剖析Hadoop和Spark的Shuffle过程差异
一、前言
对于基于MapReduce编程范式的分布式计算来说,本质上而言,就是在计算数据的交、并、差、聚合、排序等过程。而分布式计算分而治之的思想,让每个节点只计算部分数据,也就是只处理一个分片,那么要想求得某个key对应的全量数据,那就必须把相同key的数据汇集到同一个Reduce任务节点来处理,那么Mapreduce范式定义了一个叫做Shuffle的过程来实现这个效果。
二、编写本文的目的
本文旨在剖析Hadoop和Spark的Shuffle过程,并对比两者Shuffle的差异。
三、Hadoop的Shuffle过程
Shuffle描述的是数据从Map端到Reduce端的过程,大致分为排序(sort)、溢写(spill)、合并(merge)、拉取拷贝(Copy)、合并排序(merge sort)这几个过程,大体流程如下:
上图的Map的输出的文件被分片为红绿蓝三个分片,这个分片的就是根据Key为条件来分片的,分片算法可以自己实现,例如Hash、Range等,最终Reduce任务只拉取对应颜色的数据来进行处理,就实现把相同的Key拉取到相同的Reduce节点处理的功能。下面分开来说Shuffle的的各个过程。
Map端做了下图所示的操作:
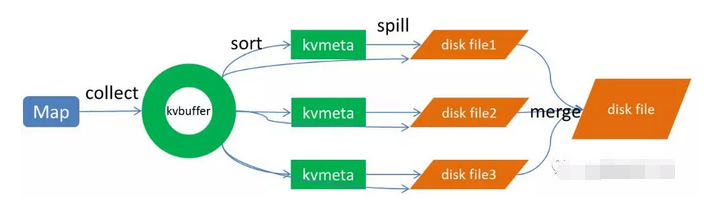
1、Map端sort
Map端的输出数据,先写环形缓存区kvbuffer,当环形缓冲区到达一个阀值(可以通过配置文件设置,默认80),便要开始溢写,但溢写之前会有一个sort操作,这个sort操作先把Kvbuffer中的数据按照partition值和key两个关键字来排序,移动的只是索引数据,排序结果是Kvmeta中数据按照partition为单位聚集在一起,同一partition内的按照key有序。
2、spill(溢写)
当排序完成,便开始把数据刷到磁盘,刷磁盘的过程以分区为单位,一个分区写完,写下一个分区,分区内数据有序,最终实际上会多次溢写,然后生成多个文件
3、merge(合并)
spill会生成多个小文件,对于Reduce端拉取数据是相当低效的,那么这时候就有了merge的过程,合并的过程也是同分片的合并成一个片段(segment),最终所有的segment组装成一个最终文件,那么合并过程就完成了,如下图所示
至此,Map的操作就已经完成,Reduce端操作即将登场
Reduce操作
总体过程如下图的红框处:
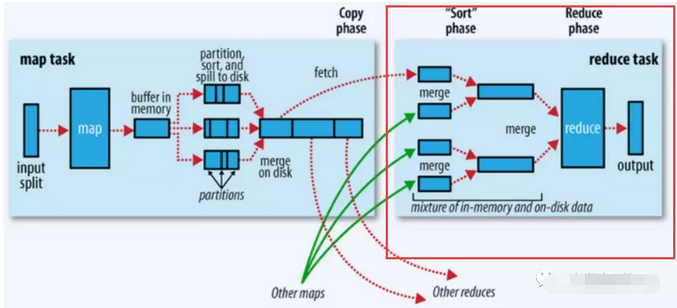
1、拉取拷贝(fetch copy)
Reduce任务通过向各个Map任务拉取对应分片。这个过程都是以Http协议完成,每个Map节点都会启动一个常驻的HTTP server服务,Reduce节点会请求这个Http Server拉取数据,这个过程完全通过网络传输,所以是一个非常重量级的操作。
2、合并排序
Reduce端,拉取到各个Map节点对应分片的数据之后,会进行再次排序,排序完成,结果丢给Reduce函数进行计算。
四、总结
至此整个shuffle过程完成,最后总结几点:
1、shuffle过程就是为了对key进行全局聚合2、排序操作伴随着整个shuffle过程,所以Hadoop的shuffle是sort-based的
Spark shuffle相对来说更简单,因为不要求全局有序,所以没有那么多排序合并的操作。Spark shuffle分为write和read两个过程。我们先来看shuffle write。
一、shuffle write
shuffle write的处理逻辑会放到该ShuffleMapStage的最后(因为spark以shuffle发生与否来划分stage,也就是宽依赖),final RDD的每一条记录都会写到对应的分区缓存区bucket,如下图所示:
说明:
1、上图有2个CPU,可以同时运行两个ShuffleMapTask
2、每个task将写一个buket缓冲区,缓冲区的数量和reduce任务的数量相等
3、 每个buket缓冲区会生成一个对应ShuffleBlockFile
4、ShuffleMapTask 如何决定数据被写到哪个缓冲区呢?这个就是跟partition算法有关系,这个分区算法可以是hash的,也可以是range的
5、最终产生的ShuffleBlockFile会有多少呢?就是ShuffleMapTask 数量乘以reduce的数量,这个是非常巨大的
那么有没有办法解决生成文件过多的问题呢?有,开启FileConsolidation即可,开启FileConsolidation之后的shuffle过程如下:
在同一核CPU执行先后执行的ShuffleMapTask可以共用一个bucket缓冲区,然后写到同一份ShuffleFile里去,上图所示的ShuffleFile实际上是用多个ShuffleBlock构成,那么,那么每个worker最终生成的文件数量,变成了cpu核数乘以reduce任务的数量,大大缩减了文件量。
二、Shuffle read
Shuffle write过程将数据分片写到对应的分片文件,这时候万事具备,只差去拉取对应的数据过来计算了。
那么Shuffle Read发送的时机是什么?是要等所有ShuffleMapTask执行完,再去fetch数据吗?理论上,只要有一个 ShuffleMapTask执行完,就可以开始fetch数据了,实际上,spark必须等到父stage执行完,才能执行子stage,所以,必须等到所有 ShuffleMapTask执行完毕,才去fetch数据。fetch过来的数据,先存入一个Buffer缓冲区,所以这里一次性fetch的FileSegment不能太大,当然如果fetch过来的数据大于每一个阀值,也是会spill到磁盘的。
fetch的过程过来一个buffer的数据,就可以开始聚合了,这里就遇到一个问题,每次fetch部分数据,怎么能实现全局聚合呢?以word count的reduceByKey(《Spark RDD操作之ReduceByKey 》)为例,假设单词hello有十个,但是一次fetch只拉取了2个,那么怎么全局聚合呢?Spark的做法是用HashMap,聚合操作实际上是map.put(key,map.get(key)+1),将map中的聚合过的数据get出来相加,然后put回去,等到所有数据fetch完,也就完成了全局聚合。
三、总结
Hadoop的MapReduce Shuffle和Spark Shuffle差别总结如下:
1、Hadoop的有一个Map完成,Reduce便可以去fetch数据了,不必等到所有Map任务完成,而Spark的必须等到父stage完成,也就是父stage的map操作全部完成才能去fetch数据。
2、Hadoop的Shuffle是sort-base的,那么不管是Map的输出,还是Reduce的输出,都是partion内有序的,而spark不要求这一点。
3、Hadoop的Reduce要等到fetch完全部数据,才将数据传入reduce函数进行聚合,而spark是一边fetch一边聚合。
剖析Hadoop和Spark的Shuffle过程差异的更多相关文章
- 剖析Hadoop和Spark的Shuffle过程差异(一)
一.前言 对于基于MapReduce编程范式的分布式计算来说,本质上而言,就是在计算数据的交.并.差.聚合.排序等过程.而分布式计算分而治之的思想,让每个节点只计算部分数据,也就是只处理一个分片,那么 ...
- hadoop的mapReduce和Spark的shuffle过程的详解与对比及优化
https://blog.csdn.net/u010697988/article/details/70173104 大数据的分布式计算框架目前使用的最多的就是hadoop的mapReduce和Spar ...
- Hadoop和Spark的Shuffer过程对比解析
Hadoop Shuffer Hadoop 的shuffer主要分为两个阶段:Map.Reduce. Map-Shuffer: 这个阶段发生在map阶段之后,数据写入内存之前,在数据写入内存的过程就已 ...
- Hadoop学习笔记—10.Shuffle过程那点事儿
一.回顾Reduce阶段三大步骤 在第四篇博文<初识MapReduce>中,我们认识了MapReduce的八大步骤,其中在Reduce阶段总共三个步骤,如下图所示: 其中,Step2.1就 ...
- Spark 的 Shuffle过程介绍`
Spark的Shuffle过程介绍 Shuffle Writer Spark丰富了任务类型,有些任务之间数据流转不需要通过Shuffle,但是有些任务之间还是需要通过Shuffle来传递数据,比如wi ...
- Hadoop计算中的Shuffle过程(转)
Hadoop计算中的Shuffle过程 作者:左坚 来源:清华万博 时间:2013-07-02 15:04:44.0 Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方.要想理解Ma ...
- Spark的Shuffle过程介绍
Spark的Shuffle过程介绍 Shuffle Writer Spark丰富了任务类型,有些任务之间数据流转不需要通过Shuffle,但是有些任务之间还是需要通过Shuffle来传递数据,比如wi ...
- 彻底搞懂spark的shuffle过程(shuffle write)
什么时候需要 shuffle writer 假如我们有个 spark job 依赖关系如下 我们抽象出来其中的rdd和依赖关系: E <-------n------, ...
- 【Big Data - Hadoop - MapReduce】通过腾讯shuffle部署对shuffle过程进行详解
摘要: 通过腾讯shuffle部署对shuffle过程进行详解 摘要:腾讯分布式数据仓库基于开源软件Hadoop和Hive进行构建,TDW计算引擎包括两部分:MapReduce和Spark,两者内部都 ...
随机推荐
- Aria2 使用手札(简易部署 + 快速进阶)
没错,又是受够了迅雷.旋风的各种奇葩减速(哥哥我还买了了VIP!),IDM 对协议支持又太少还有事没事提示你不是正版三天两头闹着要更新.于是我想起来之前看到过的 Aria2,虽然之前也只是略有耳闻,但 ...
- Mysql 批量更新update的表与表之间操作
Mysql 批量更新update的表与表之间操作 一.方法一 使用User2表数据更新User表: update User as a ,User2 as b set a.role_id=b.set_v ...
- jmeter的使用
jmeter:java开发的开源的性能测试工具. *jmeter返回中文乱码: 1.在jmeter的bin目录下,找到jmeter的配置文件,jmeter.properties,然后把samplere ...
- 让CSS某行不失效
比如百度的分享代码 <div id="bdshare" class="bdshare_t bds_tools get-codes-bdshare"> ...
- fastjson常用方法
fastjson是一款alibaba公司开发的json工具包.json经常被使用在数据传输方面,因此特意对它的一些常用方法做备注,欢迎看客在评论区补充或指出问题. 首先定义一个实体类,用于我们进行对象 ...
- tomcat8.5之后版本,远程无法登录管理页面
转载自http://jingyan.baidu.com/article/1612d500b56fa1e20e1eeed2.html 服务器采用的是linux系统. 安装tomcat在服务器上后,客户端 ...
- Junit中AssertTrue的使用
assertTrue public static void assertTrue(String message, boolean condition) Asserts that a condition ...
- 再谈 linux 的sed用法
很多东西, 如果太复杂, 太庞杂, 一开始, 可以只掌握最简单的. 如果连最简单的都不能掌握, 那看那么多有什么用? 关于cut, sed的 处理过程和思想? vm: virtual machine, ...
- 【做题】BZOJ2534 L-gap字符串——调和级数
题意:给出一个字符串,问其中有多少个子串恰好为\(uvu\)的形式.其中,\(u\)非空,\(v\)的长度恰好为\(l\). \(n \leq 5 \times 10^4\) 我们设两个后缀的起点分别 ...
- jquery里面获取div区块的宽度与高度
https://blog.csdn.net/ll641058431/article/details/52768825 获取宽度 $('div').width(); 获取:区块的本身宽度 $(' ...