海量数据中找top K专题
1. 10亿个数中找出最大的1000个数
这种题目就是分治+堆排序。
为啥分治?因为数太多了,全部加载进内存不够用,所以分配到多台机器中,或者多个文件中,但具体分成多少份,视情况而定,只要保证满足内存限制即可。什么,如何分?Hash(num)% numOfFiles。
为啥堆排序?首先堆排序是一种选择排序,比一般的选择排序时间复杂度要低,额外的空间复杂度都是O(1)。因为我只要在每一份中拿出最大的1000个即可,这里用大顶堆还是小顶堆呢?
开始我觉得是大顶堆,我们不妨举个例子:假设10亿个数,分成若干组,每组假设1000000,我们所要做的,就是在这1000000的个数中,找出前1000。如果采用大顶堆,意味着我们需要构建1000000节点的一个大树,然后调整找出前1000,就是根嘛。但是你不觉得这个树太大了吗?而要是小顶堆呢?我只要构建一个1000节点的树即可,这样我从剩余元素中拿出来和根比较,如果比根小直接舍弃,如果比根大,替换根的位置,然后重新调整堆,这样最后这1000个节点就是最大的。
最后把每一份中的1000个最大的数合在一起找最终结果就够了(可以继续用堆排序查找),有没有觉得这个就是mapReduce的Shuffle的思想,如果不了解建议看一下我的另一篇博客:http://www.cnblogs.com/DarrenChan/p/6477088.html,不同的是Shuffle中合并排序采用的是归并排序。

堆排序讲解,请参考:https://www.cnblogs.com/chengxiao/p/6129630.html
2. 10亿个数中找出出现频率最高的1000个数
这道题和上道题本质相同,通常比较好的方案是分治+Trie树/hash+堆排序,即先将数据集按照Hash方法分解成多个小数据集,然后使用Trie树或者Hash统计每个数字的词频,之后用堆排序求出每个数据集中出现频率最高的前K个数,最后再合并求最终的top K。
3. 10亿个数中找出某个数
我刚开始的想法是分治+排序,然后每个二分查找,可是感觉还是复杂度蛮高的。
后来突然想到MySQL数据库中的索引,就想成给主键建立索引,然后查找主键不就好了吗?
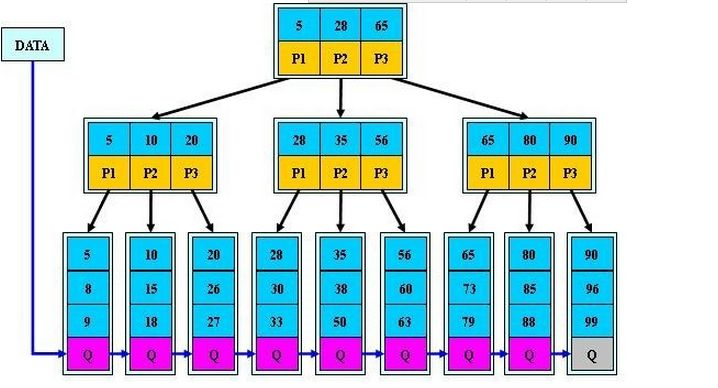
参考InnoDB数据库索引的思路,建立一个主键索引,这里不用建立辅助索引了,因为你只有主键,哈哈~然后索引通过B+树进行存储,为什么采用B+树,主要为了减少IO次数,为啥不用B-树(B树),额,定义上好像说了,请看:
B+树是B树的一个升级版,相对于B树来说B+树更充分的利用了节点的空间,让查询速度更加稳定,其速度完全接近于二分法查找。为什么说B+树查找的效率要比B树更高、更稳定;我们先看看两者的区别:
(1)B+跟B树不同B+树的非叶子节点不保存关键字记录的指针,这样使得B+树每个节点所能保存的关键字大大增加;
(2)B+树叶子节点保存了父节点的所有关键字和关键字记录的指针,每个叶子节点的关键字从小到大链接;
(3)B+树的根节点关键字数量和其子节点个数相等;
(4)B+的非叶子节点只进行数据索引,不会存实际的关键字记录的指针,所有数据地址必须要到叶子节点才能获取到,所以每次数据查询的次数都一样;
特点:
在B树的基础上每个节点存储的关键字数更多,树的层级更少所以查询数据更快,所有指关键字指针都存在叶子节点,所以每次查找的次数都相同所以查询速度更稳定;
具体参见:https://zhuanlan.zhihu.com/p/27700617
这样我们就可以通过索引在叶子节点查询到我们的数字了。
参考:https://blog.csdn.net/zyq522376829/article/details/47686867
海量数据中找top K专题的更多相关文章
- 海量数据中找出前k大数(topk问题)
海量数据中找出前k大数(topk问题) 前两天面试3面学长问我的这个问题(想说TEG的3个面试学长都是好和蔼,希望能完成最后一面,各方面原因造成我无比想去鹅场的心已经按捺不住了),这个问题还是建立最小 ...
- 17082 两个有序数序列中找第k小
17082 两个有序数序列中找第k小 时间限制:1000MS 内存限制:65535K 提交次数:0 通过次数:0 题型: 编程题 语言: 无限制 Description 已知两个已经排好序(非减 ...
- 17082 两个有序数序列中找第k小(优先做)
17082 两个有序数序列中找第k小(优先做) 时间限制:1000MS 内存限制:65535K提交次数:0 通过次数:0 题型: 编程题 语言: G++;GCC;VC Description 已 ...
- 17082 两个有序数序列中找第k小(优先做) O(logn)
17082 两个有序数序列中找第k小(优先做) 时间限制:1000MS 内存限制:65535K提交次数:0 通过次数:0 题型: 编程题 语言: G++;GCC;VC Description 已 ...
- pig中查询top k,返回每个hour和ad_network_id下最大两个记录(SUBSTRING,order,COUNT_STAR,limit)
pig里面是有TOP函数,不知道为什么用不了.有时间要去看看pig源码了. SET job.name 'top_k'; SET job.priority HIGH; --REGISTER piggyb ...
- 基于visual Studio2013解决面试题之0302链表中找倒数k项节点
题目
- 解决面试问题中的top k问题 Leetcode
https://leetcode.com/problems/kth-largest-element-in-an-array/ 使用堆,堆插入一个数据是logk,删除一个数据是logk,复杂度为logk ...
- 海量数据处理 - 10亿个数中找出最大的10000个数(top K问题)
前两天面试3面学长问我的这个问题(想说TEG的3个面试学长都是好和蔼,希望能完成最后一面,各方面原因造成我无比想去鹅场的心已经按捺不住了),这个问题还是建立最小堆比较好一些. 先拿10000个数建堆, ...
- 如何解决海量数据的Top K问题
1. 问题描述 在大规模数据处理中,常遇到的一类问题是,在海量数据中找出出现频率最高的前K个数,或者从海量数据中找出最大的前K个数,这类问题通常称为“top K”问题,如:在搜索引擎中,统计搜索最热门 ...
随机推荐
- 启动Azure模拟器出错解决方案
错误弹窗: 输出控制台: Microsoft Azure Tools: Warning: Overriding public port 80 to 2888 in role 'WebRole1'. M ...
- C# GUID生成
System.Guid.NewGuid().ToString()
- psssss test
我觉得我不该写博客了
- POJ.3537.Crosses and Crosses(博弈论 Multi-SG)
题目链接 \(Description\) 有一个一行n列的棋盘,每个人每次往上放一个棋子,将三个棋子连在一起的人赢.问是否有必胜策略. \(Solution\) 首先一个人若在\(i\)处放棋子,那么 ...
- 洛谷.3690.[模板]Link Cut Tree(动态树)
题目链接 LCT(良心总结) #include <cstdio> #include <cctype> #include <algorithm> #define gc ...
- Python获取系统音量
1,如果是windows下 试试这个python 模块winsoundhttp://docs.python.org/2/library/winsound.html这个也可以winmm调整windows ...
- node+koa2 使用ejs模版
1.进入项目下,npm install -save ejs 2.app.js加入: const ejs = require('ejs'); app.use(views(__dirname + '/vi ...
- git 删除分支 远程 && 本地
//查看远程分支 git branch -a //删除远程分支 git branch -r -d origin/branch-name git push origin :branch-name// 或 ...
- adblock 下载地址
addblock 的作用: 防止追踪.恶意域名,过滤横幅广告.弹窗广告以及视频广告. 用以支持网站的非侵入式广告将不会被屏蔽 下载地址:https://pan.baidu.com/share/li ...
- Java中使用Timer和TimerTask实现多线程
转自:http://www.bdqn.cn/news/201305/9303.shtml 摘要:Timer是一种线程设施,用于安排以后在后台线程中执行的任务.可安排任务执行一次,或者定期重复执行,可以 ...