python爬虫知识点总结(一)库的安装
环境要求:
1、编程语言版本python3;
2、系统:win10;
3、浏览器:Chrome68.0.3440.75;(如果不是最新版有可能影响到程序执行)
4、chromedriver2.41
注意点:pip3 install 命令必须在管理员权限下才能有效下载!
一、安装python3
不是本文重点,初学者,建议上百度搜索,提供几个思路:
1、官网:https://www.python.org/
IDE:pycharm
2、anaconda安装后自带python
等等。
二、配置环境变量
需要配置的路径有两个
1、python.exe所在路径(python所在)
2、Script文件夹下的路径(pip所在)
三、爬虫常用库的安装
(1)requests库
管理员运行cmd。
输入命令:pip3 install requests
测试:在cmd下运行一下代码实例测试:
import requests
requests.get('http://www.baidu.com')
结果如图:

(2)selenium库
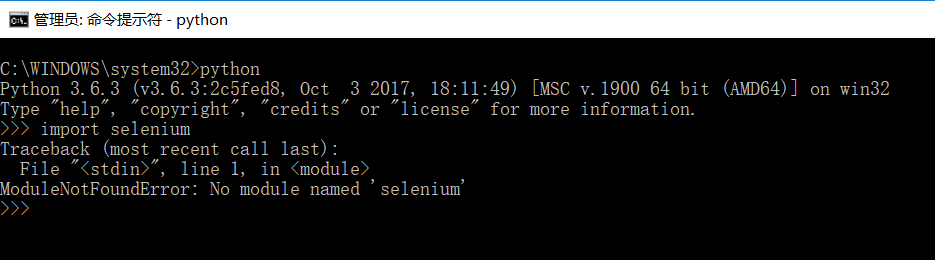
先检查selenium在本地有没有。
和上面的图操作一样,进到python->输入import selenium
如果没安装,会报错,如下图:
在cmd下输入命令:pip3 install selenium
安装结果如下图:

尝试运行代码实例:
import selenium
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
driver.page_source
会报错:

因为本地没有Chromdriver,需要下载,下载最新版就可以了
http://npm.taobao.org/mirrors/chromedriver/
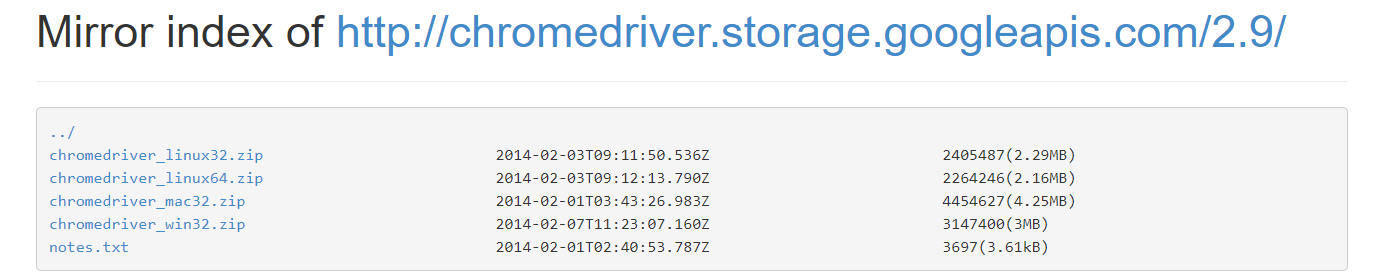
将chromedriver.exe放到python.exe文件夹下,或者Scripts文件夹下(本质是环境变量配置,方便python找到)
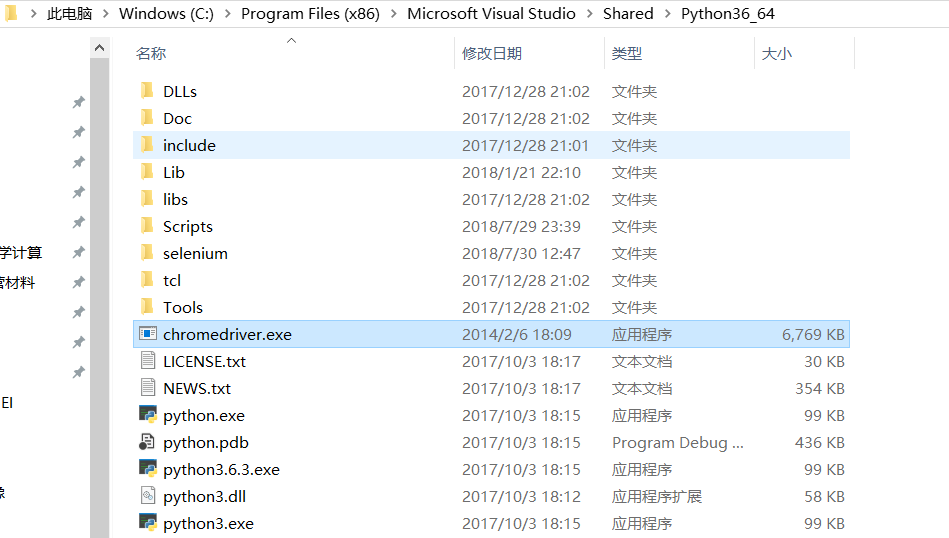
在cmd下输入命令:chromedriver
再次运行代码实例,如果出错如下,那就看我的这篇博客:
https://www.cnblogs.com/cthon/p/9390095.html
https://www.cnblogs.com/cthon/p/9390998.html
其本质是,chrome版本和webdriver不一致,一定记住下载最新版本的chrome

正确的执行结果应该是:
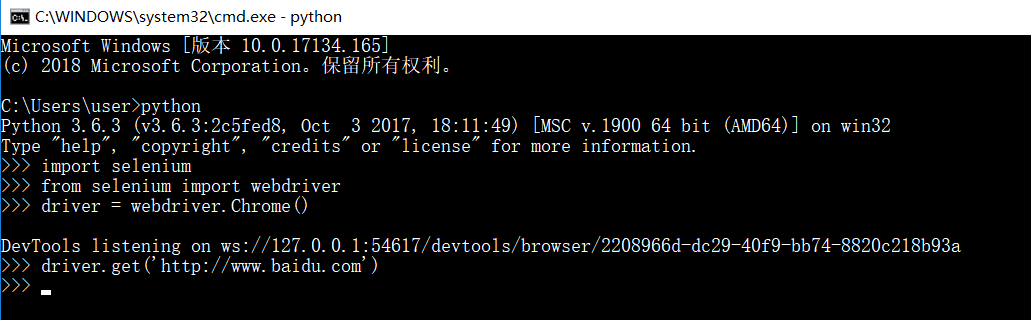
执行成功会自动弹出Google浏览器并进入百度界面

(3)phantomjs(无界面浏览器)
下载链接:http://phantomjs.org/download.html
解压后,配置环境变量phantomjs

检查是否配置成功
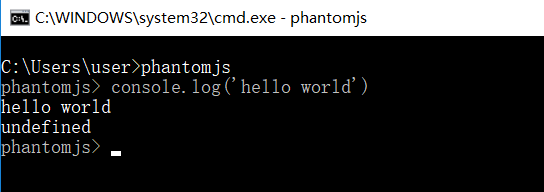
代码实例测试:
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get("http://www.baidu.com")
driver.page_source
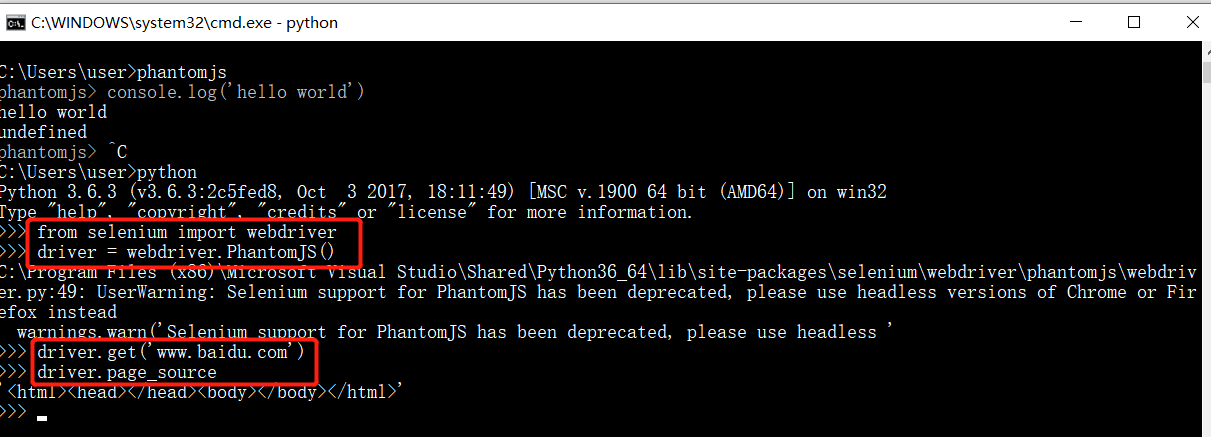
(4)lxml库
在cmd下,输入命令:pip3 install lxml
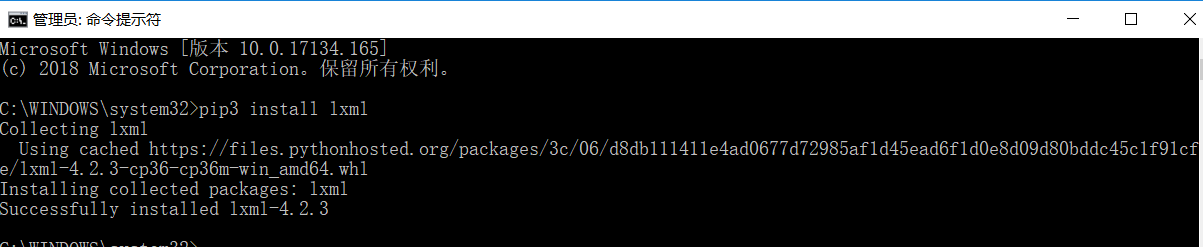
(5)beautifulsoup库
在cmd下,输入命令:pip3 install beautifulsoup4
有可能会爆出找不到该版本的错误信息,那就通过下载链接:https://www.crummy.com/software/BeautifulSoup/bs4/download/

运行代码示例:
from bs4 import BeautifulSoup
soup = BeautifulSoup('<html></html>','lxml')

(6)pyquery库(和beautifulsoup一样是网页解析库,个人觉得比较方便)
官方学习:https://pythonhosted.org/pyquery/
在cmd下,输入命令:pip3 install pyquery
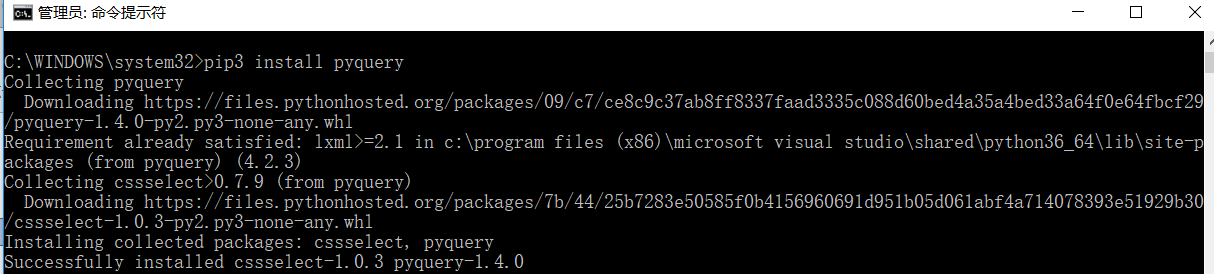
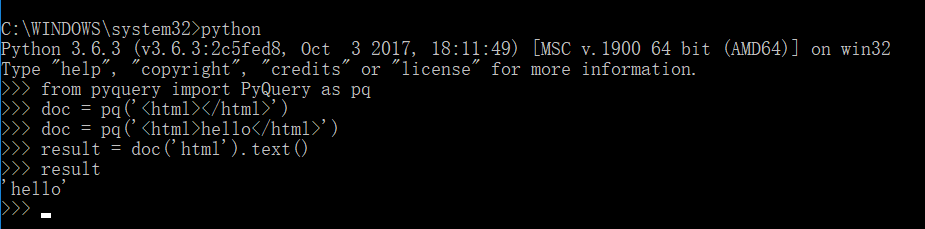
运行代码实例:
from pyquery import PyQuery as pq
doc = pq('<html></html>')
doc = pq('<html>hello</html>')
result = doc('html').text()
result
(7)pymysql库(操作mysql)
在cmd下,输入命令:pip3 install pymysql
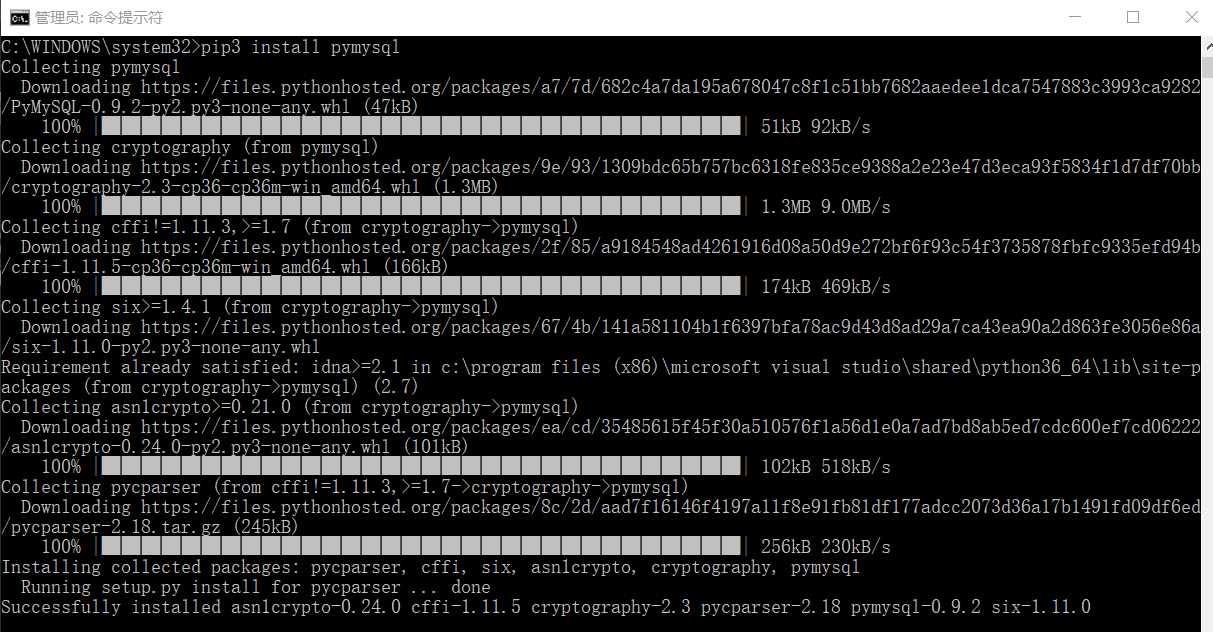
运行代码实例:
import pymysql
conn = pymysql.connect(host='localhost',user='root',password='root',port=,db='mysql')
cursor = conn.cursor()
cursor.execute('select * from db')
cursor.fetchone()
cursor.execute('select * from myuser')
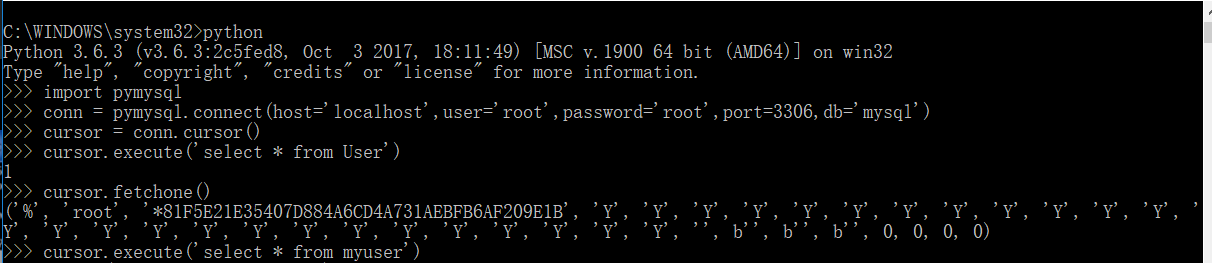
对比一下,mysql的数据

(8)pymongo库(操作mongodb)--key-value型,数据存储很方便,不需要建表,可以动态增加一些键名
在cmd下,输入命令:pip3 install pymongo

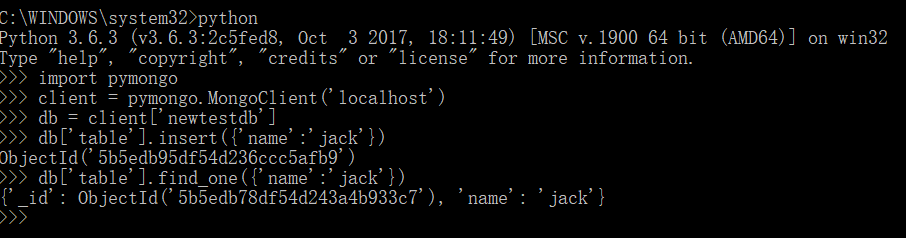
输入代码实例:
import pymongo
client = pymongo.MongoClient('localhost')
db = client['newtestdb']
db['table'].insert({'name':'jack'})
db['table'].find_one({'name':'jack'})
(9)redis库(操作redis)--key-value型,用在分布式爬虫,维护爬取队列,效果比较理想
在cmd下:输入命令:pip3 install redis

运行代码实例:
import redis
r = redis.Redis('localhost',)
r.set('name','jack')
r.get('name')

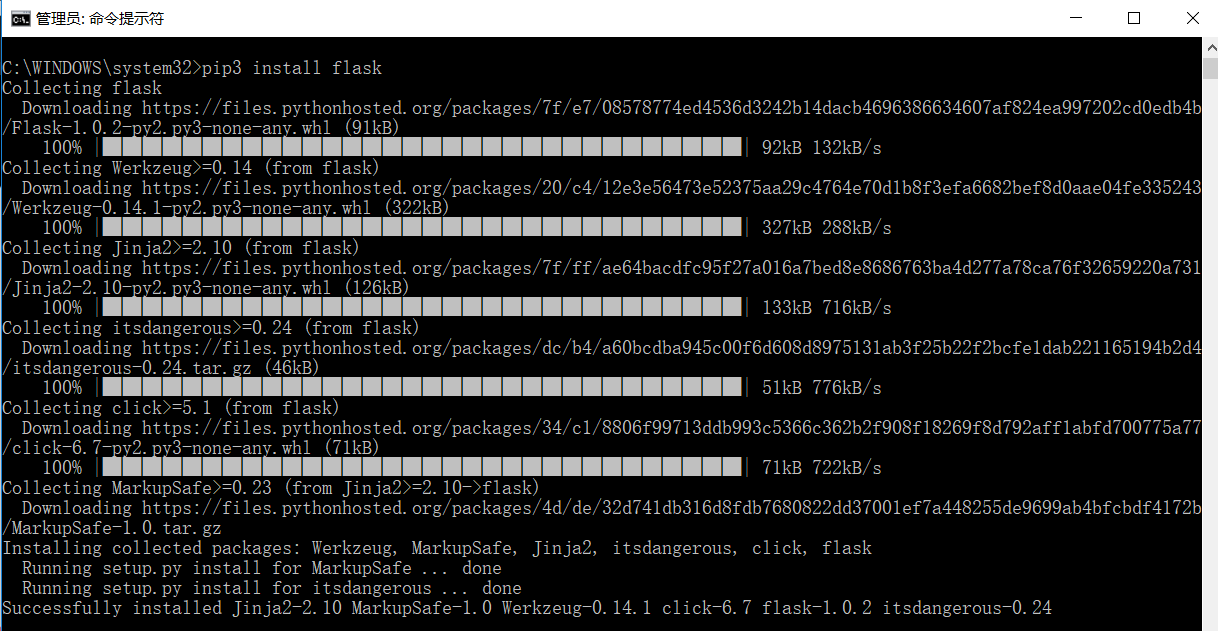
(10)flask库(web库,在做一些代理的设置时需要用到,用来设置一些代理的获取和存储)
官方文档:http://www.pythondoc.com/flask/index.html
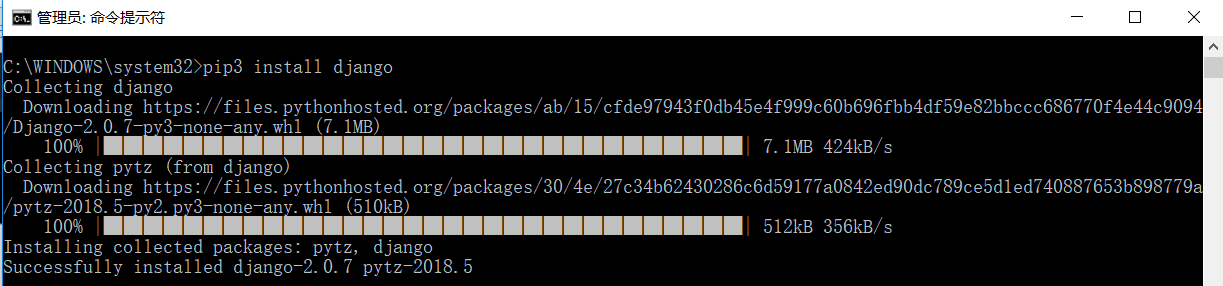
(11)django库(web服务器框架,提供了服务器后台管理,模板引擎,接口,路由,用于分布式爬虫的维护)
官方文档:https://docs.djangoproject.com/en/2.0/
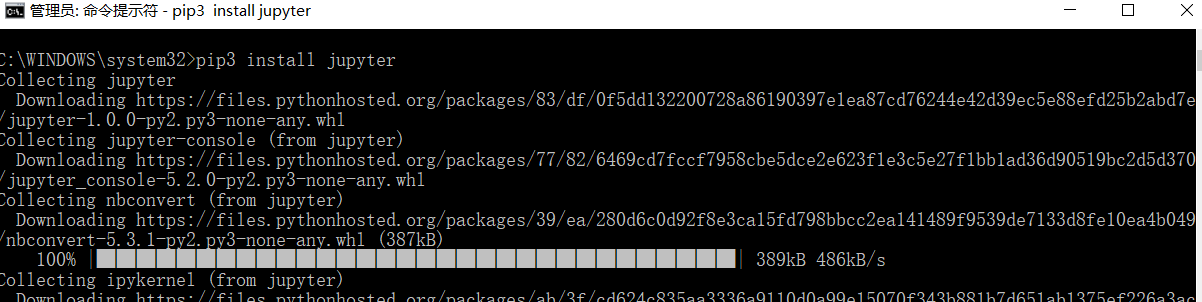
(12)jupyter库(相当于notebook,用来编写代码记录)
官方文档:https://jupyter.org/documentation
在cmd下,输入命令:pip3 install jupyter
内容很多,我就不全部截图了,正确运行就可以了。
jupyter的启动方法有两个:
1、在命令行输入:jupyter notebook
会在浏览器中弹出一个网页notebook 代码编辑页
按照以下步骤可以进行代码编辑,
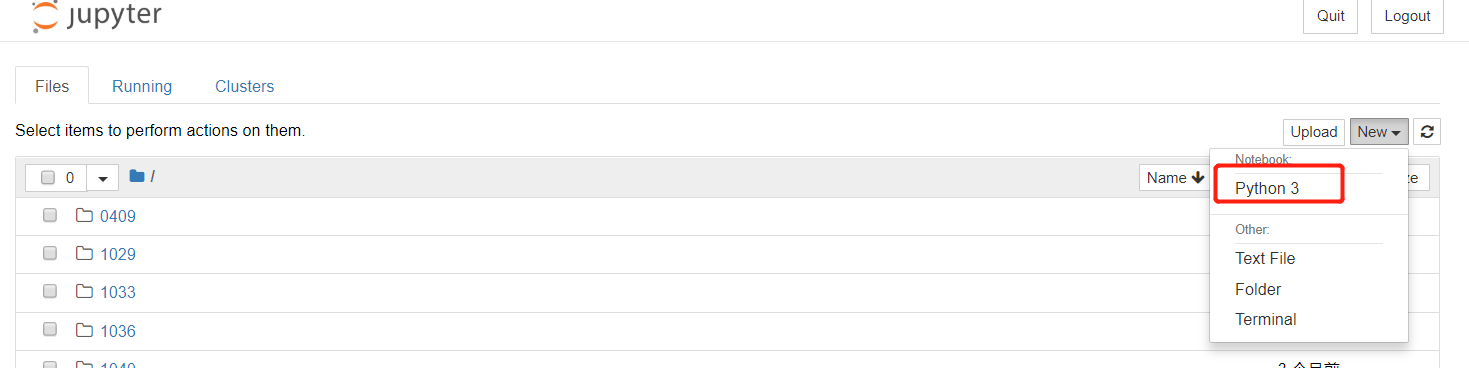
首先:新建一个python3文件
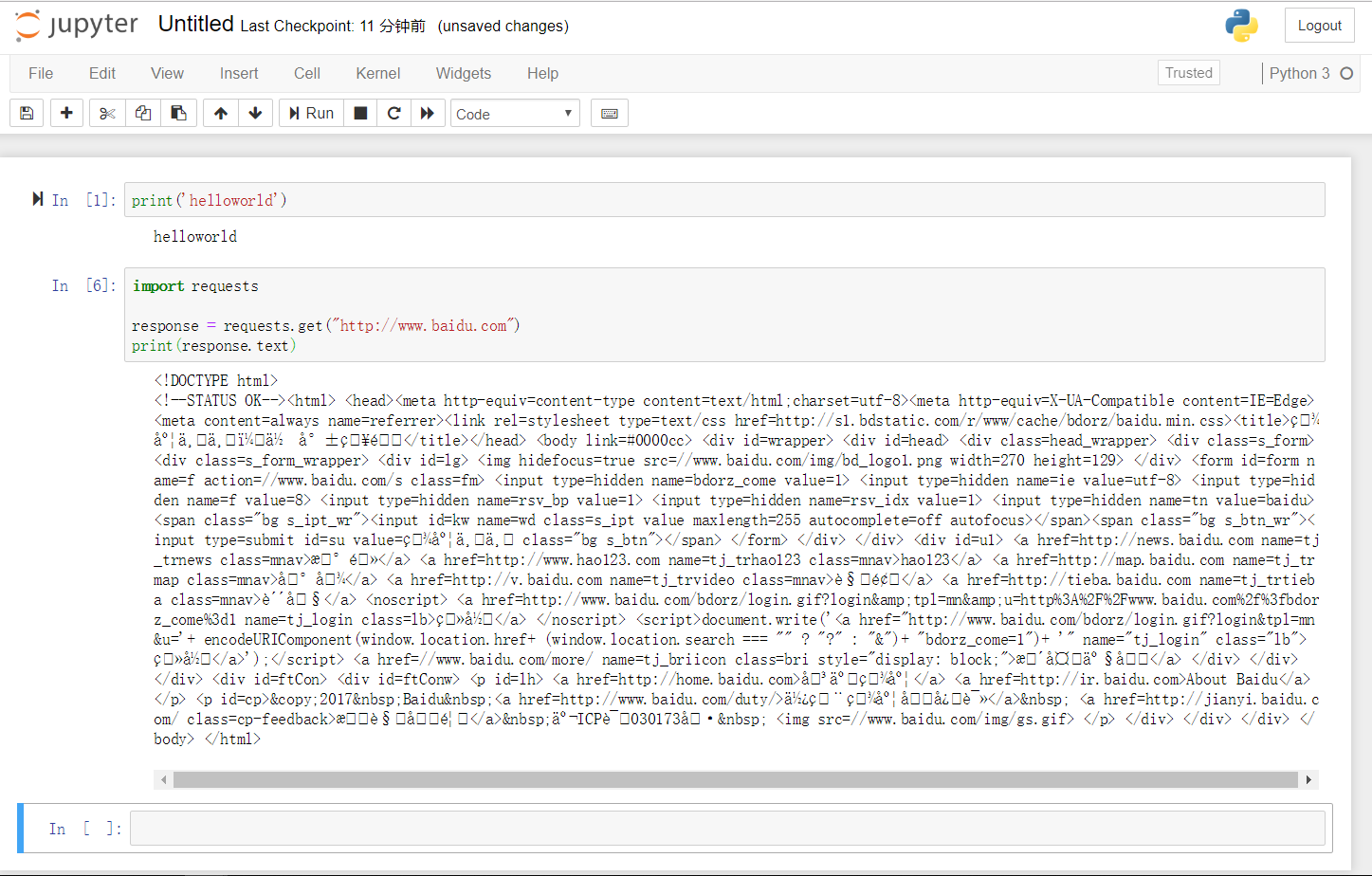
编写代码:
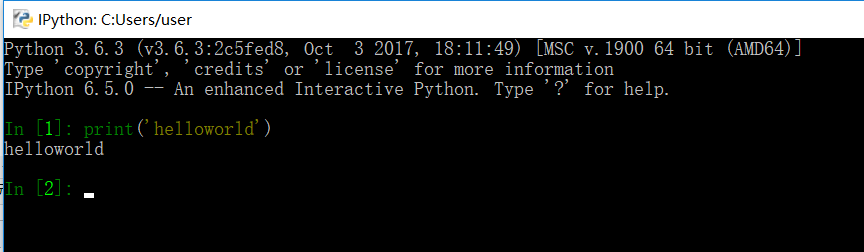
2、在命令行输入:ipython
这种方式会在命令行进行编写
Linux和Mac下安装
直接输入命令:
pip3 install selenium beautifulsoup4 pyquery pymysql pymongo redis flask django jupyter
验证方法和windows下一样。
python爬虫知识点总结(一)库的安装的更多相关文章
- Python爬虫--- 1.1请求库的安装与使用
来说先说爬虫的原理:爬虫本质上是模拟人浏览信息的过程,只不过他通过计算机来达到快速抓取筛选信息的目的所以我们想要写一个爬虫,最基本的就是要将我们需要抓取信息的网页原原本本的抓取下来.这个时候就要用到请 ...
- python爬虫知识点详解
python爬虫知识点总结(一)库的安装 python爬虫知识点总结(二)爬虫的基本原理 python爬虫知识点总结(三)urllib库详解 python爬虫知识点总结(四)Requests库的基本使 ...
- Python爬虫进阶三之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- python爬虫之re正则表达式库
python爬虫之re正则表达式库 正则表达式是用来简洁表达一组字符串的表达式. 编译:将符合正则表达式语法的字符串转换成正则表达式特征 操作符 说明 实例 . 表示任何单个字符 [ ] 字符集,对单 ...
- python爬虫知识点总结(六)BeautifulSoup库详解
官方学习文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/ 一.什么时BeautifulSoup? 答:灵活又方便的网页解析库,处 ...
- Python 关于 pip 部分相关库的安装
下文中“:”后面安装的安装语句需要打开 cmd (命令提示符),在 cmd 中输入. 示例: 在搜索框输入 cmd,单机命令提示符: 然后输入安装语句,按回车键: 因为我之前已经装过了,所以这里显示的 ...
- Python爬虫入门教程 1-100 CentOS环境安装
简介 你好,当你打开这个文档的时候,我知道,你想要的是什么! Python爬虫,如何快速的学会Python爬虫,是你最期待的事情,可是这个事情应该没有想象中的那么容易,况且你的编程底子还不一定好,这套 ...
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫入门之Urllib库的基本使用
那么接下来,小伙伴们就一起和我真正迈向我们的爬虫之路吧. 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解 ...
随机推荐
- ArcMap中使用ArcPy实现Geometry与WKT的相互转换
在Web GIS迅猛发展的今天,使用浏览器来进行交互以其方便性.快捷性被广大用户所推崇,那么在传输格式方面,都已比較简单的JSON或者WKT来解决网络带宽带来的数据压力. 在ArcGIS10.2版本号 ...
- JavaOne2013 开发者大会
参加完JavaOne 2013开发者大会,把听的东西总结一下,基本上是介绍Java的最新发展情况,和对未来的展望. 现在全球有9 million 的Java开发人员,Java语言除了在传统的Enter ...
- uboot之bootm以及go命令的实现
本文档简单介绍了uboot中用于引导内核的命令bootm的实现,同时分析了uImage文件的格式,还简单看了一下uboot下go命令的实现 作者: 彭东林 邮箱: pengdonglin137@163 ...
- vsftpd 虚拟用户限定在虚拟用户目录
1.安装vsftpd yum -y install pam pam-devel db4 db4-tcl vsftpd 2.更名默认配置文件,以便恢复 cp /etc/vsftpd/vsftpd.con ...
- Java过滤特殊字符
Java正则表达式过滤 1.Java过滤特殊字符的正则表达式----转载 java过滤特殊字符的正则表达式[转载] 2010-08-05 11:06 Java过滤特殊字符的正则表达式 关键字: j ...
- 关于proplists:get_value/2 与lists:keyfind/3 的效率比较
关于proplists:get_value/2 与lists:keyfind/2 的效率 早有比较,已出结论,lists:keyfind/2 的效率要好很多,好些人都是直接用或者做过它们之间的比较测试 ...
- 【caffe】Caffe的Python接口-官方教程-01-learning-Lenet-详细说明(含代码)
01-learning-Lenet, 主要讲的是 如何用python写一个Lenet,以及用来对手写体数据进行分类(Mnist).从此教程可以知道如何用python写prototxt,知道如何单步训练 ...
- ElasticSearch架构思考(转)
一个ElasticSearch集群需要多少个节点很难用一种明确的方式回答,但是,我们可以将问题细化成一下几个,以便帮助我们更好的了解,如何去设计ElasticSearch节点的数目: 打算处理多少数据 ...
- 升级webapi依赖的Newtonsoft.json的版本(转)
随着微软日渐重视开源社区的贡献,微软在自己的产品中往往也会集成开源的第三方库. 比如System.Net.Http.Foramatting.dll 就依赖于Newtonsoft.json v4.5. ...
- Html控件和Web控件(转)
作为一名ASP.NET的初学者,了解并且区别一些混淆概念是很必须的,今天这篇博文 就是主要向大家介绍一下Html控件和Web控件.在ASP.net中,用户界面控件主要就是 Html控件和Web控件,在 ...