2019-05-26 14:43:36.713 [destination = example , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> find start position successfully, EntryPosition[included=false,journalName=mysql-bin.000001,position=4435,serverId=1,gtid=,timestamp=1558841400000] cost : 409ms , the next step is binlog dump
就表示成功了。
注:如果启动不成功,可能原因有:
1、canal连接不上mysql,日志里会有相应提示,可尝试用mysql客户端,以canal里配置的用户名、密码连接测试一下
2、提示无法读取binlog,找不到binlog文件之类。如果mysql里show master status正常,多半是之前canal上次运行时记录了错误的binlog起始位置。可尝试调整/conf/example/meta.dat文件中的值
{"clientDatas":[{"clientIdentity":{"clientId":1001,"destination":"example","filter":""},"cursor":{"identity":{"slaveId":-1,"sourceAddress":{"address":"localhost","port":3306}},"postion":{"gtid":"","included":false,"journalName":"mysql-bin.000004","position":2805,"serverId":1,"timestamp":1558880055000}}}],"destination":"example"}y
该文件为一个标准json,里面记录了binlog的文件名及起始位置。或者简单粗暴点,删除/conf/example下的.dat以及.db文件。
4.7 查看kafka中的消息
先在sample数据库中,随便建二个表,并修改几行数据,表结构如下:
CREATE TABLE `employee` (
`id` bigint(20) unsigned zerofill NOT NULL AUTO_INCREMENT COMMENT '主键id',
`name` varchar(100) NOT NULL DEFAULT '' COMMENT '姓名',
`update_at` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT '最后更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8mb4
及
CREATE TABLE `city` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`city_name` varchar(100) DEFAULT '' COMMENT '城市名',
`create_at` datetime(3) DEFAULT CURRENT_TIMESTAMP(3),
`update_at` datetime(3) DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3),
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COMMENT='城市表'
然后回到终端界面。
4.7.1 cd kafka_2.11-2.1.1 进入kafka目录
4.7.2 bin/kafka-topics.sh --list --zookeeper 127.0.0.1:2181 查看所有topic, 如果输出信息中,有sample-data这个topic,表示topic正常
4.7.3 bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --from-beginning --topic sample-data 查看所有sample topic的消息
看到类似下面的输出(注:为了便于阅读,已经做了json格式化处理)
{
"data": [{
"id": "6",
"name": "杨俊明",
"update_at": "2019-05-26 14:51:30.094"
}],
"database": "sample",
"es": 1558853490000,
"id": 4,
"isDdl": false,
"mysqlType": {
"id": "bigint(20) unsigned zerofill",
"name": "varchar(100)",
"update_at": "datetime(3)"
},
"old": [{
"name": "新名称",
"update_at": "2019-05-26 11:30:00.899"
}],
"pkNames": ["id"],
"sql": "",
"sqlType": {
"id": -5,
"name": 12,
"update_at": 93
},
"table": "employee",
"ts": 1558853490132,
"type": "UPDATE"
}
或
{
"data": [{
"id": "2",
"city_name": "北京",
"create_at": "2019-05-26 22:14:15.508",
"update_at": "2019-05-26 22:14:15.508"
}],
"database": "sample",
"es": 1558880055000,
"id": 5,
"isDdl": false,
"mysqlType": {
"id": "bigint",
"city_name": "varchar(100)",
"create_at": "datetime(3)",
"update_at": "datetime(3)"
},
"old": null,
"pkNames": ["id"],
"sql": "",
"sqlType": {
"id": -5,
"city_name": 12,
"create_at": 93,
"update_at": 93
},
"table": "city",
"ts": 1558880055712,
"type": "INSERT"
}
参考文章:
https://github.com/alibaba/canal/wiki/Kafka-QuickStart
https://github.com/alibaba/canal/wiki/Canal-Kafka-RocketMQ-QuickStart
https://www.jianshu.com/p/93d9018e2fa1
alibaba canal安装笔记的更多相关文章
- 阿里Canal安装和代码示例
Canal的简单使用 canal可以用来监控数据库数据的变化,从而获得新增数据,或者修改的数据,用于实际工作中,比较实用,特此记录一下 Canal简介 canal是应阿里巴巴存在杭州和美国的双机房部署 ...
- mysql 开源~canal安装解析
一 简介:今天咱们来聊聊canal的一些东西 二 原理: canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议 mysql ma ...
- canal安装与使用
安装 alpha的版本不是稳定的版本 wget https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.deploye ...
- MonoDevelop 4.2.2/Mono 3.4.0 in CentOS 6.5 安装笔记
MonoDevelop 4.2.2/Mono 3.4.0 in CentOS 6.5 安装笔记 说明 以root账户登录Linux操作系统,注意:本文中的所有命令行前面的 #> 表示命令行提示符 ...
- 基于Ubuntu14.04系统的nvidia tesla K40驱动和cuda 7.5安装笔记
基于Ubuntu14.04系统的nvidia tesla K40驱动和cuda 7.5安装笔记 飞翔的蜘蛛人 注1:本人新手,文章中不准确的地方,欢迎批评指正 注2:知识储备应达到Linux入门级水平 ...
- sublime 安装笔记
sublime 安装笔记 下载地址 安装package control 根据版本复制相应的代码到console,运行 按要求重启几次后再按crtl+shift+p打开命令窗口 输入pcip即可开始安装 ...
- docker在ubuntu14.04下的安装笔记
本文主要是参考官网教程进行ubuntu14.04的安装. 下面是我的安装笔记. 笔记原件完整下载: 链接: https://pan.baidu.com/s/1dEPQ8mP 密码: gq2p
- ArchLinux 安装笔记:续 --zz
续前话 在虚拟机里调试了几天,终于鼓起勇气往实体机安装了,到桌面环境为止的安装过程可以看我的前一篇文章<ArchLinux 安装笔记>.桌面环境我使用的是 GNOME,虽然用了很长一段时间 ...
- Hadoop1.x与2.x安装笔记
Hadoop1.x与2.x安装笔记 Email: chujiaqiang229@163.com 2015-05-09 Hadoop 1.x 安装 Hadoop1.x 集群规划 No 名称 内容 备注 ...
随机推荐
- LeetCode OJ-- Jump Game
https://oj.leetcode.com/problems/jump-game/ 从0开始,根据每一位上存的数值往前跳. 这道题给想复杂了... 记录当前位置 pos,记录可以调到的最远达位置为 ...
- List集合使用注意的问题
在做自动保存草稿的功能遇到集合数据的问题,先贴自动保存草稿的代码 /** * 每5 秒保存一次草稿 */private void startDraftTimerTask(){ if (draftTim ...
- Codeforces Round #315 (Div. 2)【贪心/重排去掉大于n的元素和替换重复的元素】
B. Inventory time limit per test 1 second memory limit per test 256 megabytes input standard input o ...
- Codeforces 429D Tricky Function(平面最近点对)
题目链接 Tricky Function $f(i, j) = (i - j)^{2} + (s[i] - s[j])^{2}$ 把$(i, s[i])$塞到平面直角坐标系里,于是转化成了平面最近点 ...
- Codeforces 732F. Tourist Reform (Tarjan缩点)
题目链接:http://codeforces.com/problemset/problem/732/F 题意: 给出一个有n个点m条边的无向图,保证联通,现在要求将所有边给定一个方向使其变成有向图,设 ...
- NOI模拟题5 Problem A: 开场题
Solution 注意到\(\gcd\)具有结合律: \[ \gcd(a, b, c) = \gcd(a, \gcd(b, c)) \] 因此我们从后往前, 对于每个位置\(L\), 找到每一段不同的 ...
- MATLAB逻辑函数
%%逻辑函数 %%all:判断是否有元素非0,A是多维矩阵,all(A)是以列为单位来处理的,当前列的逻辑 %值为1,当且仅当当前列的每一个元素都非0 A=[1,2,3;0,2,1;5,0,2]; % ...
- 网上常用免费webservice_查询(网络复制)
MP3在线搜索服务 地址:http://www.wopos.com/webservice/song.asmx 介绍: 使用: getMusicList()方法搜索MP3/WMA等音乐文件 多功能条形码 ...
- 127.0.0.1和localhost和本机IP三者的区别
1,什么是环回地址??与127.0.0.1的区别呢?? 环回地址是主机用于向自身发送通信的一个特殊地址(也就是一个特殊的目的地址). 可以这么说:同一台主机上的两项服务若使用环回地址而非分配的主机地址 ...
- vue2.0 仿手机新闻站(二)项目结构搭建 及 路由配置
1.项目结构 $ vue init webpack-simple news $ npm install vuex vue-router axios style-loader css-loader -D ...