随机模块random os模块 序列化模块
random:

验证码的实现:
 choice是选择列表中任意一个
choice是选择列表中任意一个
##记得把randint取出来的数字转化成str类型,要不就会相加
##cha()是把asc编码表里的数字转化成字符
 更进一步做成函数形式
更进一步做成函数形式
 ssample可在列表里面选择多个随机出现
ssample可在列表里面选择多个随机出现
os模块:#目录:当前文件上一层的文件夹
 dir = 文件夹 不加的话直接对文件使用的
dir = 文件夹 不加的话直接对文件使用的
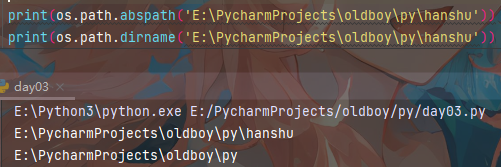
abspath:返回path规范化的绝对路径
dirname:返回path的目录##就是当前文件的上一级

绝对路径导父父父集

#os.pardir 获取当前目录的父目录字符串名:('..')
#os.walk 将文件夹的根目录(root),目录(dirs),文件(files)分开
for root,dirs,files in os.walk(文件夹的路径):
pass
#函数会自动改变`root`的值使得遍历所有的子文件夹。
#所以返回的三元元组的个数为所有子文件夹(包括子子文件夹,子子子文件夹等等)加上1(根文件夹)如何遍历\历遍文件夹,获取所有的文件信息,修改文件名\复制文件\批量移动文件
import os
base_dir = 'D:\Gold3' # 原文件存储在D盘中的Gold3文件夹下
new_dir = 'D:\Gold4\md_files'# 先新建一个文件夹,用于存放新的以.md为结尾文件
for root,dirs,files in os.walk(base_dir):
for file in files:
if file.endswitch('md'):
new_path = os.path.join(new_dir, file) # 对于符合条件的文件重命名文件名
with open(os.path.join(root,file), mode= 'rb') as f : # 读取原文件
content = f.read()
with open(new_path,mode = 'wb') as n : # 写入新文件
n.write(content)
n.flush() # 保存sys:

sys.argv:
 #命令行参数list,第一个元素时程序本身路径
#命令行参数list,第一个元素时程序本身路径
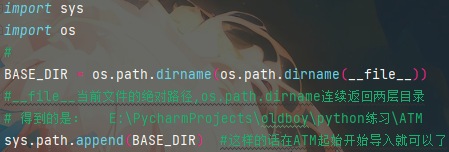 os模块和sys模块的相互应用场景
os模块和sys模块的相互应用场景
序列化模块: json模块
dumps,loads 序列化,反序列化
dump,load 配合文件使用,dump过去的是乱码只有load过来才可以
eval的应用: 不是文件中 写错了
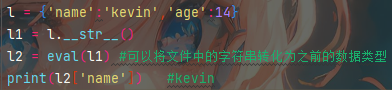
什么是序列化: 什么是反序列化:
序列: 字符串 把字符串转为其他数据类型的过程
序列化:把其他数据类型转为字符串的过程
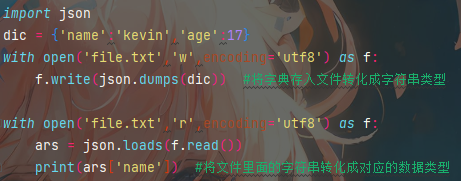 dumps转化为字符串类型
dumps转化为字符串类型
应用场景:将文件中的字符串转化为你输入进去的数据类型
pickle模块(只能应用于python语言)
 字符串转化为butes类型
字符串转化为butes类型
随机模块random os模块 序列化模块的更多相关文章
- 2019-7-18 collections,time,random,os,sys,序列化模块(json和pickle)应用
一.collections模块 1.具名元组:namedtuple(生成可以使用名字来访问元素的tuple) 表示坐标点x为1 y为2的坐标 注意:第二个参数可以传可迭代对象,也可以传字符串,但是字 ...
- collection,random,os,sys,序列化模块
一.collection 模块 python拥有一些内置的数据类型,比如 str,list.tuple.dict.set等 collection模块在这些内置的数据类型的基础上,提供了额外的数据类型: ...
- 常用模块(random,os,json,pickle,shelve)
常用模块(random,os,json,pickle,shelve) random import random print(random.random()) # 0-1之间的小数 print(rand ...
- 模块random+os+sys+json+subprocess
模块random+os+sys+json+subprocess 1. random 模块 (产生一个随机值) import random 1 # 随机小数 2 print(random.rando ...
- [xml模块、hashlib模块、subprocess模块、os与sys模块、configparser模块]
[xml模块.hashlib模块.subprocess模块.os与sys模块.configparser模块] xml模块 XML:全称 可扩展标记语言,为了能够在不同的平台间继续数据的交换,使交换的数 ...
- python time,random,os,sys,序列化模块
一.time模块 表示时间的三种方式 在Python中,通常有这三种方式来表示时间:时间戳.元组(struct_time).格式化的时间字符串: (1)时间戳(timestamp) :通常来说,时间戳 ...
- time,random,os,sys,序列化模块
一.time模块 表示时间的三种方式 在Python中,通常有这三种方式来表示时间:时间戳.元组(struct_time).格式化的时间字符串: (1)时间戳(timestamp) :通常来说,时间戳 ...
- 常用模块random,time,os,sys,序列化模块
一丶random模块 取随机数的模块 #导入random模块 import random #取随机小数: r = random.random() #取大于零且小于一之间的小数 print(r) #0. ...
- 7.18 collection time random os sys 序列化 subprocess 等模块
collection模块 namedtuple 具名元组(重要) 应用场景1 # 具名元组 # 想表示坐标点x为1 y为2 z为5的坐标 from collections import namedtu ...
- python之模块random,time,os,sys,序列化模块(json,pickle),collection
引入:什么是模块: 一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. 但其实import加载的模块分为四个通用类型. 1.使用python编写的代码(.py ...
随机推荐
- String 练习题
题目一:获取指定字符串中,大写字母.小写字母.数字的个数. 题目二:将字符串中,第一个字母转换成大写,其他字母转换成小写,并打印改变后的字符串. 题目三:查询大字符串中,出现指定小字符串的次数.如&q ...
- vs 2015 默认管理员启动
方法一: 找到 VS快捷方式 所在位置,并对其高级属性中的"用管理员身份运行"进行勾选,然后进行确定. 此方法 如果是通过sln文件的快捷方式打开的,不是管理员 方法二: 1.打开 ...
- 3html5
<label>网址:</label><input type="url" name="" required><br> ...
- resnet模型下载
resnet模型下载: model_urls = { 'resnet18': 'https://s3.amazonaws.com/pytorch/models/resnet18-5c106cde.pt ...
- 05.常用 API 第二部分
一.Object 类 是类层次结构的根 (父) 类. String toString () 返回该对象的字符串表示,其实该字符串内容就是对象的类型 + @ + 内存地址值. 由于 toString ...
- YY播放器源码解析
YY播放器使用Flutter编写的一个聚合播放器, 起因是看了 ZY-Player的源码, 发现实现挺有意思的, 也比较简单 地址: https://github.com/waifu-project/ ...
- WebPack之懒加载原理
代码结构 main.js console.log("这是main页面"); import(/* webpackChunkName: "foo" */" ...
- scrapy框架中的pipelines没有成功调用process_item方法
提示报错 原因: items没有接收到Spider的返回值,导致pipelines没有接收到items模块的返回值,检查Spider模块是否正确返回值,我这里的原因是,数据解析完成后没有yield i ...
- Asp.Net Core 程序开发技巧汇总
使用Sqlite数据库 创建项目 Asp.Net Core Web应用程序 Web应用程序 ASP.NET Core 2.2 NuGet管理,添加Sqlite数据库支持 Microsoft.Entit ...
- 解决df.to_csv 时增加重复双引号的问题
df.to_csv("test.csv", sep='|',quoting=csv.QUOTE_NONE,index=False,header=True) 转载自 df.to_cs ...