python爬虫知识点总结(一)库的安装
环境要求:
1、编程语言版本python3;
2、系统:win10;
3、浏览器:Chrome68.0.3440.75;(如果不是最新版有可能影响到程序执行)
4、chromedriver2.41
注意点:pip3 install 命令必须在管理员权限下才能有效下载!
一、安装python3
不是本文重点,初学者,建议上百度搜索,提供几个思路:
1、官网:https://www.python.org/
IDE:pycharm
2、anaconda安装后自带python
等等。
二、配置环境变量
需要配置的路径有两个
1、python.exe所在路径(python所在)
2、Script文件夹下的路径(pip所在)
三、爬虫常用库的安装
(1)requests库
管理员运行cmd。
输入命令:pip3 install requests
测试:在cmd下运行一下代码实例测试:
import requests
requests.get('http://www.baidu.com')
结果如图:

(2)selenium库
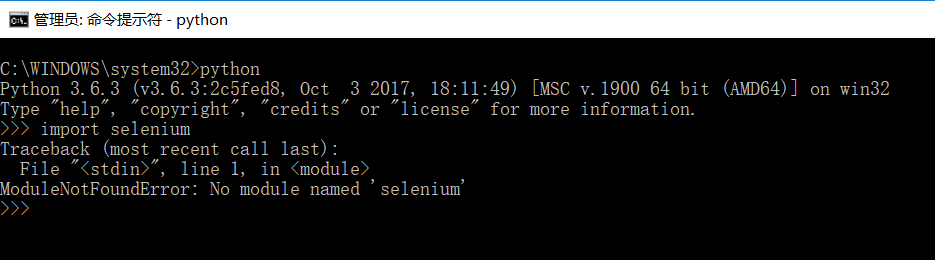
先检查selenium在本地有没有。
和上面的图操作一样,进到python->输入import selenium
如果没安装,会报错,如下图:
在cmd下输入命令:pip3 install selenium
安装结果如下图:

尝试运行代码实例:
import selenium
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
driver.page_source
会报错:

因为本地没有Chromdriver,需要下载,下载最新版就可以了
http://npm.taobao.org/mirrors/chromedriver/
将chromedriver.exe放到python.exe文件夹下,或者Scripts文件夹下(本质是环境变量配置,方便python找到)
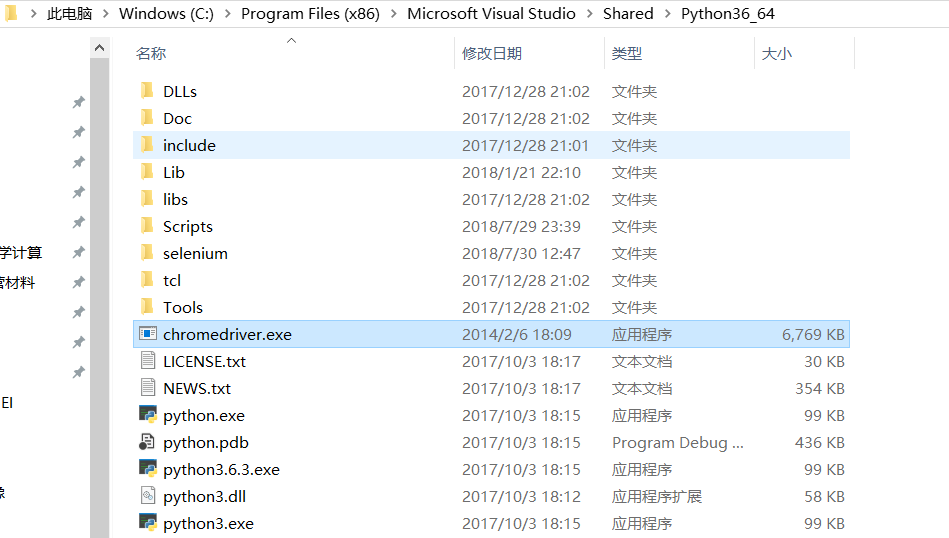
在cmd下输入命令:chromedriver
再次运行代码实例,如果出错如下,那就看我的这篇博客:
https://www.cnblogs.com/cthon/p/9390095.html
https://www.cnblogs.com/cthon/p/9390998.html
其本质是,chrome版本和webdriver不一致,一定记住下载最新版本的chrome

正确的执行结果应该是:
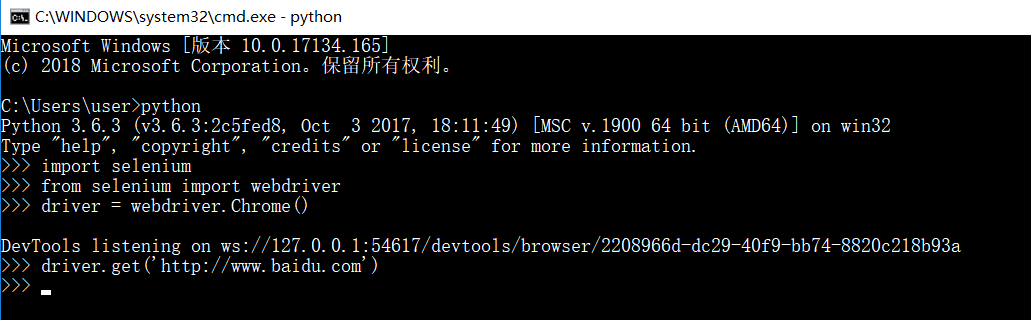
执行成功会自动弹出Google浏览器并进入百度界面

(3)phantomjs(无界面浏览器)
下载链接:http://phantomjs.org/download.html
解压后,配置环境变量phantomjs

检查是否配置成功
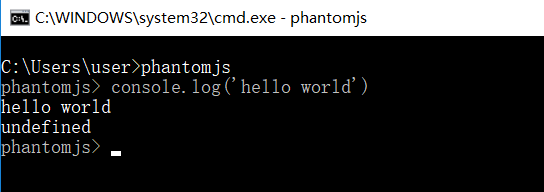
代码实例测试:
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get("http://www.baidu.com")
driver.page_source
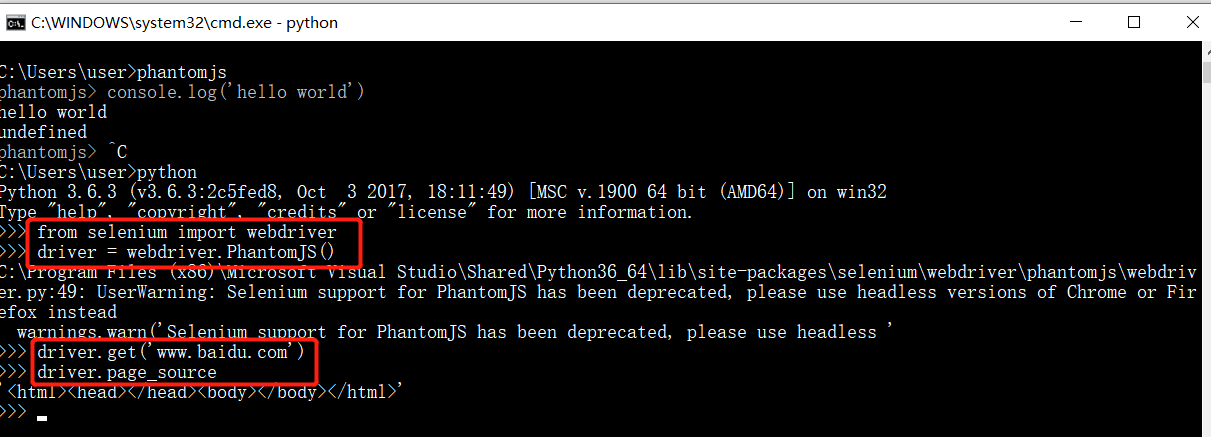
(4)lxml库
在cmd下,输入命令:pip3 install lxml
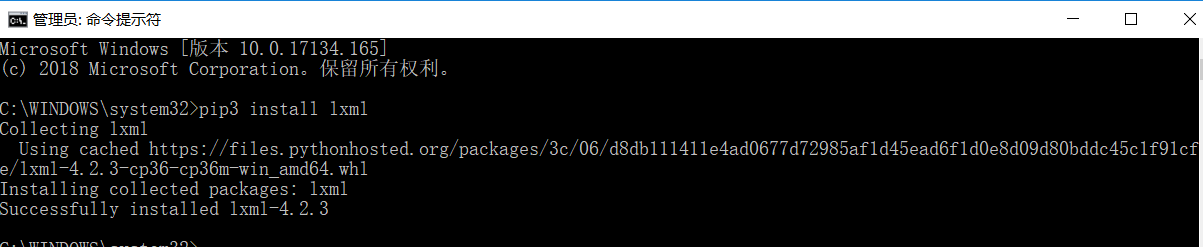
(5)beautifulsoup库
在cmd下,输入命令:pip3 install beautifulsoup4
有可能会爆出找不到该版本的错误信息,那就通过下载链接:https://www.crummy.com/software/BeautifulSoup/bs4/download/

运行代码示例:
from bs4 import BeautifulSoup
soup = BeautifulSoup('<html></html>','lxml')

(6)pyquery库(和beautifulsoup一样是网页解析库,个人觉得比较方便)
官方学习:https://pythonhosted.org/pyquery/
在cmd下,输入命令:pip3 install pyquery
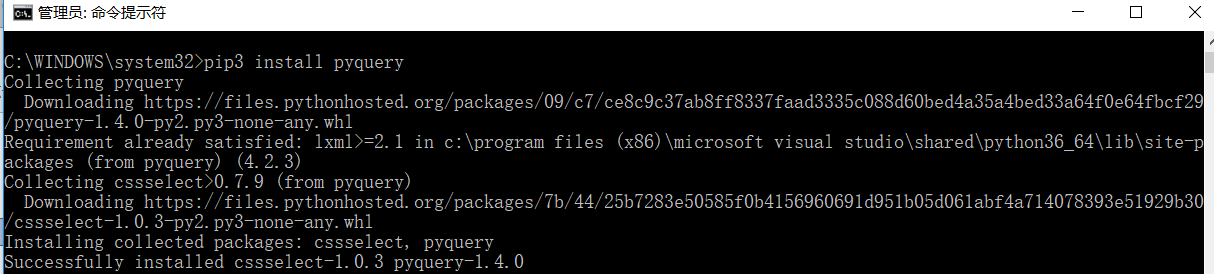
运行代码实例:
from pyquery import PyQuery as pq
doc = pq('<html></html>')
doc = pq('<html>hello</html>')
result = doc('html').text()
result
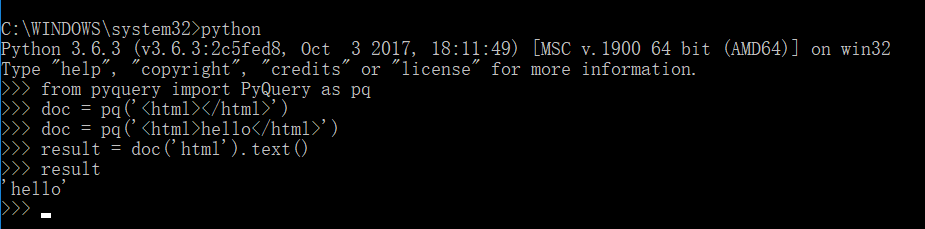
(7)pymysql库(操作mysql)
在cmd下,输入命令:pip3 install pymysql
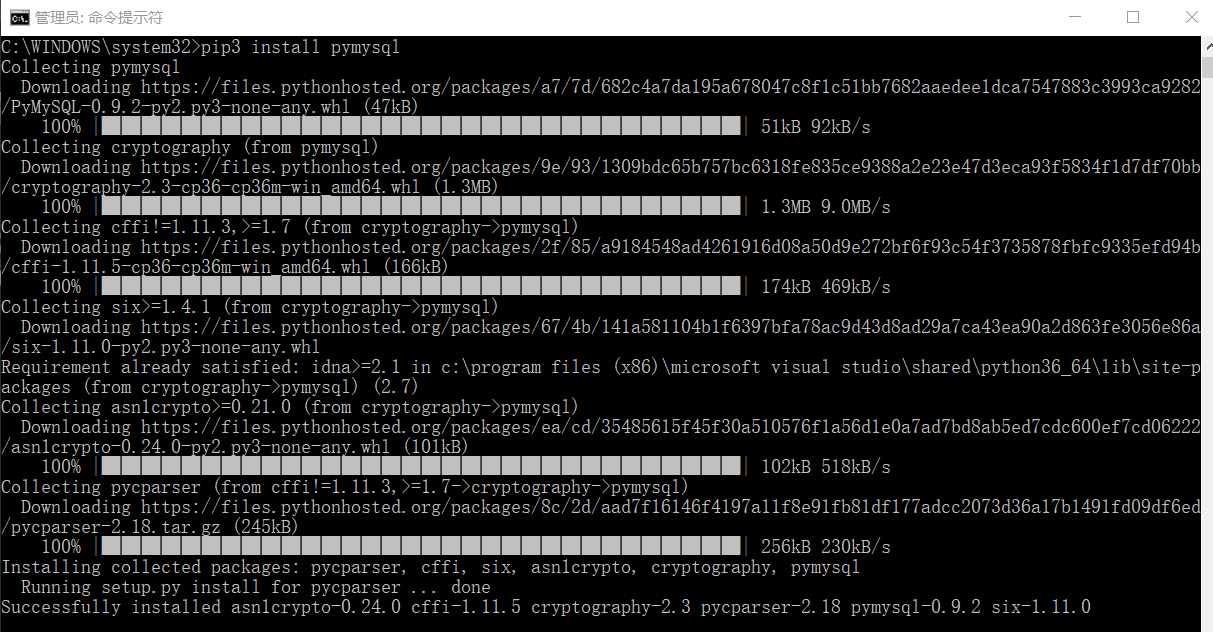
运行代码实例:
import pymysql
conn = pymysql.connect(host='localhost',user='root',password='root',port=,db='mysql')
cursor = conn.cursor()
cursor.execute('select * from db')
cursor.fetchone()
cursor.execute('select * from myuser')
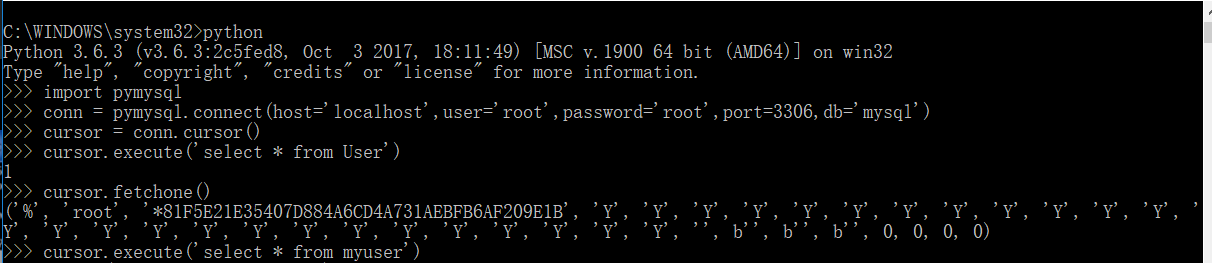
对比一下,mysql的数据

(8)pymongo库(操作mongodb)--key-value型,数据存储很方便,不需要建表,可以动态增加一些键名
在cmd下,输入命令:pip3 install pymongo

输入代码实例:
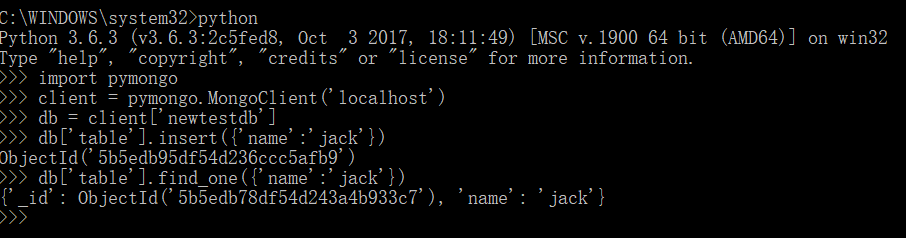
import pymongo
client = pymongo.MongoClient('localhost')
db = client['newtestdb']
db['table'].insert({'name':'jack'})
db['table'].find_one({'name':'jack'})
(9)redis库(操作redis)--key-value型,用在分布式爬虫,维护爬取队列,效果比较理想
在cmd下:输入命令:pip3 install redis

运行代码实例:
import redis
r = redis.Redis('localhost',)
r.set('name','jack')
r.get('name')

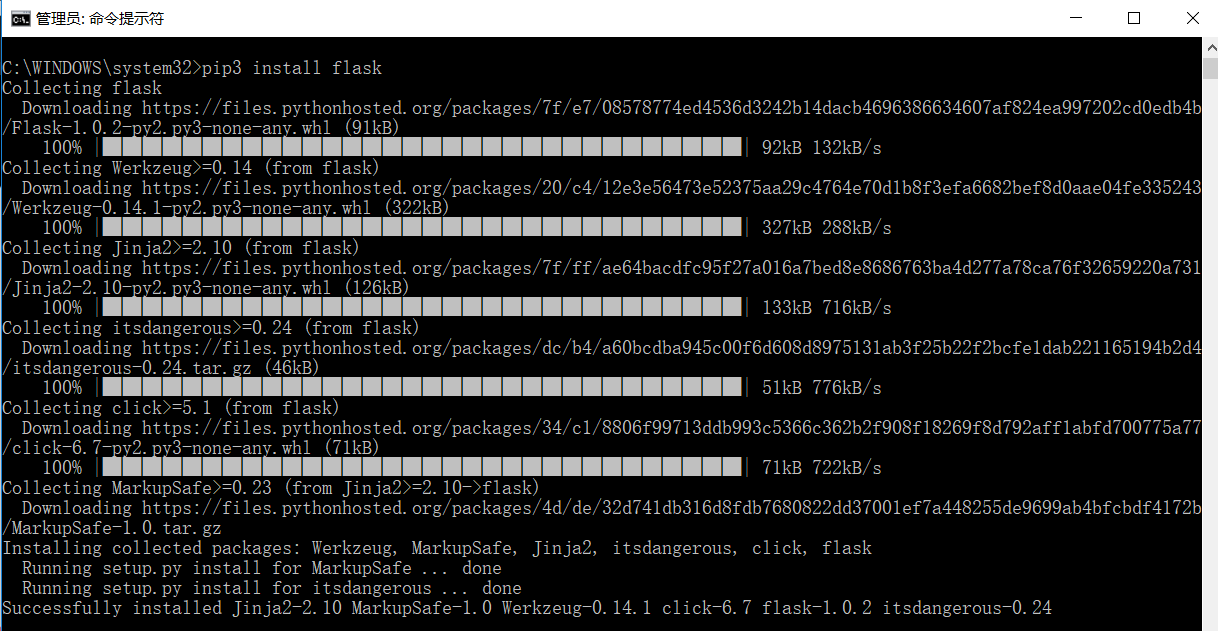
(10)flask库(web库,在做一些代理的设置时需要用到,用来设置一些代理的获取和存储)
官方文档:http://www.pythondoc.com/flask/index.html
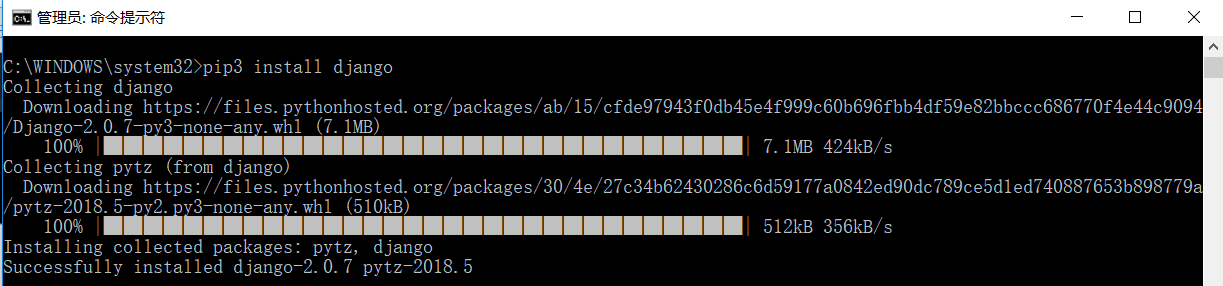
(11)django库(web服务器框架,提供了服务器后台管理,模板引擎,接口,路由,用于分布式爬虫的维护)
官方文档:https://docs.djangoproject.com/en/2.0/
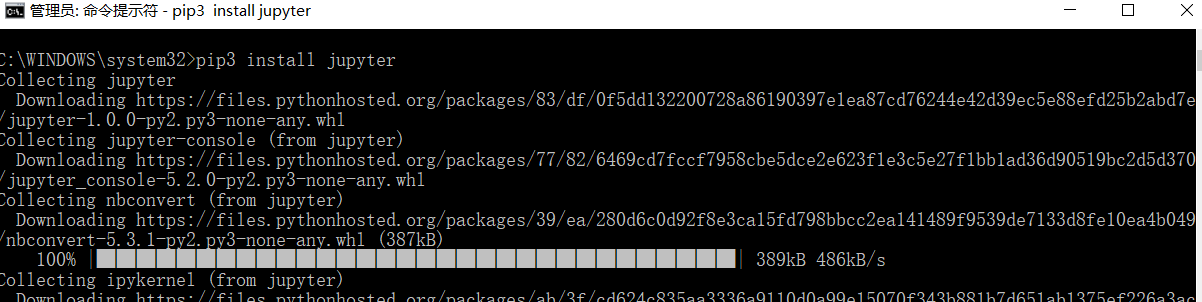
(12)jupyter库(相当于notebook,用来编写代码记录)
官方文档:https://jupyter.org/documentation
在cmd下,输入命令:pip3 install jupyter
内容很多,我就不全部截图了,正确运行就可以了。
jupyter的启动方法有两个:
1、在命令行输入:jupyter notebook
会在浏览器中弹出一个网页notebook 代码编辑页
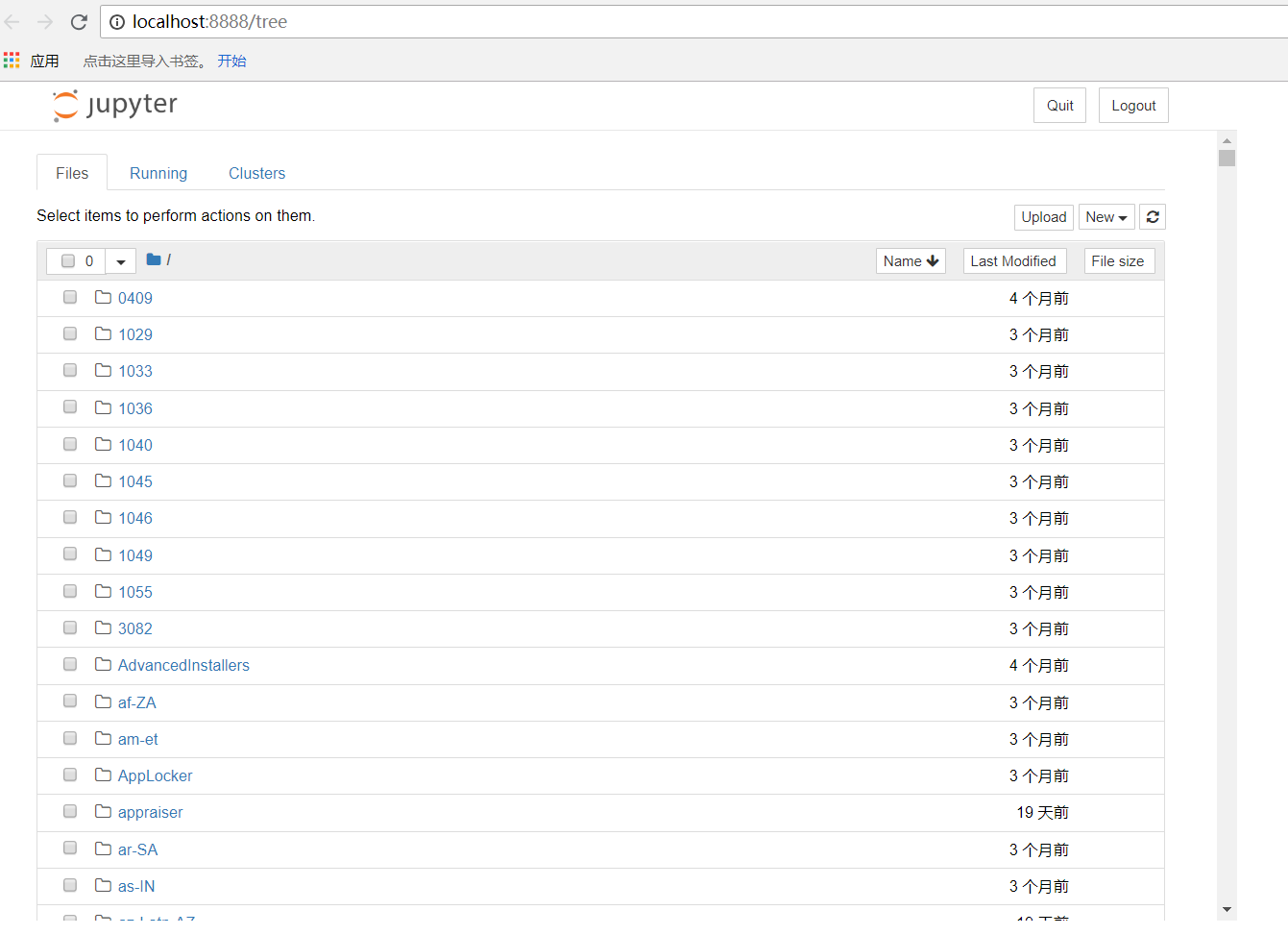
按照以下步骤可以进行代码编辑,
首先:新建一个python3文件
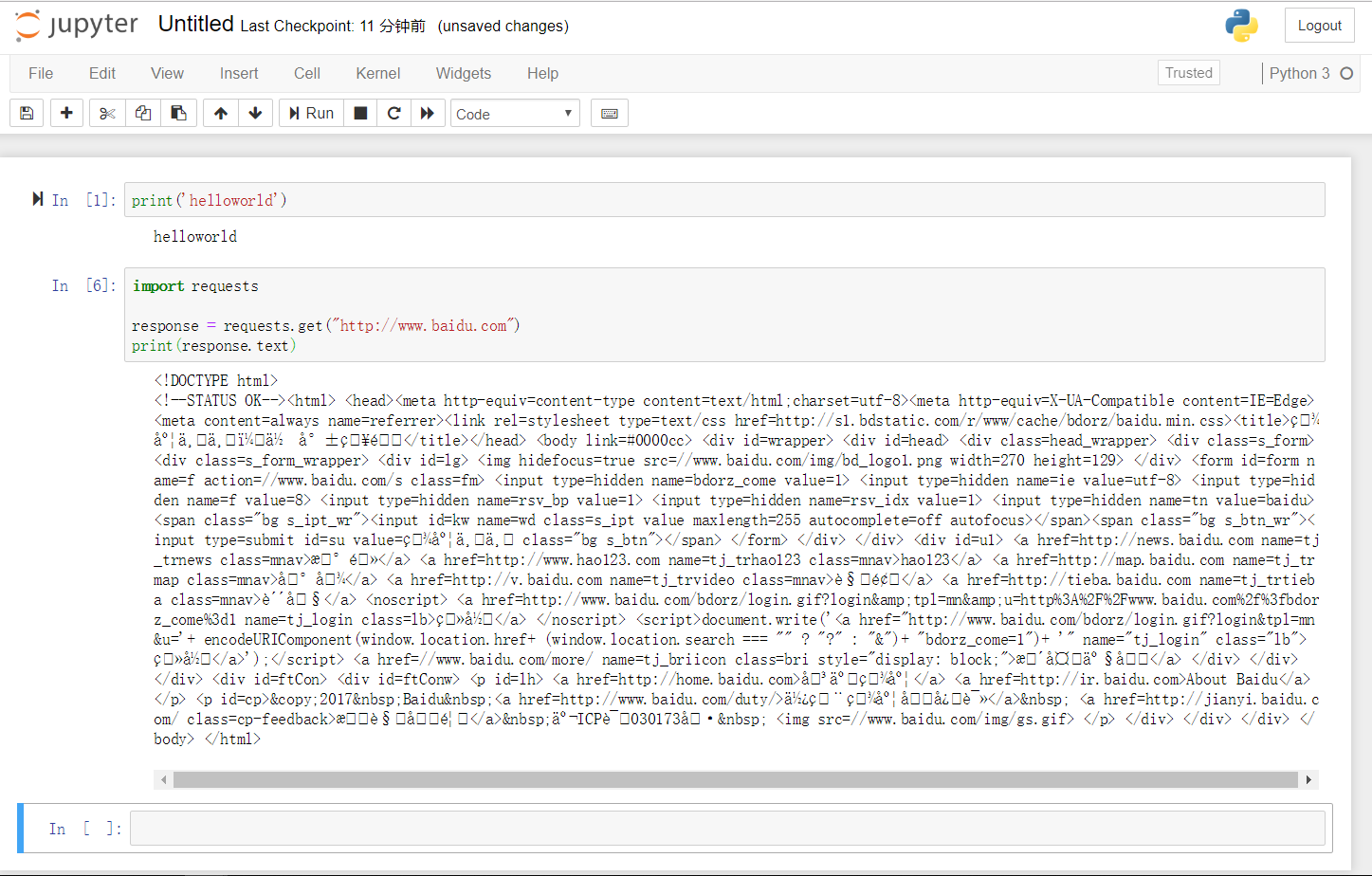
编写代码:
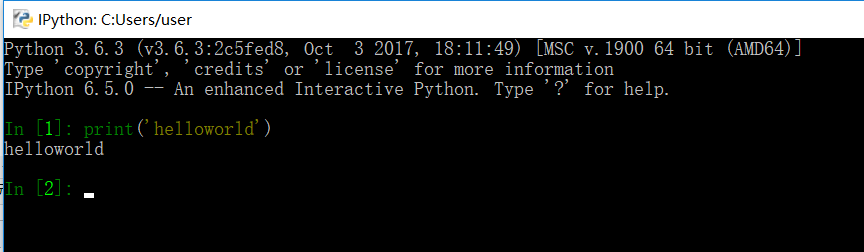
2、在命令行输入:ipython
这种方式会在命令行进行编写
Linux和Mac下安装
直接输入命令:
pip3 install selenium beautifulsoup4 pyquery pymysql pymongo redis flask django jupyter
验证方法和windows下一样。
python爬虫知识点总结(一)库的安装的更多相关文章
- Python爬虫--- 1.1请求库的安装与使用
来说先说爬虫的原理:爬虫本质上是模拟人浏览信息的过程,只不过他通过计算机来达到快速抓取筛选信息的目的所以我们想要写一个爬虫,最基本的就是要将我们需要抓取信息的网页原原本本的抓取下来.这个时候就要用到请 ...
- python爬虫知识点详解
python爬虫知识点总结(一)库的安装 python爬虫知识点总结(二)爬虫的基本原理 python爬虫知识点总结(三)urllib库详解 python爬虫知识点总结(四)Requests库的基本使 ...
- Python爬虫进阶三之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- python爬虫之re正则表达式库
python爬虫之re正则表达式库 正则表达式是用来简洁表达一组字符串的表达式. 编译:将符合正则表达式语法的字符串转换成正则表达式特征 操作符 说明 实例 . 表示任何单个字符 [ ] 字符集,对单 ...
- python爬虫知识点总结(六)BeautifulSoup库详解
官方学习文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/ 一.什么时BeautifulSoup? 答:灵活又方便的网页解析库,处 ...
- Python 关于 pip 部分相关库的安装
下文中“:”后面安装的安装语句需要打开 cmd (命令提示符),在 cmd 中输入. 示例: 在搜索框输入 cmd,单机命令提示符: 然后输入安装语句,按回车键: 因为我之前已经装过了,所以这里显示的 ...
- Python爬虫入门教程 1-100 CentOS环境安装
简介 你好,当你打开这个文档的时候,我知道,你想要的是什么! Python爬虫,如何快速的学会Python爬虫,是你最期待的事情,可是这个事情应该没有想象中的那么容易,况且你的编程底子还不一定好,这套 ...
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫入门之Urllib库的基本使用
那么接下来,小伙伴们就一起和我真正迈向我们的爬虫之路吧. 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解 ...
随机推荐
- Enumerate Combination C(k, n) in a bitset
Suppose n<=32, we can enumerate C(k, n), with bits representing absence or presence, in the follo ...
- POJ 2985 Treap平衡树(求第k大的元素)
这题也能够用树状数组做,并且树状数组姿势更加优美.代码更加少,只是这个Treap树就是求第K大元素的专家--所以速度比較快. 这个也是从那本红书上拿的模板--自己找了资料百度了好久,才理解这个Trea ...
- Django之通过tag推荐文章
#路由 views.py def post_detail(request,year,month,day,post): ''' 文章详情 + 评论详情 :param request: :param ye ...
- 搭建私有Nuget仓库
使用Nexus搭建私有Nuget仓库 https://www.cnblogs.com/Erik_Xu/p/9211471.html 前言 Nuget是ASP .NET Gallery的一员,是免费.开 ...
- Android 音频 OpenSL ES 录音 采集
1,; int channelConfig = AudioFormat.CHANNEL_OUT_STEREO; int audioFormat = AudioFormat.ENCODING_PCM_1 ...
- Grunt学习笔记【8】---- grunt-angular-templates插件详解
本文主要讲如何用Grunt打包AngularJS的模板HTML. 一 说明 AngularJS中使用单独HTML模板文件的地方非常多,例如:自定义指令.ng-include.templateUrl等. ...
- 【学员管理系统】0x01 班级信息管理功能
[学员管理系统]0x01 班级信息管理功能 写在前面 项目详细需求参见:Django项目之[学员管理系统] 视图函数: 我们把所有的处理请求相关的函数从 urls.py中拿出来,统一放在一个叫view ...
- 【JAVA学习】struts2的action中使用session的方法
尊重版权:http://hi.baidu.com/dillisbest/item/0bdc35c0b477b853ad00efac 在Struts2里,假设须要在Action中使用session.能够 ...
- 【zabbix】微信告警消息模版
下面给出了一个zabbix微信告警消息的模版, 消息最后加上#号和短横线的设计有两个原因: 1,zabbix的微信告警消息总是被截断,比如最后一个告警时间,如果没有最后一行#号,在微信上看的时候时间不 ...
- empty blank
非nil对象才能调用 empty nil: 对象是否存在empty: ”“ []blank: nil emptypresent: ! blank