RabbitMQ -- unacked
RabbitMQ解决大量unacked问题
为了快速响应用户请求,我们需要消息异步处理机制,比较简单的做法是用redis的List结构,我们项目使用更专业的RabbitMQ。关于redis和RabbitMQ队列处理的性能比较可以查看这篇文章http://blog.csdn.net/educast/article/details/34521603
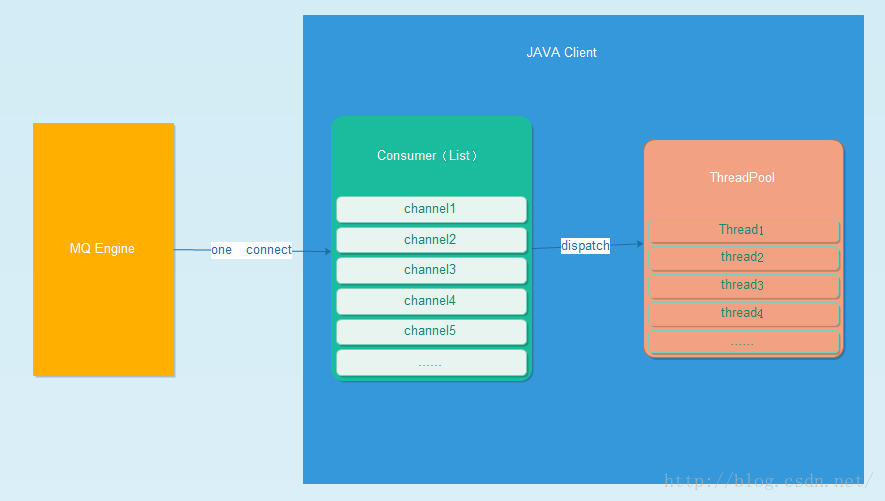
这里不扯RabbitMQ的一些定义了,我们遇到的问题是,入队并发和速度速度很快,但是消费端的处理速度慢得惊人。为了数据安全我们做了持久化而且消费端需要ack或者unack响应。从其提供的web控制台可以看到量大的时候产生大量的unacked消息,也就是说MQ把数据放到channel里,很长时间过去了channel没有给任何响应。我们创建了600个channel问题也依旧。查看了硬件没有瓶颈,网上有文章说是channel连接断了mq无法及时识别,还会往这些失效的channel里传递数据,误认子弟啊,拉出去枪毙了。Netstat一下,发现一共MQ服务器一共有4个外部连接连入了5672端口,两个productor两个consumer跟预想的一样。Jstack一下,发现pool-xxx线程远远没有预想的多,才50个,我们创建了600个channel啊。恍然大悟,尼玛的channel中文意思虽然是通道,但是MQ使用了线程池技术,它们是共享线程的,而不是一个通道一个线程,这个有点类似http请求和http服务器的关系。
把结构图给画出来先:
Java代码
- Properties prop = new Properties();
- InputStream inStream = this.getClass().getResourceAsStream("/config.properties");
- prop.load(inStream);
- ConnectionFactory factory = new ConnectionFactory();
- factory.setHost(prop.getProperty("RabbitMQHost"));
- factory.setUsername(prop.getProperty("RabbitMQUserName"));
- factory.setPassword(prop.getProperty("RabbitMQPassword"));
- // 关键所在,指定线程池
- ExecutorService service = Executors.newFixedThreadPool(500);
- factory.setSharedExecutor(service);
- factory.setAutomaticRecoveryEnabled(true);
- factory.setConnectionTimeout(15000);// 15秒
- factory.setRequestedHeartbeat(60);
- Connection connection = factory.newConnection();
线程方面已经没有问题了,不存在什么失效连接无法及时识别这一说法,如果还慢,则jstack去跟踪这些线程池的线程,看看都在干啥,关于jstack抽空再写了,很强大的jdk工具。
---------------------
本文来自 weinianjie1 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/weinianjie1/article/details/50611379?utm_source=copy
RabbitMQ -- unacked的更多相关文章
- python开发笔记-连接rabbitmq异常问题unacked处理
待补充 思路:捕获程序处理异常,异常情况下,也给队列生产者返回“确认”消息
- 消息队列——RabbitMQ学习笔记
消息队列--RabbitMQ学习笔记 1. 写在前面 昨天简单学习了一个消息队列项目--RabbitMQ,今天趁热打铁,将学到的东西记录下来. 学习的资料主要是官网给出的6个基本的消息发送/接收模型, ...
- 消费RabbitMQ时的注意事项,如何禁止大量的消息涌到Consumer
按照官网提供的订阅型写法( Retrieving Messages By Subscription ("push API")) 我发现,RabbitMQ服务器会在短时间内发送大量的 ...
- RabbitMQ的几种典型使用场景
RabbitMQ主页:https://www.rabbitmq.com/ AMQP AMQP协议是一个高级抽象层消息通信协议,RabbitMQ是AMQP协议的实现.它主要包括以下组件: 1.Serve ...
- 【RabbitMQ】 WorkQueues
消息分发 在[RabbitMQ] HelloWorld中我们写了发送/接收消息的程序.这次我们将创建一个Work Queue用来在多个消费者之间分配耗时任务. Work Queues(又称为:Task ...
- RabbitMQ消息队列:ACK机制
每个Consumer可能需要一段时间才能处理完收到的数据.如果在这个过程中,Consumer出错了,异常退出了,而数据还没有处理完成,那么 非常不幸,这段数据就丢失了. 因为我们采用no-ack的方式 ...
- (转)RabbitMQ消息队列(三):任务分发机制
在上篇文章中,我们解决了从发送端(Producer)向接收端(Consumer)发送“Hello World”的问题.在实际的应用场景中,这是远远不够的.从本篇文章开始,我们将结合更加实际的应用场景来 ...
- RabbitMQ基础总结
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法.应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们.消 息传递指的是程序之 ...
- RabbitMQ 原文译02--工作队列
工作队列: 在上一篇文章中我们我们创建程序发送和接受命名队列中的消息,在这篇文章我会创建一个工作队列,用来把耗时的操作分配给多个执行者. 工作队列(任务队列)的主要实现思想是避免马上执行资源密集型的任 ...
随机推荐
- Python使用lxml模块和Requests模块抓取HTML页面的教程
Web抓取Web站点使用HTML描述,这意味着每个web页面是一个结构化的文档.有时从中 获取数据同时保持它的结构是有用的.web站点不总是以容易处理的格式, 如 csv 或者 json 提供它们的数 ...
- LostRoutes项目日志——编辑project.json
第一个Scene编译后运行会报错: Uncaught TypeError: Cannot read property 'style' of null 这是因为没有在project.json中包含已经编 ...
- 腾讯云极速配置NodeJS+LNMP运行环境
版权声明:本文由吴逸翔原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/848754001487150669 来源:腾云阁 h ...
- 中检测到有潜在危险的 Request.Form 值。
两步 一.在</system.web>之前加上<httpRuntime requestValidationMode="2.0" /> <httpRun ...
- 正确停掉 expdp 或 impdp
1.查看视图dba_datapump_jobs SQL> set line 200 SQL> select job_name,state from dba_datapump_jobs; J ...
- linux命令学习(3):ls命令
ls命令是linux下最常用的命令.ls命令就是list的缩写,缺省下ls用来打印出当前目录的清单.如果ls指定其他目录,那么就会显示指定 目录里的文件及文件夹清单. 通过ls 命令不仅可以查看lin ...
- MVC的ViewData自动给Razor写的input赋值
问题: 写编辑的时候,突然发现,没有值的model,突然出现了值,而且值是ViewData中值. 后台: this.ViewData["test"] = "测试" ...
- 7.11js的总结
<!DOCTYPE html> <html> <head> <title>js的内置全局函数</title> <script type ...
- solus 系统 - 怎么使用中文输入法?
系统默认使用 ibus 输入法框架. 可以安装 ibus-libpinyin $ sudo eopkg install ibus-libpinyin 安装好之后需要初始化 ibus-setup $ i ...
- xshell连接Linux、ngix部署
Linux端安装sshd服务(openssh-server) 查看防火墙:ufw(Linux默认安装了) 再就是客户端了.. 平时在测试环境下的项目不能承载高并发,需要部署到web server上.w ...