Hadoop启动datanode失败,clusterId有问题
问题:
搭建伪Hadoop集群的时候,运行命令:
hdfs namenode -format
格式化或者说初始化namenode。
然后用命令:
start-dfs.sh
来启动hdfs时,jps发现datanode先是启动了一下,然后就挂掉了,在http://192.168.195.128:50070 (HDFS管理界面)也看不到datanode的信息。
然后去datanode的日志上面看,看到这样的报错:

出错原因:(来自博客https://blog.csdn.net/qq_30136589/article/details/51638069)
hadoop的升级功能需要data-node在它的版本文件里存储一个永久性的clusterID,当datanode启动时会检查并匹配namenode的版本文件里的clusterID,如果两者不匹配,就会出现"Incompatible clusterIDs"的异常。
每次格式化namenode都会生成一个新的clusterID, 如果只格式化了namenode,没有格式化此datanode, 就会出现”java.io.IOException: Incompatible namespaceIDs“异常。
参见官方CCR[HDFS-107]
这就解释了,为什么我第一次是成功的,后面一直都datanode挂掉的情况。
因为第一次成功后,每次再跑hdfs之前我都格式化或者说初始化了hdfs的配置。然后,namenode的clusterId就会清空,在你跑start-dfs.sh的时候,就会重新生成一个clusterId。但你datanode没有初始化噢,就是说datanode里面的那个clusterId还是之前那个,于是就出现了两者不匹配,报错了。
解决方法:
1.在namenode机器上: 找到${dfs.namenode.name.dir}/current/VERSION 里找到clusterID。这个dfs.namenode,name.dir在hdfs-site.xml可以找到你这个路径的真正路径。:

这里的话就是在/home/hadoop/data/name/current下找到VERSION文件,然后里面有个clusterId,找到它复制了:
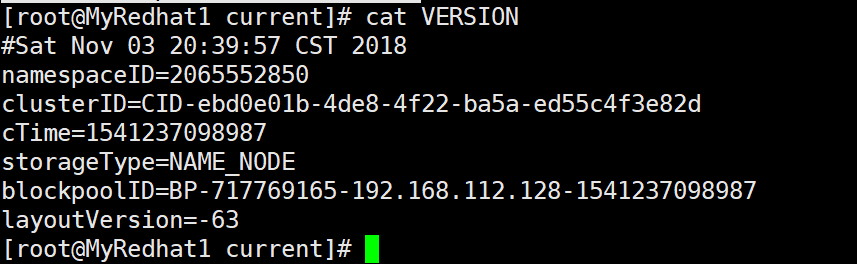
2.在出问题的datanode上: 找到$dfs.datanode.data.dir,这个也是在hdfs-site.xml配置文件可以找到这个路径具体的位置:

像我的机器,就是在/home/hadoop/data/data/current下找到VERSION文件,然后里面也有个clusterId:

然后你要做的就是把(1)中复制的namenode的clusterId覆盖了出问题的datanode的clusterId。
3.在问题节点重新重启你的datanode,也就是重新跑命令:
start-dfs.sh
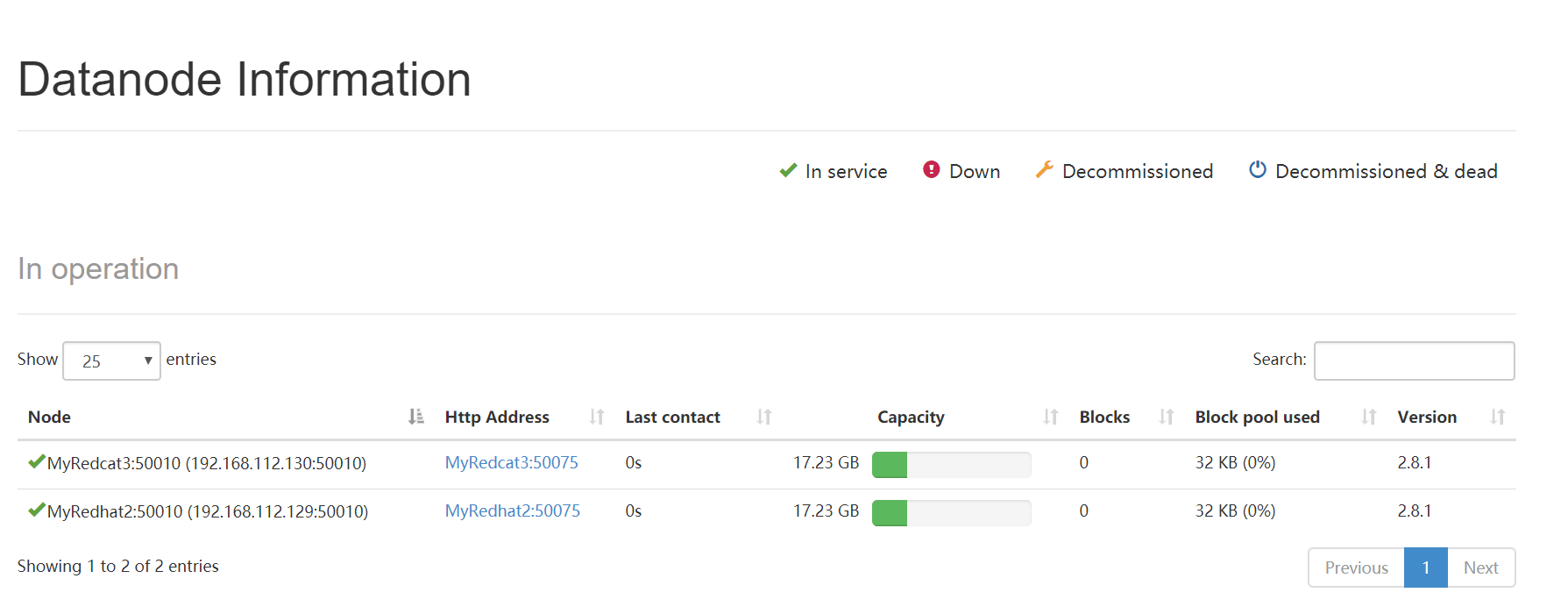
然后datanode就重新跑起来了。在浏览器上访问那个管理界面也看到datanode了:
注意:
1.配置完clusterId后不要再hdfs namenode -format格式化或者说初始化namenode了。
2.记得把所有机器的防火墙给关了,不然可能通信上会有所拦截。(反正我一开始没关,然后配好了clusterId在浏览器的Hadoop管理界面上没能看到datanode,一关掉所有机器的防火墙就好了~)
Hadoop启动datanode失败,clusterId有问题的更多相关文章
- Hadoop启动dataNode失败,却没有任何报错
问题描述: centos7,伪分布模式下,启动datanode后,通过JPS查看发现没有相关进程,在日志文件里也没有任何提示.通过百度,网上一堆说什么vesion 的ID不一致,不能解决我的问题. 经 ...
- hadoop启动 datanode的live node为0
hadoop启动 datanode的live node为0 浏览器访问主节点50070端口,发现 Data Node 的 Live Node 为 0 查看子节点的日志 看到 可能是无法访问到主节点的9 ...
- hadoop启动name失败
namenode失败十分的常见, 1.java.io.EOFException; Host Details : local host is: "hadoop1/192.168.41.134& ...
- 当Hadoop 启动节点Datanode失败解决
Hadoop 启动节点Datanode失败解决 [日期:2014-11-01] 来源:Linux社区 作者:shuideyidi [字体:大 中 小] 当我动态添加一个Hadoop从节点的之后,出现 ...
- Hadoop在linux下无法启动DataNode解决方法
最近重新捡起了Hadoop,所以博客重新开张- 首先描述一下我的问题:这次我使用eclipse在Ubuntu上运行hadoop程序.首先,按照厦门大学数据库实验室的eclipse下运行hadoop程序 ...
- Hadoop重新格式namenode后无法启动datanode的问题
这个很简单的哇~ 格式化namenode之后就会给namenode的ClusterId重新生成,导致与datanode中的ClusterId不一致而无法启动datanode 解决方法: 进入hadoo ...
- 解决Hadoop集群hdfs无法启动DataNode的问题
问题描述: 在hadoop启动hdfs的之后,使用jps命令查看运行情况时发现hdfs的DataNode并没有打开. 笔者出现此情况前曾使用hdfs namenode -format格式化了hdfs ...
- ssh IP打通,hadoop启动失败
ssh ip 无密码打通,hadoop启动失败 报错为:host'主机名' can't be established. 纠结了接近一个多小时 之后必须ssh 主机名 , yes一下,发现hadoop能 ...
- Hadoop的datanode无法启动
Hadoop的datanode无法启动 hdfs-site中配置的dfs.data.dir为/usr/local/hadoop/hdfs/data 用bin/hadoop start-all.sh启动 ...
随机推荐
- iOS 使用.xcworkspace文件管理代码和工程依赖(实现项目模块化)
一.创建xcworkspace文件. 在cocoapods安装后,项目文件里都会多一个后缀为.xcworkspace的文件.打开这个文件就相当打开最初创建的项目了.那么这个文件也就是用来管理项目的,它 ...
- hdu 1040 As Easy As A+B(排序)
题意:裸排序 思路:排序 #include<iostream> #include<stdio.h> #include<algorithm> using namesp ...
- emacs设置tab缩进
这两天使用Emacs自带的JavaScriptMode时,发现与其它编辑器下缩进不同,而且用emacs重新缩进对齐后,再用其它的编辑器打时缩进却乱掉了.分析应该是Tab缩进的问题,在.emacs中增加 ...
- 自然语言处理:问答 + CNN 笔记
参考 Applying Deep Learning To Answer Selection: A Study And An Open Task follow: http://www.52nlp.cn/ ...
- linux文件查找(find,locate)
文件查找: locate: 非实时,模糊匹配,查找是根据全系统文件数据库进行的: # updatedb, 手动生成文件数据库 速度快 find: 实时 精确 ...
- DIY一个DNS查询器:程序实现
上一篇文章<DIY一个DNS查询器:了解DNS协议>中讲了DNS查询协议的原理和数据结构.经过两个星期的开发,完成了该查询器的编写.期间也遇到了一些问题,如: 1资源记录(Resource ...
- bzoj 3527 [Zjoi2014] 力 —— FFT
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=3527 看了看TJ才推出来式子,还是不够熟练啊: TJ:https://blog.csdn.n ...
- sparkContext之一:sparkContext的初始化分析
Spark源码学习:sparkContext的初始化分析 spark可以运行在本地模式local下,可以运行在yarn和standalone模式下,但是本地程序是通过什么渠道和这些集群交互的呢?那就是 ...
- C语言指针入门知识
C语言指针往往是C语言学习过程中最困难的地方, 最近重新理解了一下C语言的指针知识, 在此整理一下, 如果有错误请留言指正. 对于刚入门的人来说, 指针涉及方方面面, 从简单的数组到结构体, 都会用到 ...
- $.ajax数据传输成功却执行失败的回调函数
这个问题迷惑了我好几天,都快要放弃了,功夫不负有心人,最终成功解决,下面写一下我的解决方法. 我传的数据是json类型的,执行失败的回调函数是因为从后台传过来的数据不是严格的json类型,所以才会不执 ...