比较两个ranges(equal,mismatch,lexicographical_compare)
euqal
比较两个序列是否相等,相等返回true,不相等返回false
template <class _InputIter1, class _InputIter2>//版本1
inline bool equal(_InputIter1 __first1, _InputIter1 __last1,
_InputIter2 __first2) {
for ( ; __first1 != __last1; ++__first1, ++__first2)//遍历区间[first,last)元素
if (*__first1 != *__first2)//只有有一个不相等返回false
return false;
return true;
} template <class _InputIter1, class _InputIter2, class _BinaryPredicate>//版本2
inline bool equal(_InputIter1 __first1, _InputIter1 __last1,
_InputIter2 __first2, _BinaryPredicate __binary_pred) {
for ( ; __first1 != __last1; ++__first1, ++__first2)
if (!__binary_pred(*__first1, *__first2))//两个元素执行二元操作符
return false;
return true;
}
fill
将value值填充整个区间,不能为OutputIterator,因为fill会用到first和last,outputIterator无法做相等的测试
template <class ForwardIterator, class T>
void fill( ForwardIterator first, ForwardIterator last,const T& value);
fill_n
会将数值value填充[first,first+n),返回值为first+n,可以用outputIterator
template <class OutputIterator,class size,class T>
OutputIterator fill_n( OutputIterator first, OutputIterator last,size n,const T& value);
iter_swap
将两个迭代器所指对象互换
template <class _ForwardIter1, class _ForwardIter2, class _Tp>
inline void __iter_swap(_ForwardIter1 __a, _ForwardIter2 __b, _Tp*) {
_Tp __tmp = *__a;
*__a = *__b;
*__b = __tmp;
} template <class _ForwardIter1, class _ForwardIter2>
inline void iter_swap(_ForwardIter1 __a, _ForwardIter2 __b) {
__iter_swap(__a, __b, __VALUE_TYPE(__a));
}
generate
template <class ForwardIterator, class Generator>
void generate ( ForwardIterator first, ForwardIterator last, Generator gen )
{
while (first != last)
{
*first = gen();
++first;
}
}
generate_n
返回值是first+n,generate和generate_n中的gen会被调用n(或first+n)次,而非只在循环外调用一次,这一点很重要,因为Generate不一定会在每次调用时候都返回相同的结果,因此generate允许从文件读入,取局部状态的值并更改。
template <class OutputIterator, class Size, class Generator>
OutputIterator generate_n ( OutputIterator first, Size n,const Generator gen )
{
while (n>)
{
*first = gen();
++first;
--n;
}
}
mismatch
与equal类似,但会返回哪里不同,equal(f1,l1,f2)与misatch(f1,l1,f2)。first==l1等价,如果相等,返回两个序列的last
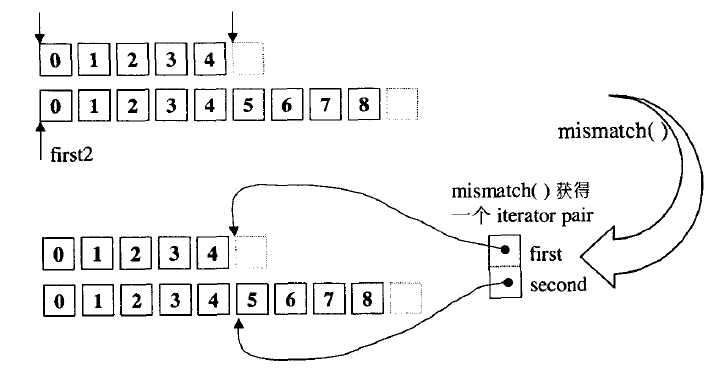
//版本一:调用重载operator==比较元素
template <class InputIterator1,class InputIterator2>
pair<InputIterator1,InputIterator2> mismatch(InputIterator1 first1,InputIterator1 last1,InputIterator2 first2)
{
while (first1 != last1 && *first1 == *first2) {
++first1;
++first2;
}
return pair<InputIterator1,InputIterator2>(first1, first2);//返回pair类型,first1指向第一个序列不匹配点,first2指向第二个序列不匹配点
}
//版本二:调用自己定义的function object来比较
template <class InputIterator1,class InputIterator2,class BinaryPredicate>
pair<InputIterator1,InputIterator2> mismatch(InputIterator1 first1,InputIterator1 last1,InputIterator2 first2,BinaryPredicate binary_pred)
{
while (first1 != last1 && binary_pred(*first1, *first2)) {
++first1;
++first2;
return pair<InputIterator1,InputIterator2>(first1, first2);
}
lexicographical_compare
返回两个序列的字典排序大小,
- 如果第一序列元素较小返回true,否则返回false
- 到达last1而未到达last2返回true
- 到达last2而未到达last1返回false
- 同时到达last1和last2(所有元素都匹配)返回false
//版本一:调用重载operator==比较元素
template <class InputIterator1,class InputIterator2>
bool lexicographical_compare(InputIterator1 first1,InputIterator1 last1,InputIterator2 first2,InputIterator2 last2)
{
for ( ; first1 != last1 && first2 != last2; ++first1, ++first2)//两组元素一一比较,除非长度不相同
{
if (*first1 < *first2)
return true;
if (*first2 < *first1)
return false;
}
return first1 == last1 && first2 != last2;//第二组还有元素
} //版本二:调用自己定义的function object来比较,inputiterator1 value_type可转化为 BinaryPredicate的第一型别等等
template <class InputIterator1,class InputIterator2,class BinaryPredicate>
bool lexicographical_compare(InputIterator1 first1,InputIterator1 last1,InputIterator2 first2,InputIterator2,BinaryPredicate binary_pred)
{
for ( ; first1 != last1 && first2 != last2; ++first1, ++first2)
{
if (comp(*first1, *first2))
return true;
if (comp(*first2, *first1))
return false;
}
return first1 == last1 && first2 != last2;
}
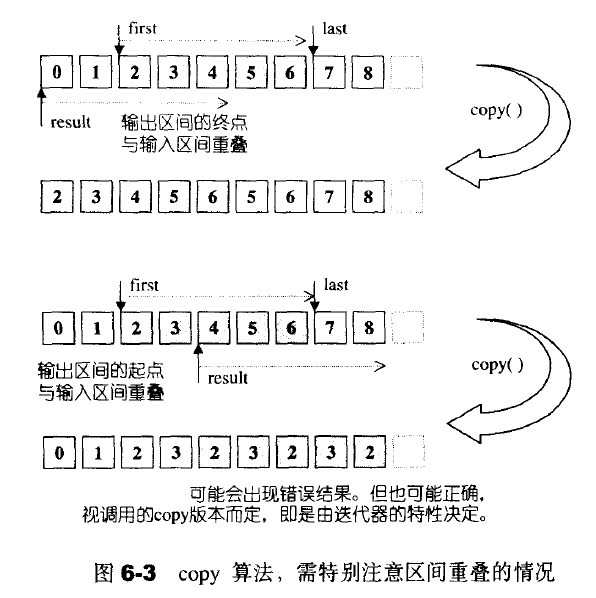
copy
- 为outputIterator中的元素赋值而不是产生新的元素,所以outputIterator不能是空的
- 如要元素安插序列,使用insert成员函数或使用copy搭配insert_iterator适配器
- 如果输出区间的起头与输入区间重叠,则不能使用copy,如果输出区间的尾端与输入区间重叠,则可以使用;copy_backward的限制与copy相反
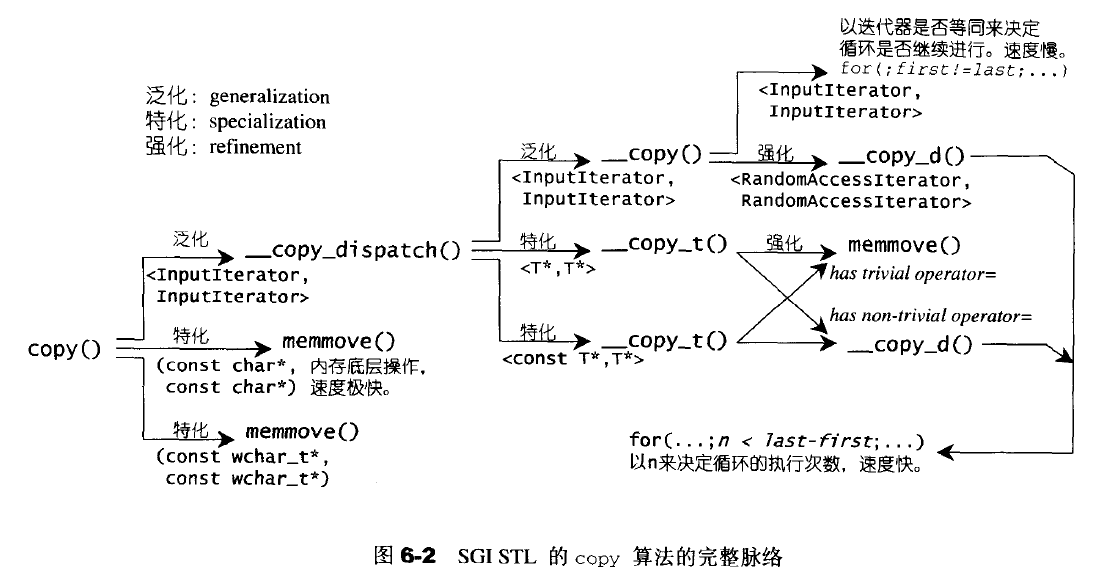
与strcpy、memmove的情况类似,具体看下图
在偏特化与全特化中分析过, 最适合的函数会优先调用, 普通函数优先级大于模板函数
template <class InputIterator, class OutputIterator>
inline OutputIterator copy(InputIterator first, InputIterator last, OutputIterator result)
{
return __copy_dispatch<InputIterator,OutputIterator>()(first, last, result);
}
// 重载 在偏特化与全特化中分析过, 最适合的函数会优先调用, 普通函数优于模板函数
inline char* copy(const char* first, const char* last, char* result) {
// 直接调用memmove效率最高
memmove(result, first, last - first);
return result + (last - first);
}
inline wchar_t* copy(const wchar_t* first, const wchar_t* last, wchar_t* result) {
// 直接调用memmove效率最高
memmove(result, first, sizeof(wchar_t) * (last - first));
return result + (last - first);
} template <class InputIterator, class OutputIterator>
struct __copy_dispatch//通过传入参数的迭代器类型再进行优化处理
{
OutputIterator operator()(InputIterator first, InputIterator last,
OutputIterator result) {
// iterator_category获取迭代器类型, 不同迭代器选择不同的重载函数
return __copy(first, last, result, iterator_category(first));
}
};
template <class T>
struct __copy_dispatch<const T*, T//针对参数是否是原生指针进行泛化
{
T* operator()(const T* first, const T* last, T* result) {
typedef typename __type_traits<T>::has_trivial_assignment_operator t;
return __copy_t(first, last, result, t());
}
}; template <class T>
struct __copy_dispatch<T*, T*>
{
T* operator()(T* first, T* last, T* result) {
typedef typename __type_traits<T>::has_trivial_assignment_operator t;
return __copy_t(first, last, result, t());
}
}; template <class InputIterator, class OutputIterator>
inline OutputIterator __copy(InputIterator first, InputIterator last,OutputIterator result, input_iterator_tag)
{
// 通过迭代器将一个元素一个元素的复制
for ( ; first != last; ++result, ++first)
*result = *first;
return result;
}
template <class RandomAccessIterator, class OutputIterator>
inline OutputIterator __copy(RandomAccessIterator first, RandomAccessIterator last, OutputIterator result, random_access_iterator_tag)
{
return __copy_d(first, last, result, distance_type(first));
}
template <class RandomAccessIterator, class OutputIterator, class Distance>
//优化处理
template <class T>
inline T* __copy_t(const T* first, const T* last, T* result, __false_type) {
return __copy_d(first, last, result, (ptrdiff_t*) );
}
//优化处理
template <class T>
inline T* __copy_t(const T* first, const T* last, T* result, __true_type) {
memmove(result, first, sizeof(T) * (last - first));
return result + (last - first);
}
inline OutputIterator __copy_d(RandomAccessIterator first, RandomAccessIterator last,OutputIterator result, Distance*)
{
// 通过迭代器之间的元素个数将一个元素一个元素的复制
for (Distance n = last - first; n > ; --n, ++result, ++first)
*result = *first;
return result;
}
copy_backward
从结果集的尾端到头端复制元素,返回result-(last-first)
template <class BidirectionalIterator1,class BidirectionalIterator2>
OutputeIterator copy(BidirectionalIterator1 first,BidirectionalIterator1 last,BidirectionalIterator2 result);
比较两个ranges(equal,mismatch,lexicographical_compare)的更多相关文章
- 不要重复发明轮子-C++STL
闫常友 著. 中国铁道出版社. 2013/5 标准的C++模板库,是算法和其他一些标准组件的集合. . 1.类模板简介 2.c++中的字符串 3.容器 4.c++中的算法 5.迭代器 6.STL 数值 ...
- STL基础--算法(不修改数据的算法)
不修改数据的算法 count, min and max, compare, linear search, attribute // 算法中Lambda函数很常用: num = count_if(vec ...
- 机器学习基础与实践(三)----数据降维之PCA
写在前面:本来这篇应该是上周四更新,但是上周四写了一篇深度学习的反向传播法的过程,就推迟更新了.本来想参考PRML来写,但是发现里面涉及到比较多的数学知识,写出来可能不好理解,我决定还是用最通俗的方法 ...
- pandas numpy处理缺失值,none与nan比较
原文链接:https://junjiecai.github.io/posts/2016/Oct/20/none_vs_nan/ 建议从这里下载这篇文章对应的.ipynb文件和相关资源.这样你就能在Ju ...
- T检验与F检验的区别_f检验和t检验的关系
1,T检验和F检验的由来 一般而言,为了确定从样本(sample)统计结果推论至总体时所犯错的概率,我们会利用统计学家所开发的一些统计方法,进行统计检定. 通过把所得到的统计检定值,与统计学家建立了一 ...
- 转:最近5年133个Java面试问题列表
最近5年133个Java面试问题列表 Java 面试随着时间的改变而改变.在过去的日子里,当你知道 String 和 StringBuilder 的区别就能让你直接进入第二轮面试,但是现在问题变得越来 ...
- linux test 命令使用
1. 关于某个文件名的『类型』侦测(存在与否),如 test -e filename -e 该『文件名』是否存在?(常用) -f 该『文件名』是否为文件(file)?(常用) -d 该『文件名』是否为 ...
- equals()和hashCode()隐式调用时的约定
package com.hash; import java.util.HashMap; public class Apple { private String color; public Apple( ...
- 通俗理解T检验和F检验
来源: http://blog.sina.com.cn/s/blog_4ee13c2c01016div.html 1,T检验和F检验的由来 一般而言,为了确定从样本(sample)统计结果推论至总 ...
随机推荐
- L316 波音737Max 危机
Boeing Scrambles To Restore Faith In Its 737 MAX Airplane After Crashes In the wake of two deadly cr ...
- nginx——ngx_http_gzip_module
文件压缩 Syntax: gzip on | off; Default: gzip off; Context: http, server, location, if in location Synta ...
- json pickle xml shelve configparser
json:# 是一种跨平台的数据格式 也属于序列化的一种方式pickle和shevle 序列化后得到的数据 只有python才可以解析通常企业开发不可能做一个单机程序 都需要联网进行计算机间的交互 J ...
- mybatis-generator eclipse插件 使用方法
mybatis-generator eclipse插件离线安装包 网址:http://download.csdn.net/download/gxl442172663/7624747 云盘地址:http ...
- 【leetcode】290. Word Pattern
problem 290. Word Pattern 多理解理解题意!!! 不过博主还是不理解,应该比较的是单词的首字母和pattern的顺序是否一致.疑惑!知道的可以分享一下下哈- 之前理解有误,应该 ...
- pandas-cheat-sheet
- NOI-1.1-06-空格分隔输出-体验多个输入输出
06:空格分隔输出 总时间限制: 1000ms 内存限制: 65536kB 描述 读入一个字符,一个整数,一个单精度浮点数,一个双精度浮点数,然后按顺序输出它们,并且要求在他们之间用一个空格分隔. ...
- SPI有关CPOL和CPHA的时序图
SPI模块为了和外设进行数据交换,根据外设工作要求,其输出串行同步时钟极性和相位可以进行配置. 时钟极性(CPOL)对传输协议没有重大的影响. 如果CPOL=0,串行同步时钟的空闲状态为低电平: 如果 ...
- fckeditor配置
<!DOCTYPE html> <html > <head> <title>发布</title> <meta name="v ...
- 20155219实践题目实现od命令
实践题目 编写MyOD.c 用myod XXX实现Linux下od -tx -tc XXX的功能 od的功能: od命令用于将指定文件内容以八进制.十进制.十六进制.浮点格式或ASCII编码字符方式显 ...