Redis集群官方推荐方案 Redis-Cluster
Redis-Cluster
redis使用中遇到的瓶颈
我们日常在对于redis的使用中,经常会遇到一些问题
1、高可用问题,如何保证redis的持续高可用性。
2、容量问题,单实例redis内存无法无限扩充,达到32G后就进入了64位世界,性能下降。
3、并发性能问题,redis号称单实例10万并发,但也是有尽头的。
redis-cluster的优势
1、官方推荐,毋庸置疑。
2、去中心化,集群最大可增加1000个节点,性能随节点增加而线性扩展。
3、管理方便,后续可自行增加或摘除节点,移动分槽等等。
4、简单,易上手。
redis-cluster名词介绍
1、master 主节点、
2、slave 从节点
3、slot 槽,一共有16384数据分槽,分布在集群的所有主节点中。
redis-cluster简介
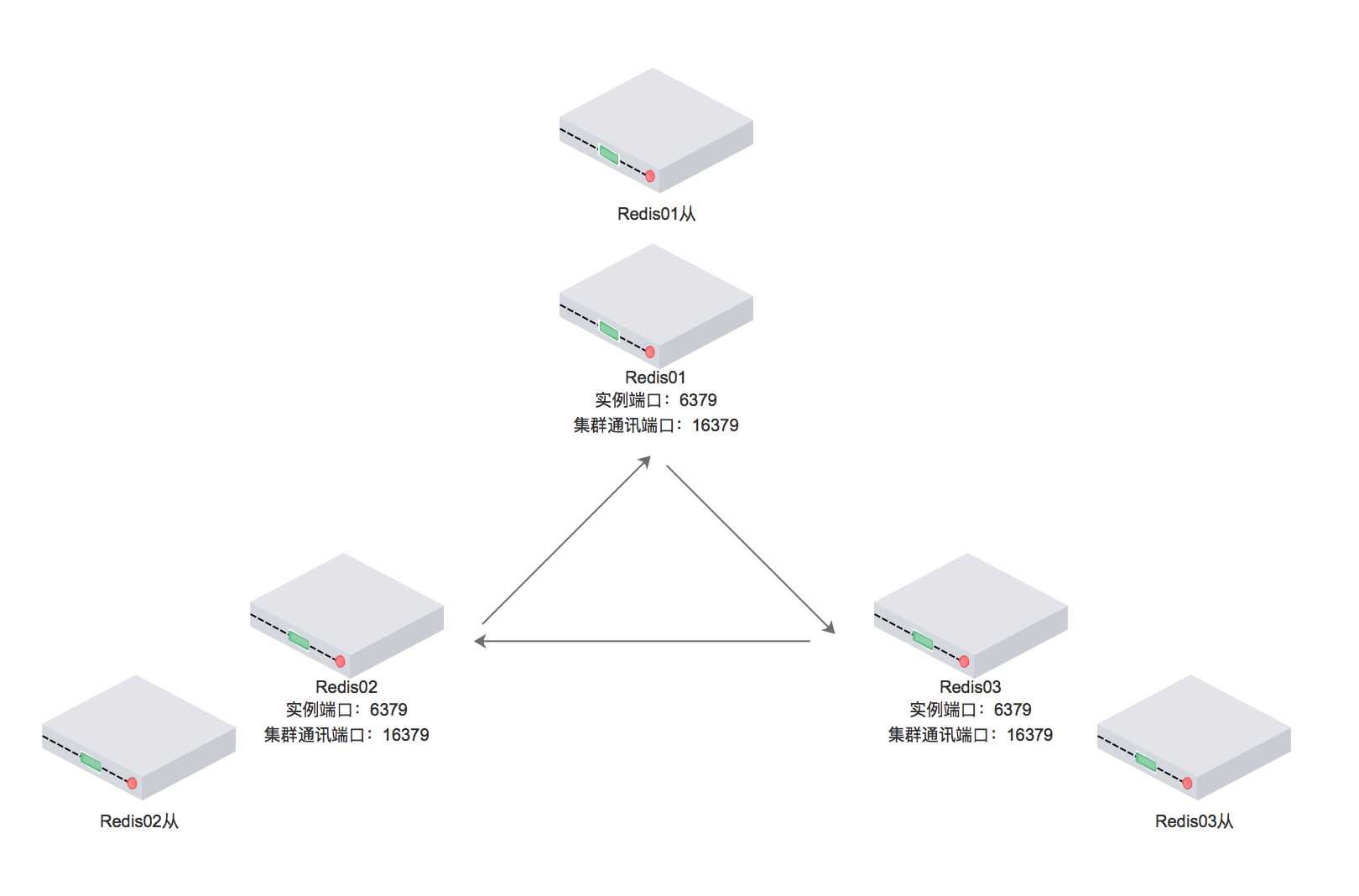
图中描述的是六个redis实例构成的集群
6379端口为客户端通讯端口
16379端口为集群总线端口
集群内部划分为16384个数据分槽,分布在三个主redis中。
从redis中没有分槽,不会参与集群投票,也不会帮忙加快读取数据,仅仅作为主机的备份。
三个主节点中平均分布着16384数据分槽的三分之一,每个节点中不会存有有重复数据,仅仅有自己的从机帮忙冗余。
集群部署
测试部署方式,一台测试机多实例启动部署。
安装redis
$ wget http://download.redis.io/releases/redis-3.2.8.tar.gz
$ tar xzf redis-3.2..tar.gz
$ cd redis-3.2.
$ make
修改配置文件 redis.conf
#redis.conf默认配置
daemonize yes
pidfile /var/run/redis/redis.pid #多实例情况下需修改,例如redis_6380.pid
port 6379 #多实例情况下需要修改,例如6380
tcp-backlog
bind 0.0.0.0
timeout
tcp-keepalive
loglevel notice
logfile /var/log/redis/redis.log #多实例情况下需要修改,例如6380.log
databases
save
save
save
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb #多实例情况下需要修改,例如dump.6380.rdb
slave-serve-stale-data yes
slave-read-only yes
repl-diskless-sync no
repl-diskless-sync-delay
repl-disable-tcp-nodelay no
slave-priority
appendonly yes
appendfilename "appendonly.aof" #多实例情况下需要修改,例如 appendonly_6380.aof
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
lua-time-limit
slowlog-log-slower-than
slowlog-max-len
latency-monitor-threshold
notify-keyspace-events ""
hash-max-ziplist-entries
hash-max-ziplist-value
list-max-ziplist-entries
list-max-ziplist-value
set-max-intset-entries
zset-max-ziplist-entries
zset-max-ziplist-value
hll-sparse-max-bytes
activerehashing yes
client-output-buffer-limit normal
client-output-buffer-limit slave 256mb 64mb
client-output-buffer-limit pubsub 32mb 8mb
hz #################自定义配置
#系统配置
#vim /etc/sysctl.conf
#vm.overcommit_memory = aof-rewrite-incremental-fsync yes
maxmemory 4096mb
maxmemory-policy allkeys-lru
dir /opt/redis/data #多实例情况下需要修改,例如/data/6380 #集群配置
cluster-enabled yes
cluster-config-file /opt/redis//nodes.conf #多实例情况下需要修改,例如/6380/
cluster-node-timeout #从ping主间隔默认10秒
#复制超时时间
#repl-timeout #远距离主从
#config set client-output-buffer-limit "slave 536870912 536870912 0"
#config set repl-backlog-size
启动六个实例:
/编译安装目录/src/redis-server redis.conf
注意,redis.conf应为6个不同的修改过的多实例配置文件。
注意,配置文件复制六分后,有许多需要你修改的地方。
创建redis-cluster
redis-trib.rb命令与redis-cli命令放置在同一个目录中,可全路径执行或者创建别名。
移动槽
删除节点
添加master节点
添加一个从节点
注:
安装部署部分不是无脑复制即可,请结合你的主机情况进行操作,若有问题可以联系我 QQ:2169866431
谢土豪

Redis集群官方推荐方案 Redis-Cluster的更多相关文章
- redis集群主流架构方案分析
Redis在互联网大数据平台有着广泛的应用,主要被用来缓存热点数据,避免海量请求压垮数据库,同时可以提升服务节点的响应速度和并发量.随着数据量的增多,由于redis是占用单台物理机或虚机的内存,内存资 ...
- coding++:error 阿里云 Redis集群一直Waiting for the cluster to join....存在以下隐患
1):Redis集群一直Waiting for the cluster to join... 再次进行连接时首先需要以下操作 1.使用redis desktop Manager连接所有节点 调出命令窗 ...
- 超详细,多图文介绍redis集群方式并搭建redis伪集群
超详细,多图文介绍redis集群方式并搭建redis伪集群 超多图文,对新手友好度极好.敲命令的过程中,难免会敲错,但为了截好一张合适的图,一旦出现一点问题,为了好的演示效果,就要从头开始敲.且看且珍 ...
- 探索Redis设计与实现13:Redis集群机制及一个Redis架构演进实例
本文转自互联网 本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutorial ...
- Redis集群节点扩容及其 Redis 哈希槽
Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求 ...
- 搭建Solr集群的推荐方案
之前介绍过2篇SolrCloud的部署流程,第一个是使用安装脚本的方式进行抽取安装,启动比较方便,但是会创建多个目录,感觉比较乱:第二个是官方教程上提供的方法,使用比较简单,直接释放压缩包即可,并且启 ...
- 最大的Redis集群:新浪Redis集群揭秘
前言 Tape is Dead,Disk is Tape,Flash is Disk,RAM Locality is King. — Jim Gray Redis不是比较成熟的Memcac ...
- c#+linux+mono+Redis集群(解决无法连接Redis的问题)
在linux环境中使用mono来执行c#的程序, 在连接redis的时候遇到了无法连接数据库的错误.如下: Unhandled Exception:StackExchange.Redis.RedisC ...
- Redis 集群之 Redis-Cluster
Redis集群官方推荐方案 Redis-Cluster 集群 redis cluster 通过分片实࣫容量扩展 通过主从复制实࣫节点的高可用 节点之间互相通信 每个节点都维护整个集群的节点信息 red ...
随机推荐
- Bootstrap报错:Bootstrap's JavaScript requires jQuery
如题,经百度原来导入顺序的问题,须要先导入Jqeury库,今记之!
- LeetCode(46):全排列
Medium! 题目描述: 给定一个没有重复数字的序列,返回其所有可能的全排列. 示例: 输入: [1,2,3] 输出: [ [1,2,3], [1,3,2], [2,1,3], [2,3,1], [ ...
- 使用exundelete在Linux下恢复删除的文件
原文:https://my.oschina.net/looly/blog/261912 Linux下执行 rm 并不会真正删除,而是将inode节点中的扇区删除,同时释放数据块.在数据块被系统重新分配 ...
- SPLAY,LCT学习笔记(四)
前三篇好像变成了SPLAY专题... 这一篇正式开始LCT! 其实LCT就是基于SPLAY的伸展操作维护树(森林)连通性的一个数据结构 核心操作有很多,我们以一道题为例: 例:bzoj 2049 洞穴 ...
- List遍历三种方法:1.for 2.增强性for 3.迭代器
package chapter09; import java.util.ArrayList;import java.util.Iterator;import java.util.List; /* * ...
- Math对象的常用属性和方法
属性 描述 Math.PI 返回π(3.1415926) 方法 描述 Math.round() 将数字四舍五入到离它最近的整数 Math.sart(n) 返回平方根,例如Math.sart(9)返回3 ...
- 《转》Web Service实践之——开始XFire
Web Service实践之——开始XFire 一.Axis与XFire的比较XFire是与Axis2 并列的新一代WebService平台.之所以并称为新一代,因为它:1.支持一系列Web Serv ...
- 【C++ Primer 第13章】3. 交换操作
交换操作 class HasPtr { friend void swap(HasPtr &rhs, HasPtr &yhs); //其他成员定义 }; void swap(HasPtr ...
- 观察者模式(Observer Pattern)
一.概述在软件设计工作中会存在对象之间的依赖关系,当某一对象发生变化时,所有依赖它的对象都需要得到通知.如果设计的不好,很容易造成对象之间的耦合度太高,难以应对变化.使用观察者模式可以降低对象之间的依 ...
- python访问百度地图接口并返回信息
import urllib.parse import urllib.request data = urllib.parse.urlencode({'address': '广东省湛江市霞山区', 'ou ...