Docker 搭建Spark 依赖singularities/spark:2.2镜像
singularities/spark:2.2版本中
Hadoop版本:2.8.2
Spark版本: 2.2.1
Scala版本:2.11.8
Java版本:1.8.0_151
拉取镜像:
[root@localhost docker-spark-2.1.]# docker pull singularities/spark
查看:
[root@localhost docker-spark-2.1.]# docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/singularities/spark latest 84222b254621 months ago 1.39 GB
创建docker-compose.yml文件
[root@localhost home]# mkdir singularitiesCR
[root@localhost home]# cd singularitiesCR
[root@localhost singularitiesCR]# touch docker-compose.yml
内容:
version: "" services:
master:
image: singularities/spark
command: start-spark master
hostname: master
ports:
- "6066:6066"
- "7070:7070"
- "8080:8080"
- "50070:50070"
worker:
image: singularities/spark
command: start-spark worker master
environment:
SPARK_WORKER_CORES:
SPARK_WORKER_MEMORY: 2g
links:
- master
执行docker-compose up即可启动一个单工作节点的standlone模式下运行的spark集群
[root@localhost singularitiesCR]# docker-compose up -d
Creating singularitiescr_master_1 ... done
Creating singularitiescr_worker_1 ... done
查看容器:
[root@localhost singularitiesCR]# docker-compose ps
Name Command State Ports
--------------------------------------------------------------------------------------------------------------------------------------------------------
singularitiescr_master_1 start-spark master Up /tcp, /tcp, /tcp, /tcp, /tcp, /tcp,
0.0.0.0:->/tcp, /tcp, /tcp, /tcp, /tcp,
0.0.0.0:->/tcp, 0.0.0.0:->/tcp, /tcp, /tcp,
0.0.0.0:->/tcp, /tcp, /tcp
singularitiescr_worker_1 start-spark worker master Up /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp,
/tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp, /tcp,
/tcp
查看结果:

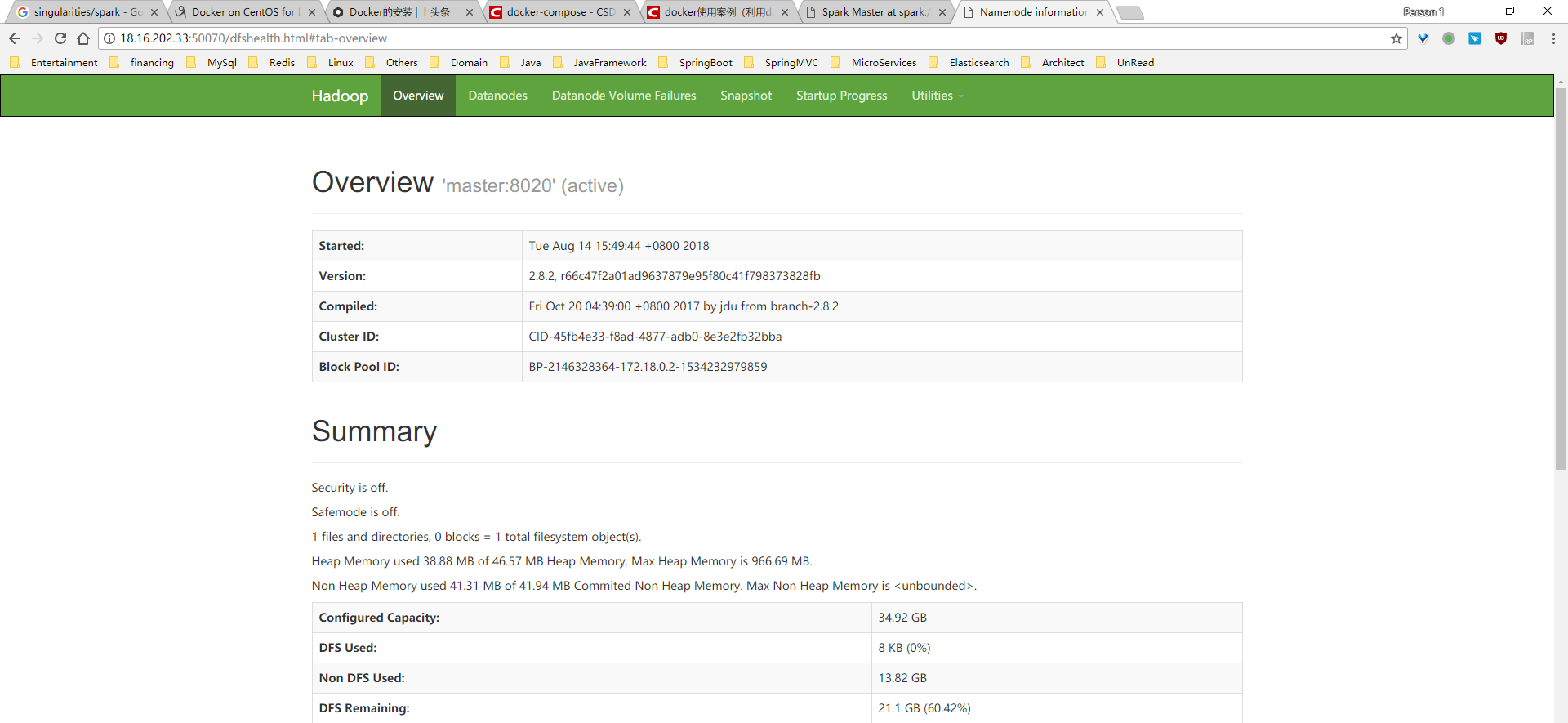
停止容器:
[root@localhost singularitiesCR]# docker-compose stop
Stopping singularitiescr_worker_1 ... done
Stopping singularitiescr_master_1 ... done
[root@localhost singularitiesCR]# docker-compose ps
Name Command State Ports
-----------------------------------------------------------------------
singularitiescr_master_1 start-spark master Exit
singularitiescr_worker_1 start-spark worker master Exit
删除容器:
[root@localhost singularitiesCR]# docker-compose rm
Going to remove singularitiescr_worker_1, singularitiescr_master_1
Are you sure? [yN] y
Removing singularitiescr_worker_1 ... done
Removing singularitiescr_master_1 ... done
[root@localhost singularitiesCR]# docker-compose ps
Name Command State Ports
------------------------------
进入master容器查看版本:
[root@localhost singularitiesCR]# docker exec -it /bin/bash
root@master:/# hadoop version
Hadoop 2.8.
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 66c47f2a01ad9637879e95f80c41f798373828fb
Compiled by jdu on --19T20:39Z
Compiled with protoc 2.5.
From source with checksum dce55e5afe30c210816b39b631a53b1d
This command was run using /usr/local/hadoop-2.8./share/hadoop/common/hadoop-common-2.8..jar
root@master:/# which is hadoop
/usr/local/hadoop-2.8./bin/hadoop
root@master:/# spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://172.18.0.2:4040
Spark context available as 'sc' (master = local[*], app id = local-).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.
/_/ Using Scala version 2.11. (OpenJDK -Bit Server VM, Java 1.8.0_151)
Type in expressions to have them evaluated.
Type :help for more information.
参考:
https://github.com/SingularitiesCR/spark-docker
https://blog.csdn.net/u013705066/article/details/80030732
Docker 搭建Spark 依赖singularities/spark:2.2镜像的更多相关文章
- Docker 搭建Spark 依赖sequenceiq/spark:1.6镜像
使用Docker-Hub中Spark排行最高的sequenceiq/spark:1.6.0. 操作: 拉取镜像: [root@localhost home]# docker pull sequence ...
- docker搭建本地仓库并制作自己的镜像
原文地址https://blog.csdn.net/junmoxi/article/details/80004796 1. 搭建本地仓库1.1 下载仓库镜像1.2 启动仓库容器2. 在CentOS容器 ...
- 用Docker搭建RabbitMq的普通集群和镜像集群
普通集群:多个节点组成的普通集群,消息随机发送到其中一个节点的队列上,其他节点仅保留元数据,各个节点仅有相同的元数据,即队列结构.消费者消费消息时,会从各个节点拉取消息,如果保存消息的节点故障,则无法 ...
- 使用 docker 搭建 nginx+php-fpm 环境 (两个独立镜像)
:first-child{margin-top:0!important}.markdown-body>:last-child{margin-bottom:0!important}.markdow ...
- Mac下docker搭建lnmp环境 + redis + elasticsearch
之前在windows下一直使用vagrant做开发, 团队里面也是各种开发环境,几个人也没有统一环境,各种上线都是人肉,偶尔还会有因为开发.测试.生产环境由于软件版本或者配置不一致产生的问题, 今年准 ...
- docker搭建elasticsearch、kibana,并集成至spring boot
步骤如下: 一.基于docker搭建elasticsearch环境 1.拉取镜像 docker pull elasticsearch5.6.8 2.制作elasticsearch的配置文件 maste ...
- 使用Docker搭建Spark集群(用于实现网站流量实时分析模块)
上一篇使用Docker搭建了Hadoop的完全分布式:使用Docker搭建Hadoop集群(伪分布式与完全分布式),本次记录搭建spark集群,使用两者同时来实现之前一直未完成的项目:网站日志流量分析 ...
- Docker搭建大数据集群 Hadoop Spark HBase Hive Zookeeper Scala
Docker搭建大数据集群 给出一个完全分布式hadoop+spark集群搭建完整文档,从环境准备(包括机器名,ip映射步骤,ssh免密,Java等)开始,包括zookeeper,hadoop,hiv ...
- Spark认识&环境搭建&运行第一个Spark程序
摘要:Spark作为新一代大数据计算引擎,因为内存计算的特性,具有比hadoop更快的计算速度.这里总结下对Spark的认识.虚拟机Spark安装.Spark开发环境搭建及编写第一个scala程序.运 ...
随机推荐
- Java -- 深入浅出GC自动回收机制
1,去年开春去美团和58同城面试的时候第一个问题基本上都是来说说 Java GC机制,当时年轻的我也很耿直,直接说不会,现在想想还是当时年轻啊.刚好这段时间被各大论坛的面试题刷屏,见到最多的也是也是这 ...
- Steam API调试
概览 经过这些年,Steam 已经成长为一款大型应用程序,提供多款调试用单独模块及方法.本文将尽量向您呈现这些模块与方法,帮助您充分利用 Steam 与 Steamworks,减少烦恼. Steam ...
- 利用JavaCSV API来读写csv文件
http://blog.csdn.net/loongshawn/article/details/53423121 http://javacsv.sourceforge.net/ 转载请注明来源-作者@ ...
- GJP_Project
1. view层作用: 视图层,即项目中的界面 l controller层作用: 控制层, 获取界面上的数据,为界面设置数据; 将要实现的功能交给业务层处理 l service层作用: 业务层, ...
- [转载]基于UML的需求分析和系统设计(完整案例和UML图形演示)
小序: 从学生时代就接触到UML,几年的工作中也没少使用,各种图形的概念.图形的元素和属性,以及图形的画法都不能说不熟悉.但是怎样在实际中有效地使用UML使之发挥应有的作用,怎样捕捉用户心中的需求并转 ...
- <转>jmeter(十二)关联之正则表达式提取器
本博客转载自:http://www.cnblogs.com/imyalost/category/846346.html 个人感觉不错,对jmeter讲解非常详细,担心以后找不到了,所以转发出来,留着慢 ...
- MySQL性能测试工具sysbench的安装和使用
sysbench是一个开源的.模块化的.跨平台的多线程性能测试工具,可以用来进行CPU.内存.磁盘I/O.线程.数据库的性能测试.目前支持的数据库有MySQL.Oracle和PostgreSQL.当前 ...
- linux grep 正则表达式
grep正则表达式元字符集: ^ 锚定行的开始 如:'^grep'匹配所有以grep开头的行. $ 锚定行的结束 如:'grep$'匹配所有以grep结尾的行. . 匹配一个非换行符的字符 如:'gr ...
- html5的理解
1.良好的移动性,以移动设备为主 2.响应式设计,以适应自动变化的屏幕尺寸 3.支持离线缓存技术,webStorage本地缓存 4.新增canvas.video.audio等新标签元素,新增特殊内容元 ...
- Eclipse在Debug模式下经常进入ThreadPoolExecutor解决办法
1.进入Window-->搜索:debug