Hadoop启动datanode失败,clusterId有问题
问题:
搭建伪Hadoop集群的时候,运行命令:
hdfs namenode -format
格式化或者说初始化namenode。
然后用命令:
start-dfs.sh
来启动hdfs时,jps发现datanode先是启动了一下,然后就挂掉了,在http://192.168.195.128:50070 (HDFS管理界面)也看不到datanode的信息。
然后去datanode的日志上面看,看到这样的报错:

出错原因:(来自博客https://blog.csdn.net/qq_30136589/article/details/51638069)
hadoop的升级功能需要data-node在它的版本文件里存储一个永久性的clusterID,当datanode启动时会检查并匹配namenode的版本文件里的clusterID,如果两者不匹配,就会出现"Incompatible clusterIDs"的异常。
每次格式化namenode都会生成一个新的clusterID, 如果只格式化了namenode,没有格式化此datanode, 就会出现”java.io.IOException: Incompatible namespaceIDs“异常。
参见官方CCR[HDFS-107]
这就解释了,为什么我第一次是成功的,后面一直都datanode挂掉的情况。
因为第一次成功后,每次再跑hdfs之前我都格式化或者说初始化了hdfs的配置。然后,namenode的clusterId就会清空,在你跑start-dfs.sh的时候,就会重新生成一个clusterId。但你datanode没有初始化噢,就是说datanode里面的那个clusterId还是之前那个,于是就出现了两者不匹配,报错了。
解决方法:
1.在namenode机器上: 找到${dfs.namenode.name.dir}/current/VERSION 里找到clusterID。这个dfs.namenode,name.dir在hdfs-site.xml可以找到你这个路径的真正路径。:

这里的话就是在/home/hadoop/data/name/current下找到VERSION文件,然后里面有个clusterId,找到它复制了:
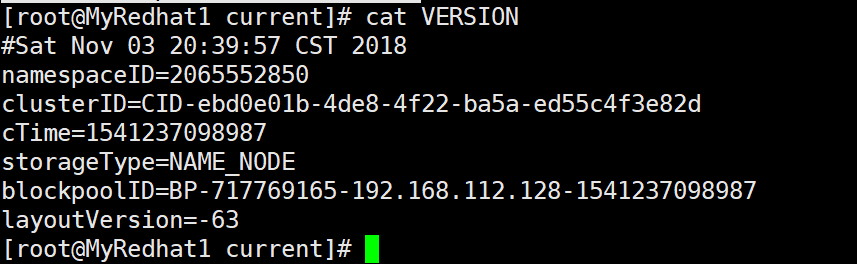
2.在出问题的datanode上: 找到$dfs.datanode.data.dir,这个也是在hdfs-site.xml配置文件可以找到这个路径具体的位置:

像我的机器,就是在/home/hadoop/data/data/current下找到VERSION文件,然后里面也有个clusterId:

然后你要做的就是把(1)中复制的namenode的clusterId覆盖了出问题的datanode的clusterId。
3.在问题节点重新重启你的datanode,也就是重新跑命令:
start-dfs.sh
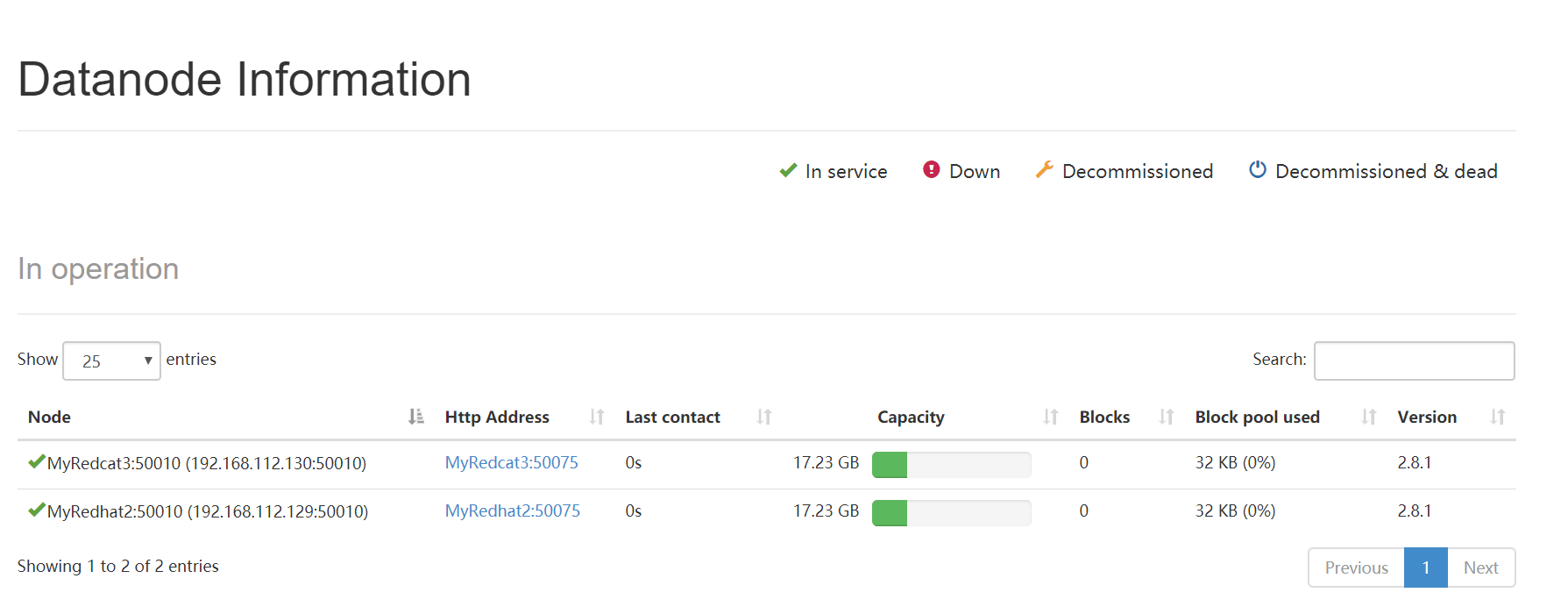
然后datanode就重新跑起来了。在浏览器上访问那个管理界面也看到datanode了:
注意:
1.配置完clusterId后不要再hdfs namenode -format格式化或者说初始化namenode了。
2.记得把所有机器的防火墙给关了,不然可能通信上会有所拦截。(反正我一开始没关,然后配好了clusterId在浏览器的Hadoop管理界面上没能看到datanode,一关掉所有机器的防火墙就好了~)
Hadoop启动datanode失败,clusterId有问题的更多相关文章
- Hadoop启动dataNode失败,却没有任何报错
问题描述: centos7,伪分布模式下,启动datanode后,通过JPS查看发现没有相关进程,在日志文件里也没有任何提示.通过百度,网上一堆说什么vesion 的ID不一致,不能解决我的问题. 经 ...
- hadoop启动 datanode的live node为0
hadoop启动 datanode的live node为0 浏览器访问主节点50070端口,发现 Data Node 的 Live Node 为 0 查看子节点的日志 看到 可能是无法访问到主节点的9 ...
- hadoop启动name失败
namenode失败十分的常见, 1.java.io.EOFException; Host Details : local host is: "hadoop1/192.168.41.134& ...
- 当Hadoop 启动节点Datanode失败解决
Hadoop 启动节点Datanode失败解决 [日期:2014-11-01] 来源:Linux社区 作者:shuideyidi [字体:大 中 小] 当我动态添加一个Hadoop从节点的之后,出现 ...
- Hadoop在linux下无法启动DataNode解决方法
最近重新捡起了Hadoop,所以博客重新开张- 首先描述一下我的问题:这次我使用eclipse在Ubuntu上运行hadoop程序.首先,按照厦门大学数据库实验室的eclipse下运行hadoop程序 ...
- Hadoop重新格式namenode后无法启动datanode的问题
这个很简单的哇~ 格式化namenode之后就会给namenode的ClusterId重新生成,导致与datanode中的ClusterId不一致而无法启动datanode 解决方法: 进入hadoo ...
- 解决Hadoop集群hdfs无法启动DataNode的问题
问题描述: 在hadoop启动hdfs的之后,使用jps命令查看运行情况时发现hdfs的DataNode并没有打开. 笔者出现此情况前曾使用hdfs namenode -format格式化了hdfs ...
- ssh IP打通,hadoop启动失败
ssh ip 无密码打通,hadoop启动失败 报错为:host'主机名' can't be established. 纠结了接近一个多小时 之后必须ssh 主机名 , yes一下,发现hadoop能 ...
- Hadoop的datanode无法启动
Hadoop的datanode无法启动 hdfs-site中配置的dfs.data.dir为/usr/local/hadoop/hdfs/data 用bin/hadoop start-all.sh启动 ...
随机推荐
- Gym - 100187J J - Deck Shuffling —— dfs
题目链接:http://codeforces.com/gym/100187/problem/J 题目链接:问通过洗牌器,能否将编号为x的牌子转移到第一个位置? 根据 洗牌器,我们可以知道原本在第i位置 ...
- 人生苦短之Python发邮件
#coding=utf-8 import smtplib from email.mime.base import MIMEBase from email.mime.image import MIMEI ...
- zk使用通知移除节点
前面:https://www.cnblogs.com/toov5/p/9899238.html 服务发生宕机 咋办? 发个事件通知,告知大家哟, 会有通知事件哦 看项目: 服务端: package c ...
- js程序开发-2
<h1>DOM节点操作</h1> createElement() 创建节点:返回一个元素对象; cloneNode() 克隆节点,接受一个参数deep,值为true或false ...
- ansible 基础知识
英文官网,值得拥有! http://docs.ansible.com/ansible/list_of_files_modules.html# 摘自: http://blog.csdn.net/b624 ...
- codeforces 466A. Cheap Travel 解题报告
题目链接:http://codeforces.com/problemset/problem/466/A 题目意思:一个 ride 需要 a 卢布,m 个 ride 需要 b 卢布,这两种方案都可以无限 ...
- C#评分小系统练习
一个经理类 using System; using System.Collections.Generic; using System.Linq; using System.Text; using Sy ...
- C++软件工程师,你该会什么?
请尊重原创: 转载注明来源 原创在这里哦 C语言广泛用于基础软件.桌面系统.网络通信.音频视频.游戏娱乐等诸多领域.是世界上使用最广泛的编程语言之一.随着物联网技术的发展,C/C++技术在3G网络 ...
- Java中String args[]起什么作用?
在百度知道上看到这样一个答案: 在命令提示符中运行该程序时 可以附加参数运行 输入的参数会存入到字符传数组 args[]中例如:在命令提示符中运行该程序的时候假设该程序在D的JAVA文件夹中D:JAV ...
- 【转】Cache Buffer Chain 第二篇
文章转自:http://m.bianceng.cn/database/Oracle/201407/42884.htm 测试环境:版本11gR2 SQL> select * from v$vers ...