死磕Java面试系列:深拷贝与浅拷贝的实现原理
深拷贝与浅拷贝的问题,也是面试中的常客。虽然大家都知道两者表现形式不同点在哪里,但是很少去深究其底层原理,也不知道怎么才能优雅的实现一个深拷贝。其实工作中也常常需要实现深拷贝,今天一灯就带大家一块深入剖析一下深拷贝与浅拷贝的实现原理,并手把手教你怎么优雅的实现深拷贝。
1. 什么是深拷贝与浅拷贝
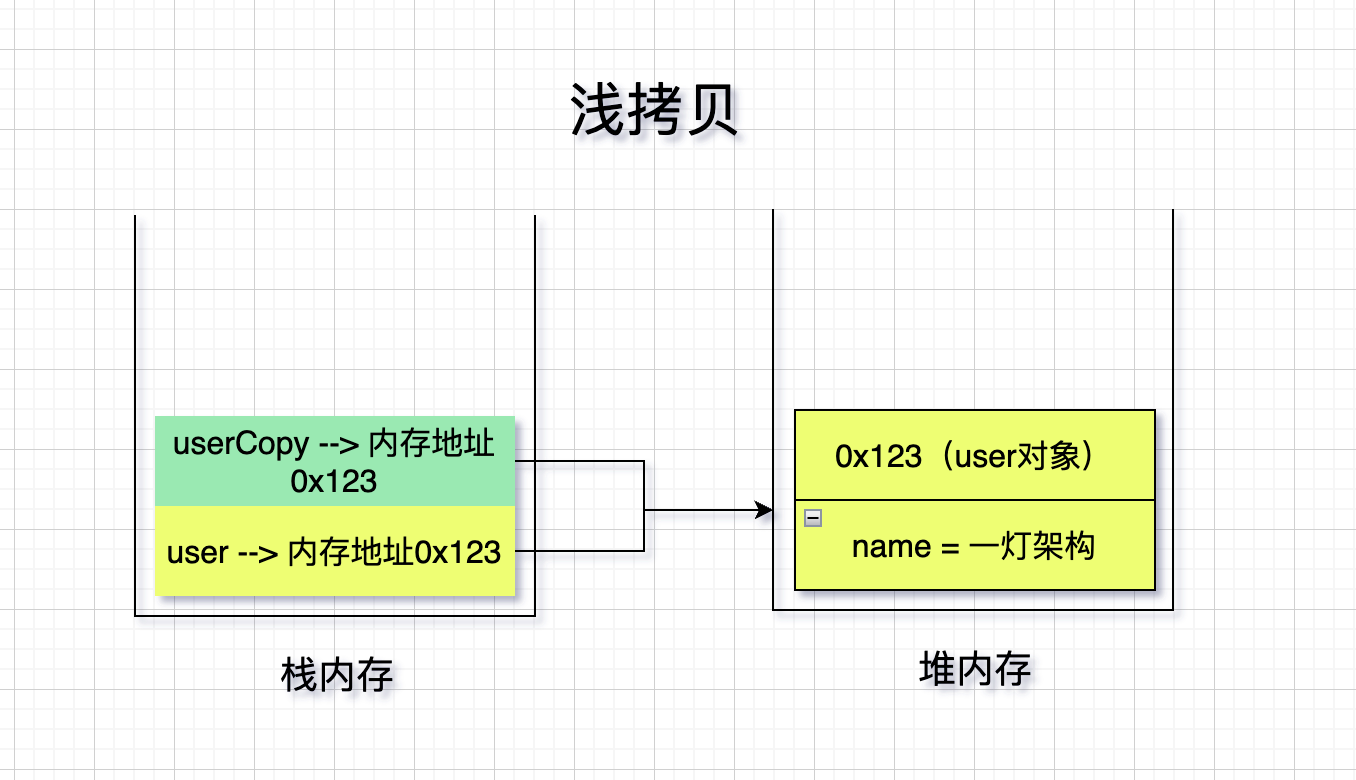
浅拷贝: 只拷贝栈内存中的数据,不拷贝堆内存中数据。
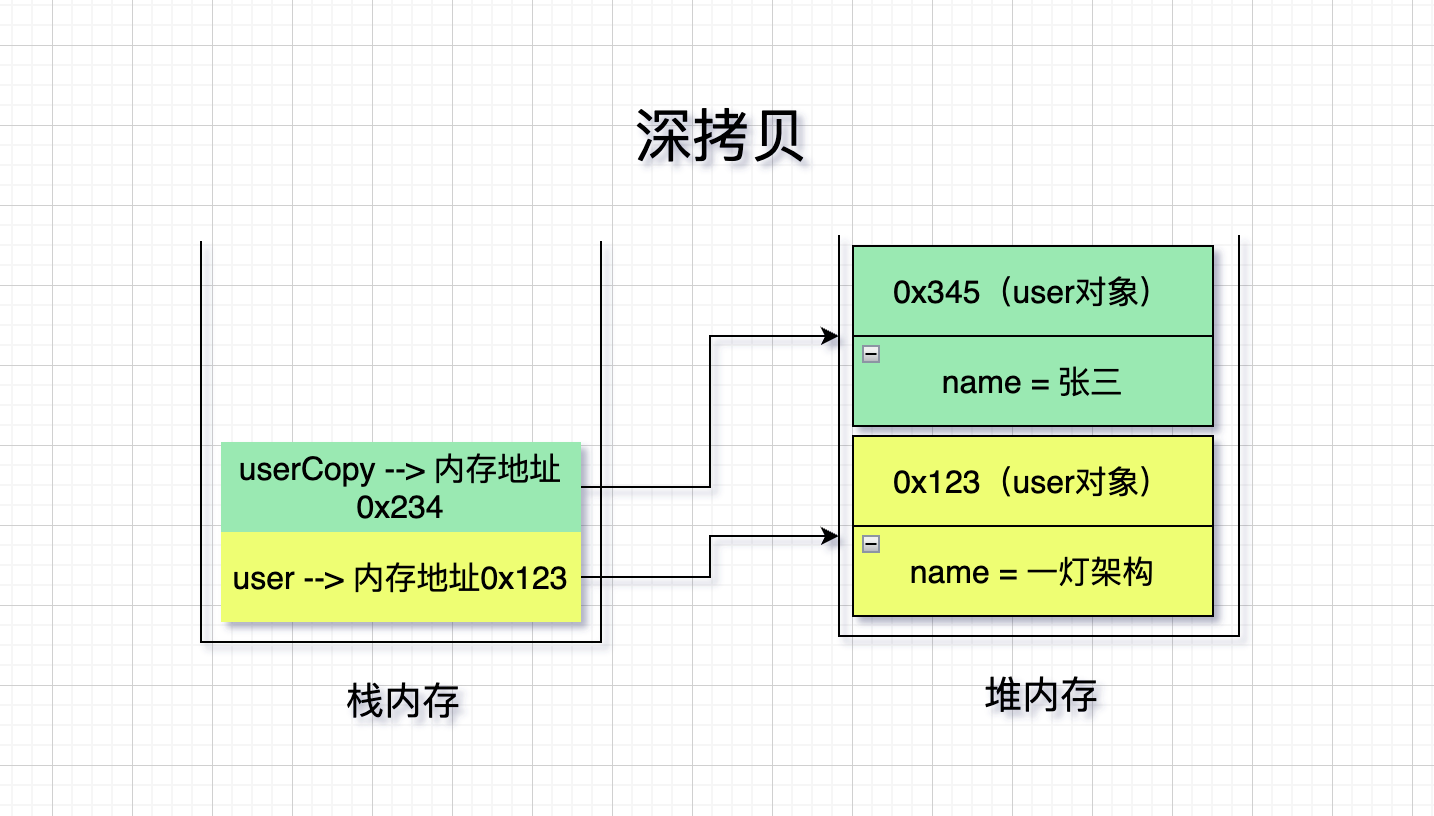
深拷贝: 既拷贝栈内存中的数据,又拷贝堆内存中的数据。
2. 浅拷贝的实现原理
由于浅拷贝只拷贝了栈内存中数据,栈内存中存储的都是基本数据类型,堆内存中存储了数组、引用数据类型等。
使用代码验证一下:
想要实现clone功能,需要实现 Cloneable 接口,并重写 clone 方法。
- 先创建一个用户类
// 用户的实体类,用作验证
public class User implements Cloneable {
private String name;
// 每个用户都有一个工作
private Job job;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Job getJob() {
return job;
}
public void setJob(Job job) {
this.job = job;
}
@Override
public User clone() throws CloneNotSupportedException {
User user = (User) super.clone();
return user;
}
}
- 再创建一个工作类
// 工作的实体类,并没有实现Cloneable接口
public class Job {
private String content;
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
- 测试浅拷贝
/**
* @author 一灯架构
* @apiNote Java浅拷贝示例
**/
public class Demo {
public static void main(String[] args) throws CloneNotSupportedException {
// 1. 创建用户对象,{"name":"一灯架构","job":{"content":"开发"}}
User user1 = new User();
user1.setName("一灯架构");
Job job1 = new Job();
job1.setContent("开发");
user1.setJob(job1);
// 2. 拷贝用户对象,name修改为"张三",工作内容修改"测试"
User user2 = user1.clone();
user2.setName("张三");
Job job2 = user2.getJob();
job2.setContent("测试");
// 3. 输出结果
System.out.println("user原对象= " + user1);
System.out.println("user拷贝对象= " + user2);
}
}
输出结果:
user原对象= {"name":"一灯架构","job":{"content":"测试"}}
user拷贝对象= {"name":"张三","job":{"content":"测试"}}
从结果中可以看出,对象拷贝把name修改为”张三“,原对象并没有变,name是String类型,是基本数据类型,存储在栈内存中。对象拷贝了一份新的栈内存数据,修改并不会影响原对象。
然后对象拷贝把Job中content修改为”测试“,原对象也跟着变了,原因是Job是引用类型,存储在堆内存中。对象拷贝和原对象指向的同一个堆内存的地址,所以修改会影响到原对象。
3. 深拷贝的实现原理
深拷贝是既拷贝栈内存中的数据,又拷贝堆内存中的数据。
实现深拷贝有很多种方法,下面就详细讲解一下,看使用哪种方式更方便快捷。
3.1 实现Cloneable接口
通过实现Cloneable接口来实现深拷贝是最常见的。
想要实现clone功能,需要实现Cloneable接口,并重写clone方法。
- 先创建一个用户类
// 用户的实体类,用作验证
public class User implements Cloneable {
private String name;
// 每个用户都有一个工作
private Job job;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Job getJob() {
return job;
}
public void setJob(Job job) {
this.job = job;
}
@Override
public User clone() throws CloneNotSupportedException {
User user = (User) super.clone();
// User对象中所有引用类型属性都要执行clone方法
user.setJob(user.getJob().clone());
return user;
}
}
- 再创建一个工作类
// 工作的实体类,需要实现Cloneable接口
public class Job implements Cloneable {
private String content;
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
@Override
protected Job clone() throws CloneNotSupportedException {
return (Job) super.clone();
}
}
- 测试浅拷贝
/**
* @author 一灯架构
* @apiNote Java深拷贝示例
**/
public class Demo {
public static void main(String[] args) throws CloneNotSupportedException {
// 1. 创建用户对象,{"name":"一灯架构","job":{"content":"开发"}}
User user1 = new User();
user1.setName("一灯架构");
Job job1 = new Job();
job1.setContent("开发");
user1.setJob(job1);
// 2. 拷贝用户对象,name修改为"张三",工作内容修改"测试"
User user2 = user1.clone();
user2.setName("张三");
Job job2 = user2.getJob();
job2.setContent("测试");
// 3. 输出结果
System.out.println("user原对象= " + user1);
System.out.println("user拷贝对象= " + user2);
}
}
输出结果:
user原对象= {"name":"一灯架构","job":{"content":"开发"}}
user拷贝对象= {"name":"张三","job":{"content":"测试"}}
从结果中可以看出,user拷贝对象修改了name属性和Job对象中内容,都没有影响到原对象,实现了深拷贝。
通过实现Cloneable接口的方式来实现深拷贝,是Java中最常见的实现方式。
缺点是: 比较麻烦,需要所有实体类都实现Cloneable接口,并重写clone方法。如果实体类中新增了一个引用对象类型的属性,还需要添加到clone方法中。如果继任者忘了修改clone方法,相当于挖了一个坑。
3.2 使用JSON字符串转换
实现方式就是:
- 先把user对象转换成json字符串
- 再把json字符串转换成user对象
这是个偏方,但是偏方治大病,使用起来非常方便,一行代码即可实现。
下面使用fastjson实现,使用Gson、Jackson也是一样的:
import com.alibaba.fastjson.JSON;
/**
* @author 一灯架构
* @apiNote Java深拷贝示例
**/
public class Demo {
public static void main(String[] args) throws CloneNotSupportedException {
// 1. 创建用户对象,{"name":"一灯架构","job":{"content":"开发"}}
User user1 = new User();
user1.setName("一灯架构");
Job job1 = new Job();
job1.setContent("开发");
user1.setJob(job1);
//// 2. 拷贝用户对象,name修改为"张三",工作内容修改"测试"
User user2 = JSON.parseObject(JSON.toJSONString(user1), User.class);
user2.setName("张三");
Job job2 = user2.getJob();
job2.setContent("测试");
// 3. 输出结果
System.out.println("user原对象= " + JSON.toJSONString(user1));
System.out.println("user拷贝对象= " + JSON.toJSONString(user2));
}
}
输出结果:
user原对象= {"name":"一灯架构","job":{"content":"开发"}}
user拷贝对象= {"name":"张三","job":{"content":"测试"}}
从结果中可以看出,user拷贝对象修改了name属性和Job对象中内容,并没有影响到原对象,实现了深拷贝。
3.3 集合实现深拷贝
再说一下Java集合怎么实现深拷贝?
其实非常简单,只需要初始化新对象的时候,把原对象传入到新对象的构造方法中即可。
以最常用的ArrayList为例:
/**
* @author 一灯架构
* @apiNote Java深拷贝示例
**/
public class Demo {
public static void main(String[] args) throws CloneNotSupportedException {
// 1. 创建原对象
List<User> userList = new ArrayList<>();
// 2. 创建深拷贝对象
List<User> userCopyList = new ArrayList<>(userList);
}
}
我是「一灯架构」,如果本文对你有帮助,欢迎各位小伙伴点赞、评论和关注,感谢各位老铁,我们下期见

死磕Java面试系列:深拷贝与浅拷贝的实现原理的更多相关文章
- 死磕 java同步系列之AQS终篇(面试)
问题 (1)AQS的定位? (2)AQS的重要组成部分? (3)AQS运用的设计模式? (4)AQS的总体流程? 简介 AQS的全称是AbstractQueuedSynchronizer,它的定位是为 ...
- 死磕 java同步系列之redis分布式锁进化史
问题 (1)redis如何实现分布式锁? (2)redis分布式锁有哪些优点? (3)redis分布式锁有哪些缺点? (4)redis实现分布式锁有没有现成的轮子可以使用? 简介 Redis(全称:R ...
- 死磕 java同步系列之终结篇
简介 同步系列到此就结束了,本篇文章对同步系列做一个总结. 脑图 下面是关于同步系列的一份脑图,列举了主要的知识点和问题点,看过本系列文章的同学可以根据脑图自行回顾所学的内容,也可以作为面试前的准备. ...
- 死磕 java同步系列之AQS起篇
问题 (1)AQS是什么? (2)AQS的定位? (3)AQS的实现原理? (4)基于AQS实现自己的锁? 简介 AQS的全称是AbstractQueuedSynchronizer,它的定位是为Jav ...
- 死磕 java同步系列之volatile解析
问题 (1)volatile是如何保证可见性的? (2)volatile是如何禁止重排序的? (3)volatile的实现原理? (4)volatile的缺陷? 简介 volatile可以说是Java ...
- 死磕 java同步系列之自己动手写一个锁Lock
问题 (1)自己动手写一个锁需要哪些知识? (2)自己动手写一个锁到底有多简单? (3)自己能不能写出来一个完美的锁? 简介 本篇文章的目标一是自己动手写一个锁,这个锁的功能很简单,能进行正常的加锁. ...
- 死磕 java同步系列之CyclicBarrier源码解析——有图有真相
问题 (1)CyclicBarrier是什么? (2)CyclicBarrier具有什么特性? (3)CyclicBarrier与CountDownLatch的对比? 简介 CyclicBarrier ...
- 死磕 java同步系列之Phaser源码解析
问题 (1)Phaser是什么? (2)Phaser具有哪些特性? (3)Phaser相对于CyclicBarrier和CountDownLatch的优势? 简介 Phaser,翻译为阶段,它适用于这 ...
- 死磕 java同步系列之zookeeper分布式锁
问题 (1)zookeeper如何实现分布式锁? (2)zookeeper分布式锁有哪些优点? (3)zookeeper分布式锁有哪些缺点? 简介 zooKeeper是一个分布式的,开放源码的分布式应 ...
随机推荐
- 漂亮简洁的PHP导航源码-蘑菇导航
蘑菇导航 蘑菇导航是根据SimpleWebNavigation修改而来的一个php网址导航.支持php8,支持左侧锚点,支持自定义fontawesome图标. 可以作为群组导航.图床导航.vps导航等 ...
- 第五十二篇:webpack的loader(三) -url-loader (图片的loader)
好家伙, 1.什么是base64? 图片的 base64 编码就是可以将一副图片数据编码成一串字符串,使用该字符串代替图像地址. 这样做有什么意义呢?我们知道,我们所看到的网页上的每一个图片,都是需要 ...
- 综合布线 子网掩码 IP地址 子网划分
1.1 地址协议 ipv4 :目前主流的协议 2. ipv6 :fe80::fe7:ca03:81f:2887 2 128 IANA(The Internet Assigned Numbers Aut ...
- OOM故障处理流程
一.OOM机制概述 Linux 内核有个机制叫OOM killer(Out Of Memory killer),该机制会监控那些占用内存过大,尤其是瞬间占用内存很快的进程,为防止内存耗尽而自动把该进程 ...
- KingbaseES启动数据库失败后如何分析
关键字: KingbaseES.sys_ctl.启动日志 一.KingbaseES数据库服务启动 1.1 数据库启动机制 1) 数据库通过sys_ctl工具手工启动数据库服务kingbase. 2) ...
- sedona(Geospark)读取csv
package com.grady.sedona import org.apache.sedona.sql.utils.SedonaSQLRegistrator import org.apache.s ...
- Vben Admin 源码学习:状态管理-角色权限
前言 本文将对 Vue-Vben-Admin 角色权限的状态管理进行源码解读,耐心读完,相信您一定会有所收获! 更多系列文章详见专栏 Vben Admin 项目分析&实践 . 本文涉及到角 ...
- Java学习笔记:基本输入、输出数据操作实例分析
Java学习笔记:基本输入.输出数据操作.分享给大家供大家参考,具体如下: 相关内容: 输出数据: print println printf 输入数据: Scanner 输出数据: JAVA中在屏幕中 ...
- KVM常用命令及配置文件
1.查看虚拟机配置文件 [root@KVM tmp]# ls /etc/libvirt/qemu/ damowang.xml networks [root@KVM tmp]# ls /etc/libv ...
- 如何在 Docker 之上使用 Elastic Stack 和 Kafka 可视化公共交通
文章转载自:https://blog.csdn.net/UbuntuTouch/article/details/106498568 需要掌握的知识点: 1.使用docker-compose方式部署一套 ...